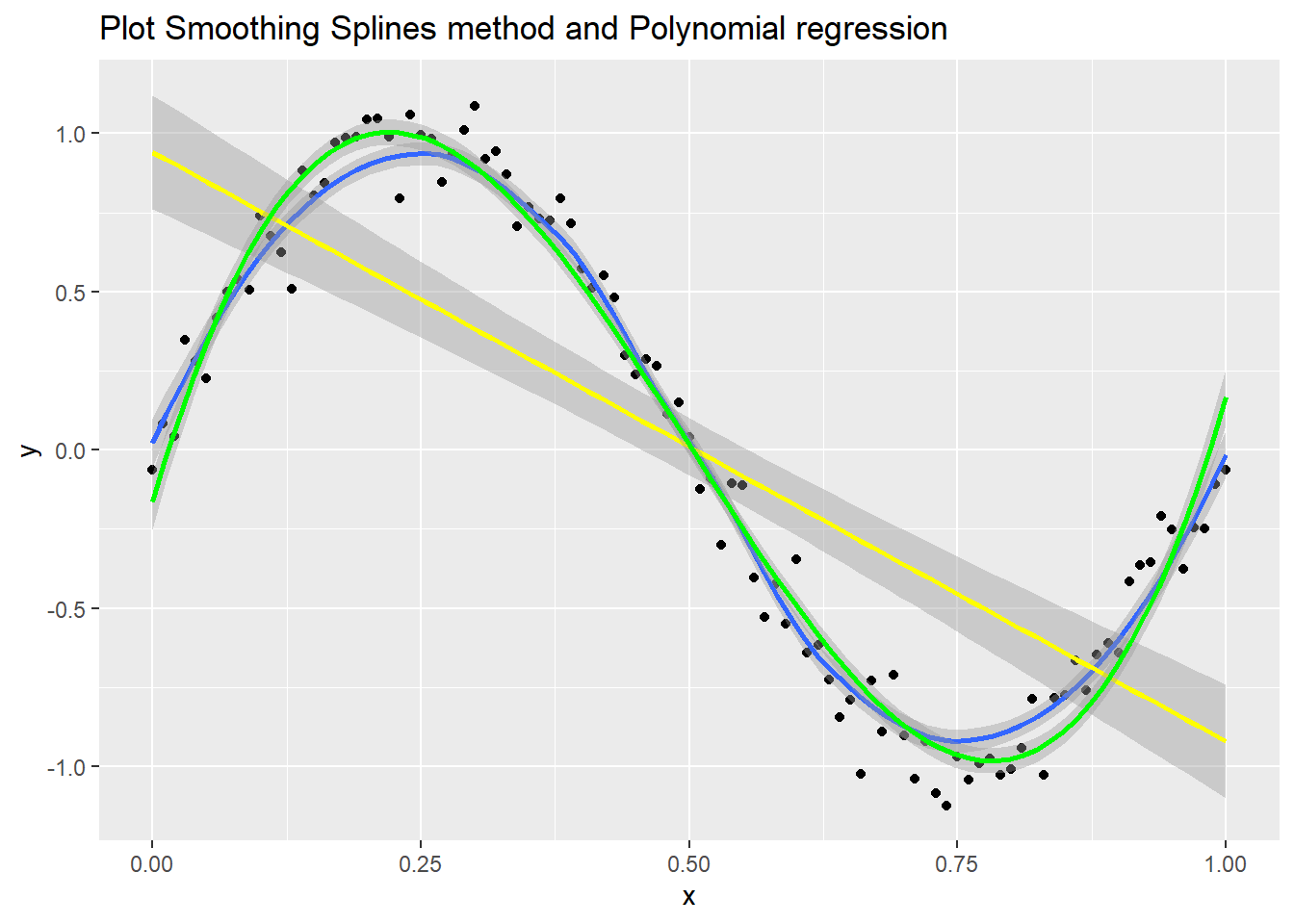
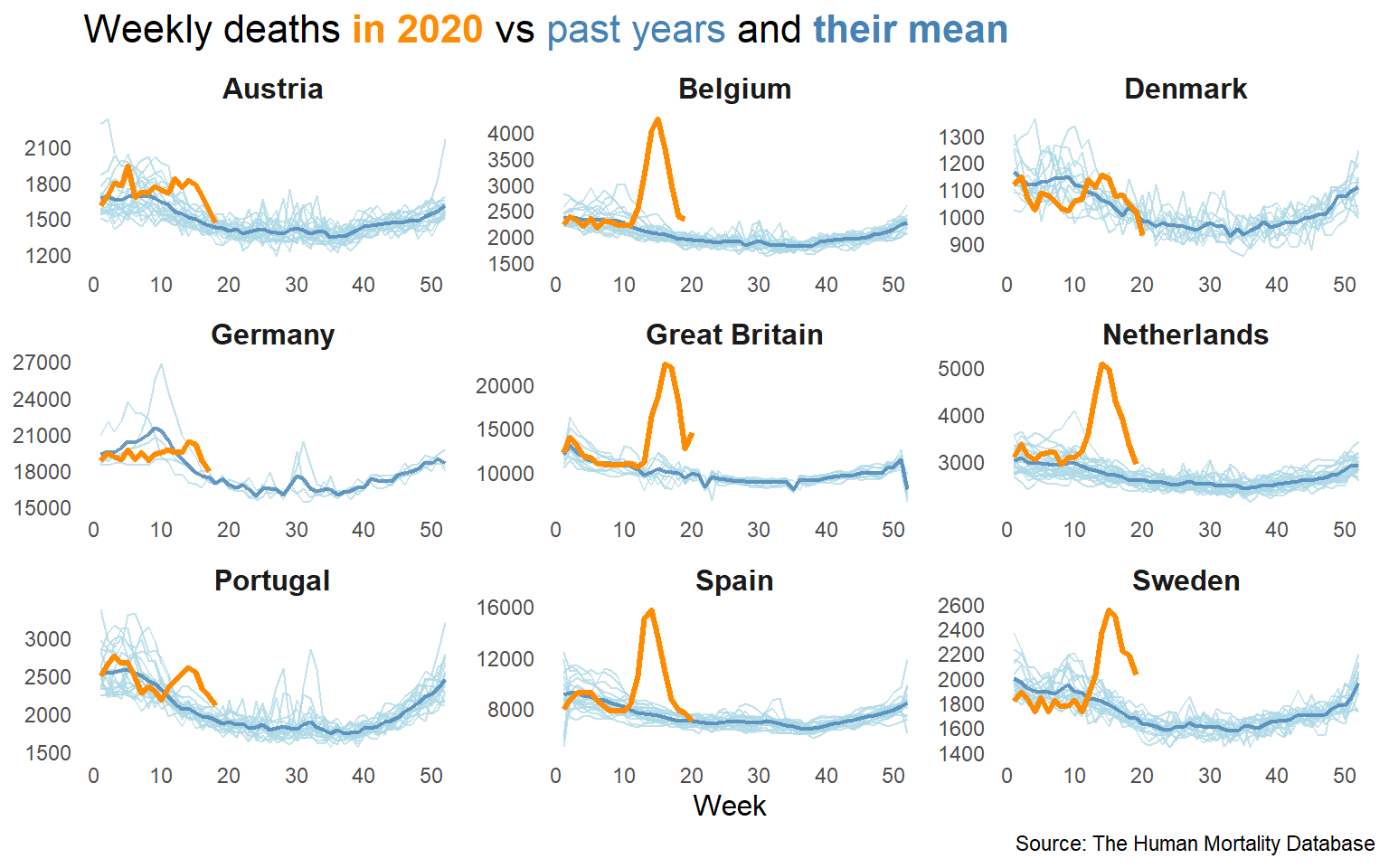
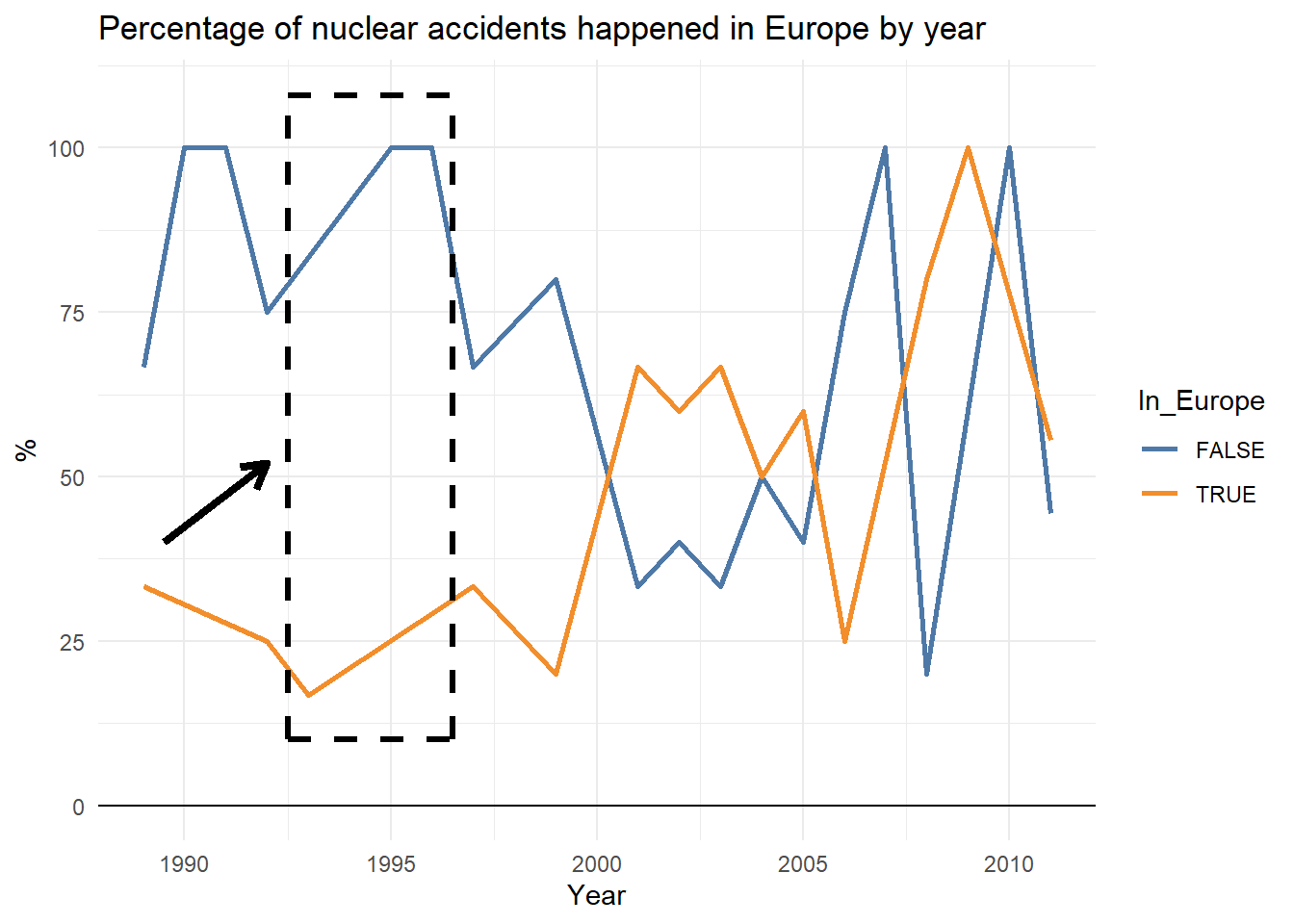
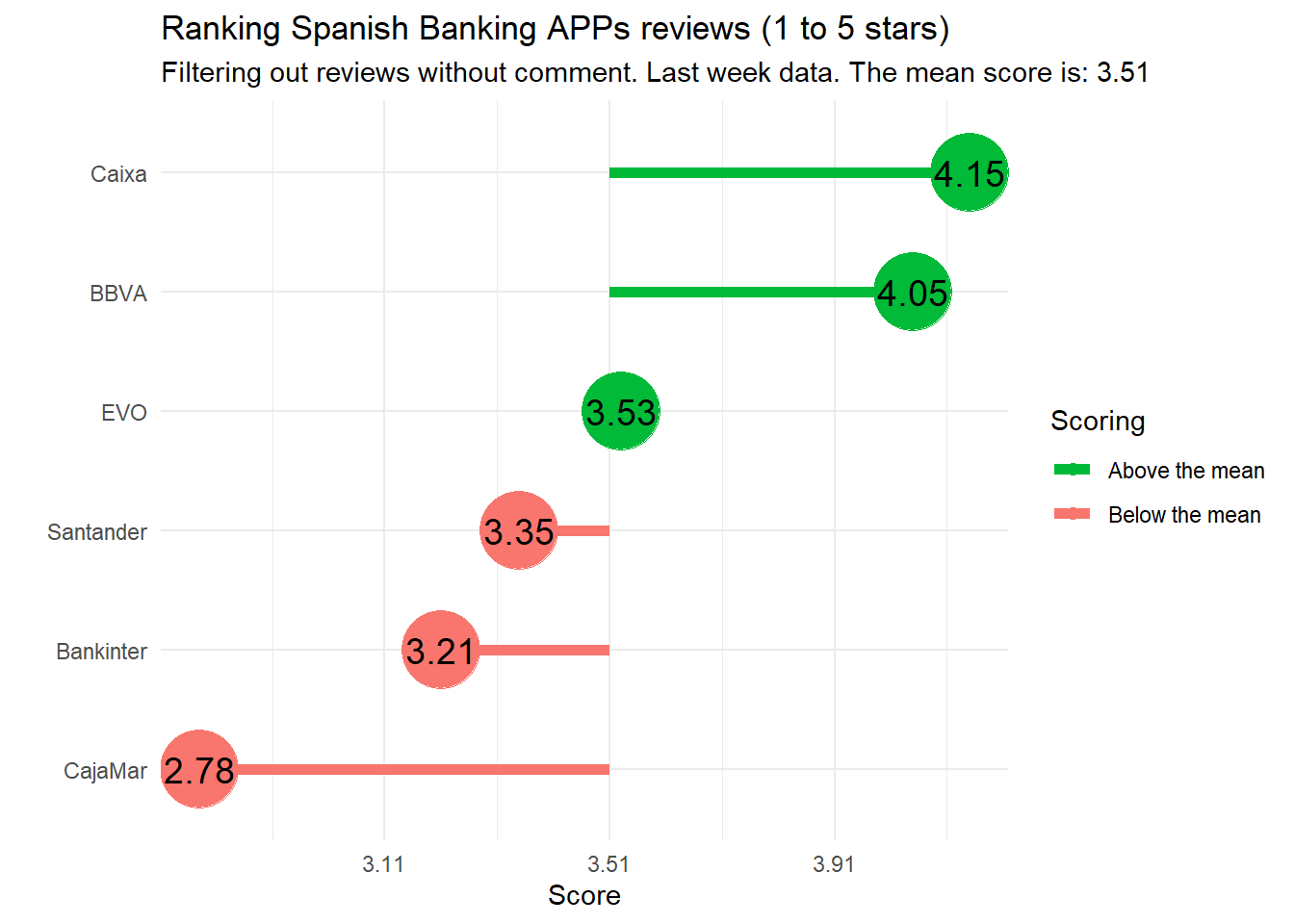
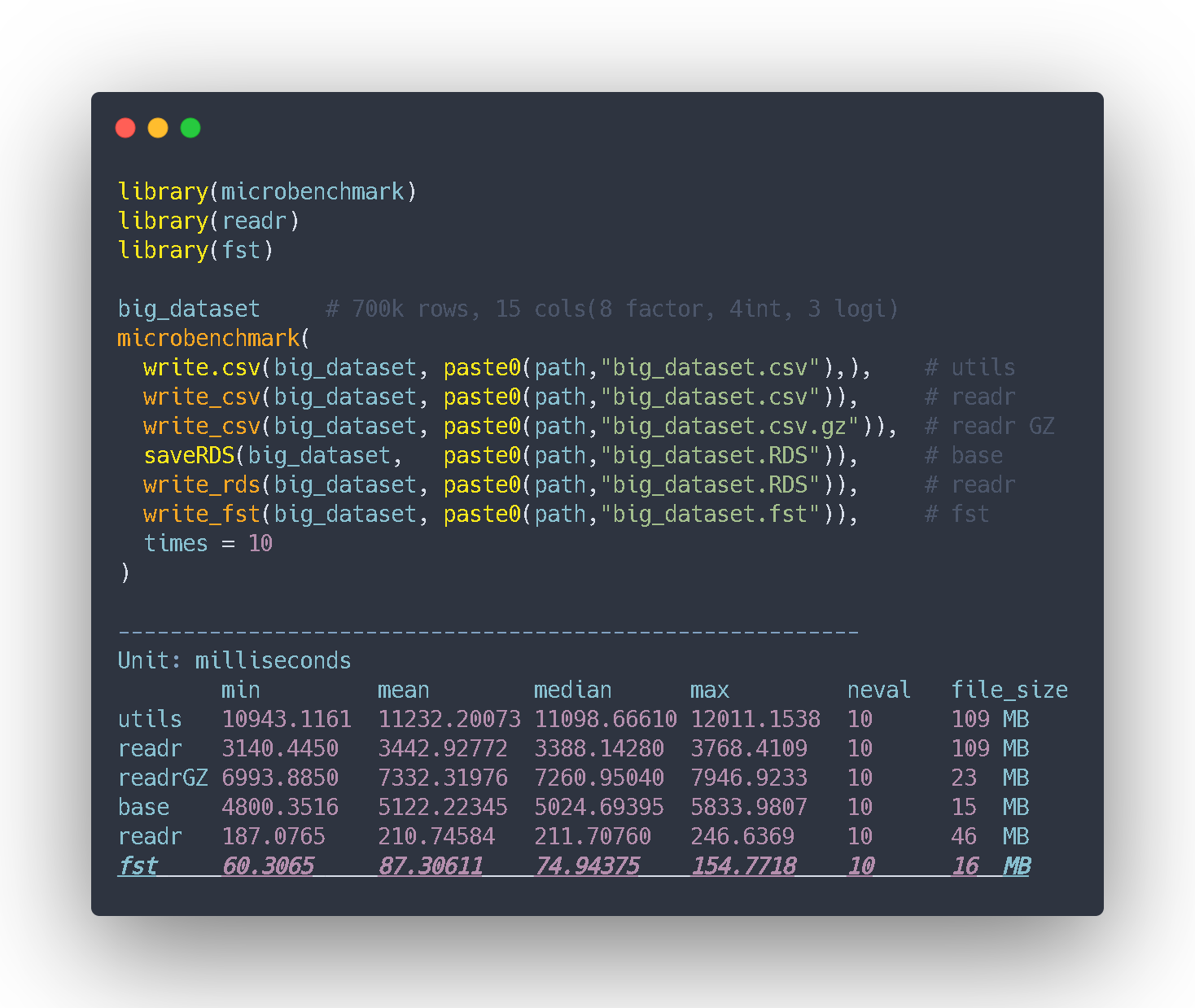
Plot_ss in R. Smoothing splines and polynomial regression plots
What is plot_ss and Smoothing Splines? Work with them in R
Smoothing splines are a method used in statistics and data analysis to create a smooth curve through a set of data points. They are particularly useful in situations where you have noisy data and want to fit a ...