Optimizing partitioning for Apache Spark database loads via JDBC for performance
Introduction
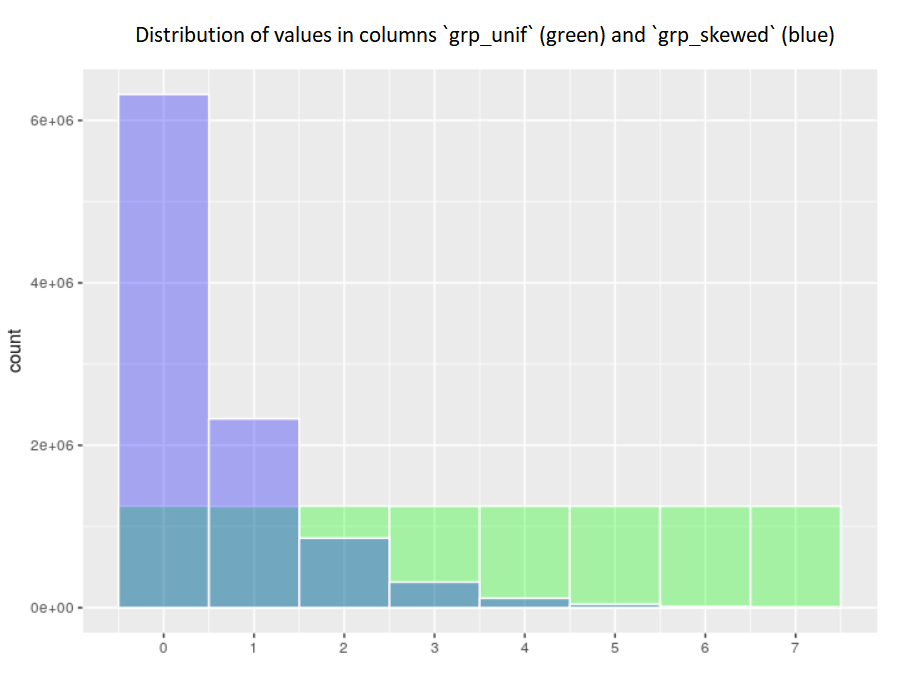
Apache Spark is a popular open-source analytics engine for big data processing and thanks to the sparklyr and SparkR packages, the power of Spark is also available to R users. A very common task in working with Spark apart from using H...