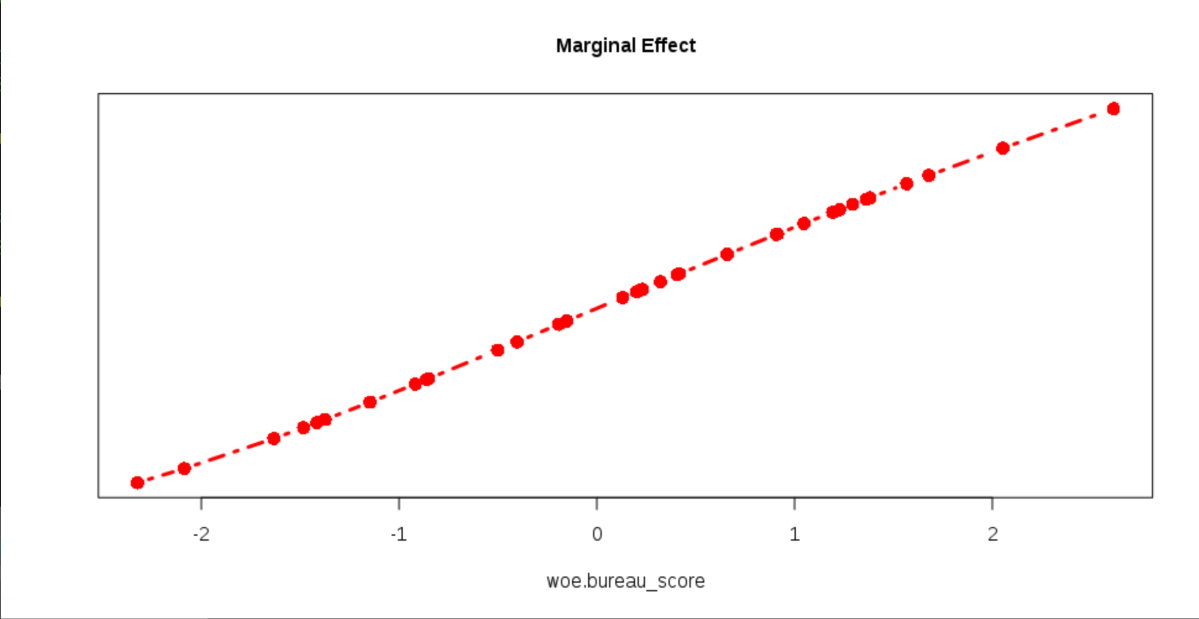
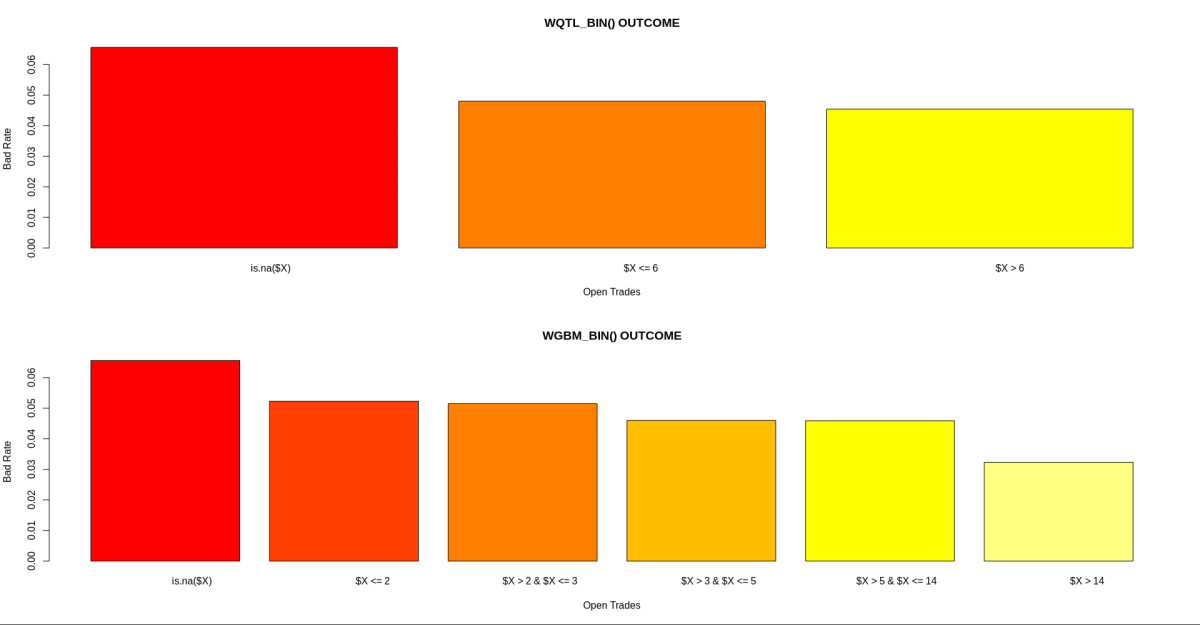
YAP: Yet Another Probabilistic Neural Network
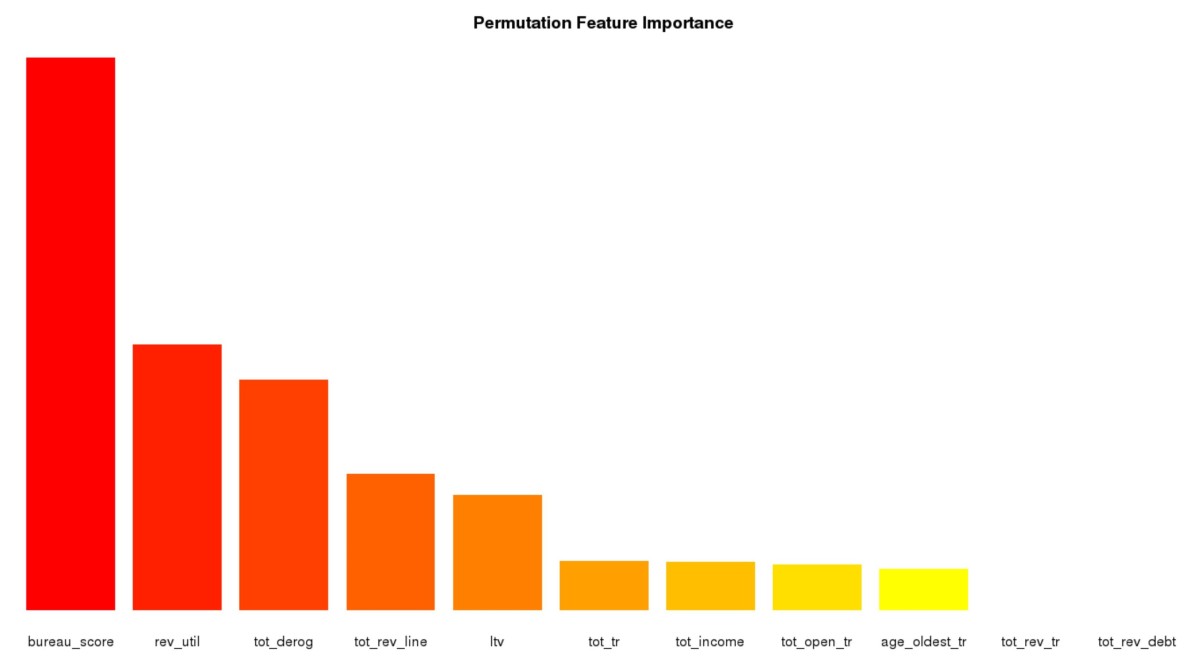
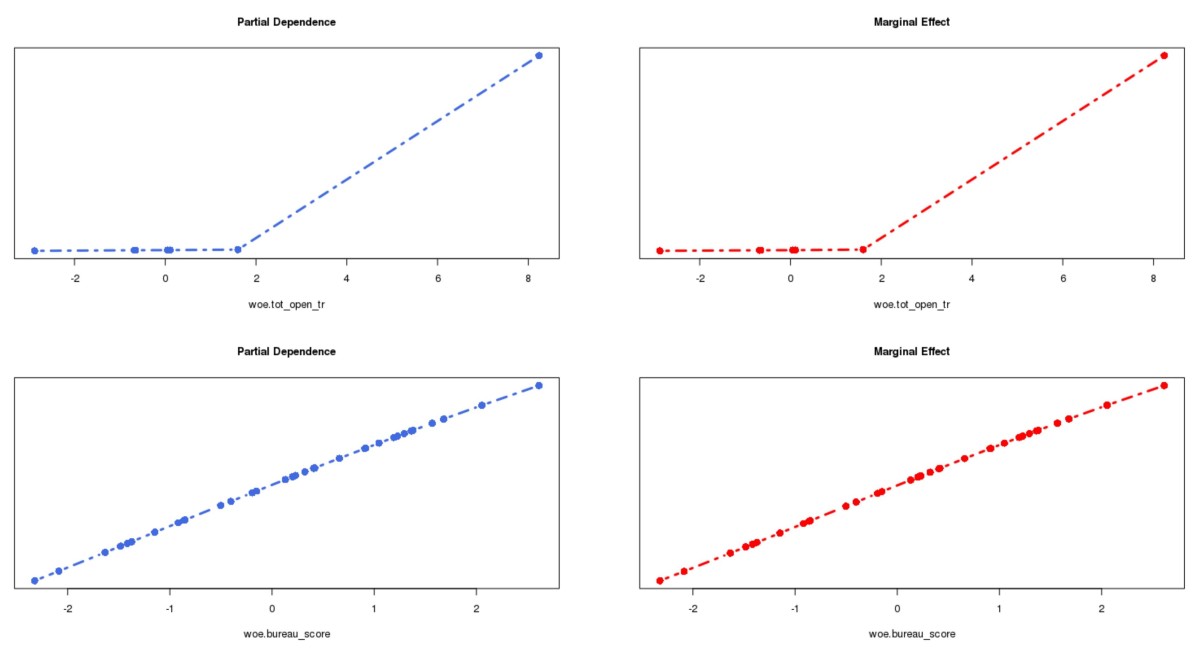
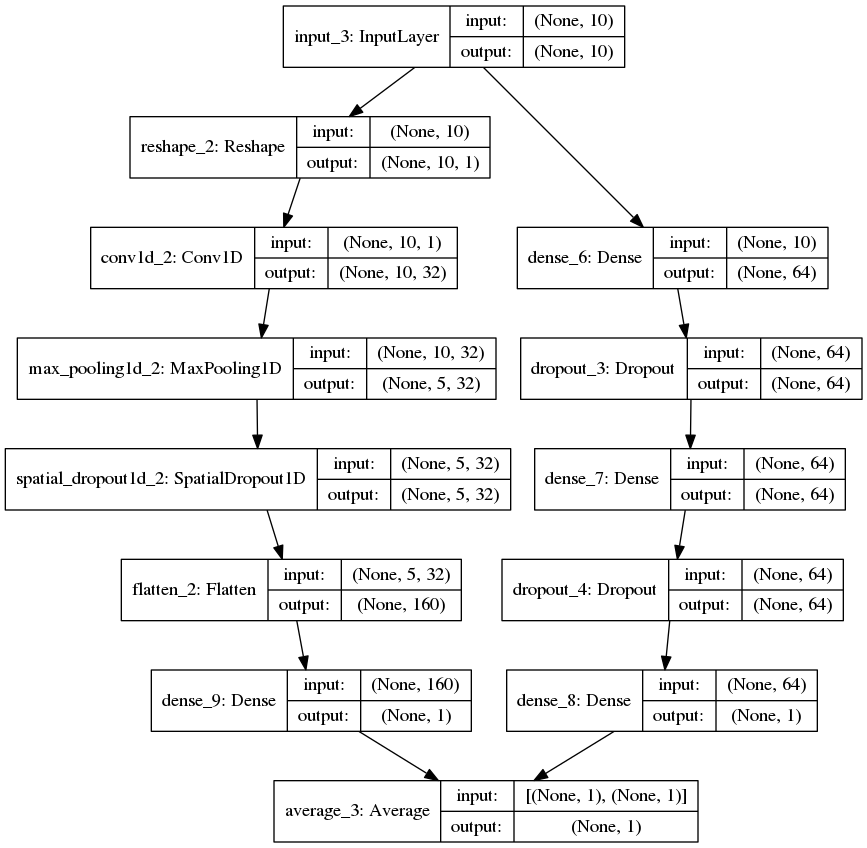
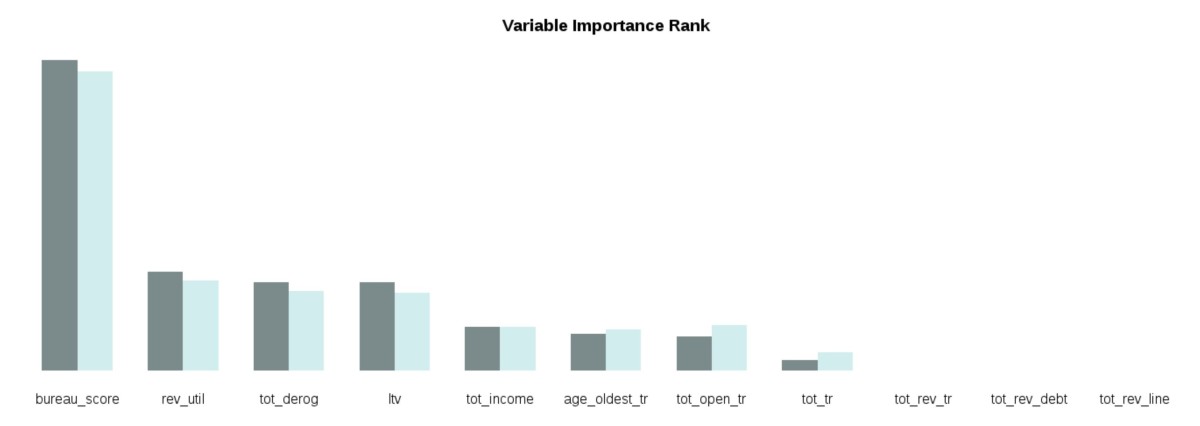
By the end of 2019, I finally managed to wrap up my third R package YAP (https://github.com/statcompute/yap) that implements the Probabilistic Neural Network (Specht, 1990) for the N-category pattern recognition with N __ 3. Similar to GRNN, PNN shares same benefits of instantaneous training, simple structure, and global convergence. Below ... [Read more...]