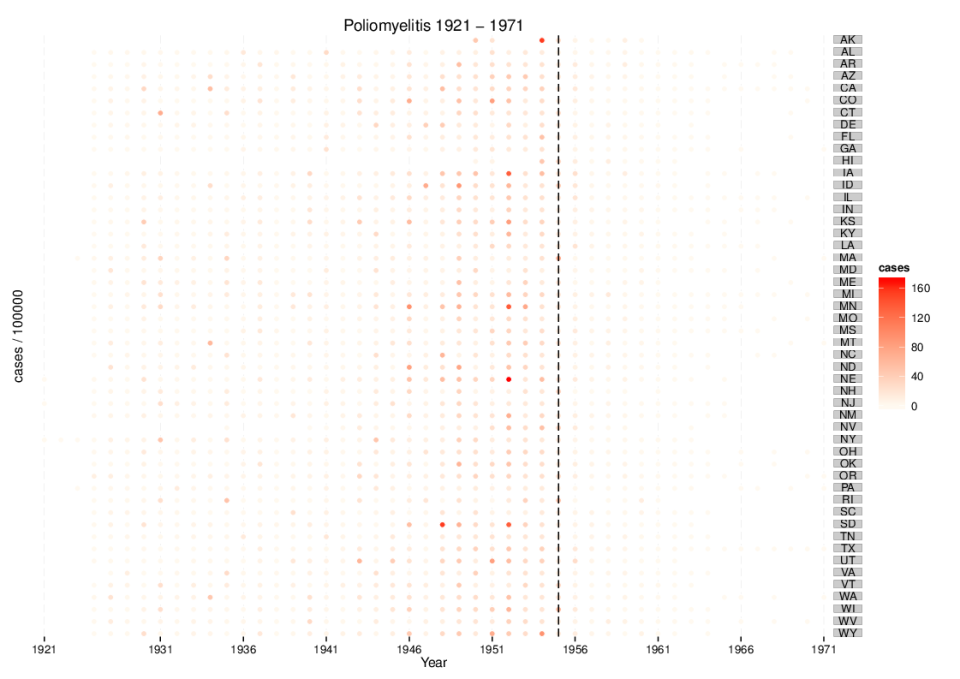
R 3.1 -> 3.2 upgrade notes
My machines upgraded from R version 3.1.3 to version 3.2.0 last week, which means that existing code suddenly cannot find packages and so fails. Some notes to myself, possibly useful to others, for what to do when this happens. Relevant to Ubuntu-based systems (I use Linux Mint). 1. Update packages 1.1. rJava issues My ... [Read more...]