

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
It is a little-known fact that methane is more dangerous than carbon dioxide when it comes to global warming; it would harm the atmosphere about 80 times more than CO2. In this article, we will take a look at this situation across regions.
First, we examine the methane rates with a heatmap.
library(tidyverse)
library(openxlsx)
library(WDI)
library(ragg)
#Dataset for methane emissions
df_methane <-
WDI(indicator = "EN.ATM.METH.KT.CE",
extra = TRUE) %>%
as_tibble() %>%
janitor::clean_names() %>%
#removing labels attribute for fitting process
crosstable::remove_labels() %>%
drop_na() %>%
rename(methane = en_atm_meth_kt_ce)
#Dataset for heatmap
df_heatmap <-
df_methane %>%
filter(region != "Aggregates") %>%
group_by(region, year) %>%
summarise(methane_agg = mean(methane)) %>%
select(region, year, methane_agg)
#Plotting heatmap for methane emissions based on region
df_heatmap %>%
ggplot(aes(
x = year,
y = reorder(region, methane_agg),
fill = methane_agg
)) +
geom_tile(colour = "white", linewidth = 1) +
scale_fill_gradient(low = "steelblue",
high = "orange",
labels = scales::label_number(scale_cut = scales::cut_short_scale()),
name = "Methane") +
#removing the padding between heatmap tiles and the axis
scale_x_continuous(expand = c(0, 0), position = "top") +
scale_y_discrete(expand = c(0, 0)) +
labs(title = "Methane Emissions (kt of CO2 equivalent) based on Region") +
theme(text = element_text(size = 15, family = "Bricolage Grotesque"),
axis.title = element_blank(),
legend.title = element_text(size = 12, face = "bold"),
axis.ticks = element_blank(),
plot.title = element_text(size = 15,
face = "bold",
hjust = 0.5))

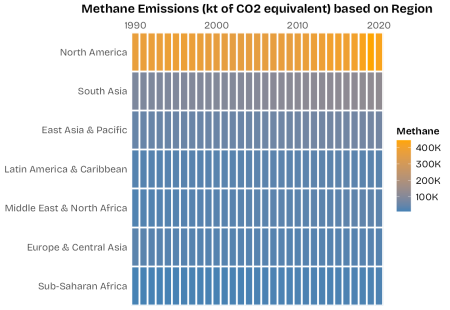

As you can see from the above chart, there is a significant difference between North America and the rest of the world. Likely, it could be related to heavy industry, considering the United States and Canada.
Now, we will be modeling the based on some variables to understand the motives behind the methane emission.
#Modeling
library(tidymodels)
#Dataset for modeling
df_mod <-
df_methane %>%
filter(region != "Aggregates",
income != "Not classified") %>%
mutate(latitude = latitude %>% as.numeric(),
longitude = longitude %>% as.numeric(),
income = income %>% as_factor(),
region = region %>% as_factor()) %>%
select(region, income, longitude,latitude, methane)
#Splitting
set.seed(12345)
df_split <- initial_split(df_mod,
prop = 0.9,
strata = "income")
df_train <- training(df_split)
df_test <- testing(df_split)
#10-fold cross validation for tuning
set.seed(12345)
df_folds <-
vfold_cv(df_train,
strata = income,
repeats = 5)
#Preprocessing
rec_norm <-
recipe(methane ~ ., data = df_train) %>%
step_normalize(all_numeric()) %>%
step_dummy(all_nominal_predictors())
#Model specifications
#Linear regression via brulee
library(brulee)
spec_brulee <-
linear_reg(penalty = tune(),
mixture = tune()) %>%
set_engine("brulee")
#Multivariate adaptive regression splines (MARS)
spec_mars <-
mars(prod_degree = tune()) %>%
set_engine("earth") %>%
set_mode("regression")
#Linear support vector machines (SVMs) via kernlab
spec_svm <-
svm_linear(cost = tune(),
margin = tune()) %>%
set_engine("kernlab") %>%
set_mode("regression")
#Radial basis function support vector machines
spec_svm_rbf <-
svm_rbf(cost = tune(),
margin = tune()) %>%
set_mode("regression") %>%
set_engine("kernlab")
#Workflow set
all_workflows <-
workflow_set(
preproc = list(normalization = rec_norm),
models = list(
SVM_RBF = spec_svm_rbf,
SVM_Linear = spec_svm,
MARS = spec_mars,
Brulee = spec_brulee
)
)
#Tuning and evaluating models
grid_ctrl <-
control_grid(
save_pred = TRUE,
parallel_over = "everything",
save_workflow = TRUE
)
grid_results <-
all_workflows %>%
workflow_map(
seed = 98765,
resamples = df_folds,
grid = 10,
control = grid_ctrl
)
#Model ranking
grid_results %>%
rank_results(select_best = TRUE,
rank_metric = "rsq") %>%
filter(.metric == "rsq") %>%
select(wflow_id, rsq = mean) %>%
mutate(wflow_id = str_remove(wflow_id,"normalization_"))
# A tibble: 4 × 2
# wflow_id rsq
# <chr> <dbl>
#1 SVM_RBF 0.668
#2 MARS 0.625
#3 Brulee 0.176
#4 SVM_Linear 0.130
#Extracting the best model
best_results <-
grid_results %>%
extract_workflow_set_result("normalization_SVM_RBF") %>%
select_best(metric = "rsq")
#Finalizing the model
model_finalized <-
grid_results %>%
extract_workflow("normalization_SVM_RBF") %>%
finalize_workflow(best_results) %>%
last_fit(df_split)
#Accuracy of the finalized model
collect_metrics(model_finalized)
# A tibble: 2 × 4
# .metric .estimator .estimate .config
# <chr> <chr> <dbl> <chr>
#1 rmse standard 0.534 Preprocessor1_Model1
#2 rsq standard 0.680 Preprocessor1_Model1
As we have chosen our model we can plot the variable importance ranking.
#Variable importance
library(DALEXtra)
#Processed data frame for variable importance calculation
imp_data <-
rec_norm %>%
prep() %>%
bake(new_data = NULL)
#Explainer object
explainer_svm_rbf <-
explain_tidymodels(
model_finalized %>% extract_fit_parsnip(),
data = imp_data %>% select(-methane),
y = imp_data$methane,
label = "",
verbose = FALSE
)
#Calculating permutation-based variable importance
set.seed(1983)
vip_svm_rbf <- model_parts(explainer_svm_rbf,
loss_function = loss_root_mean_square,
type = "difference",
B = 100,#the number of permutations
label = "")
#Variable importance plot
vip_svm_rbf %>%
mutate(variable = str_remove_all(variable, "region_|income_")) %>%
#removes (...) and replacing with 'and' instead
mutate(variable = str_replace_all(variable, "\\.{3}"," and ")) %>%
#removes (.) and replacing with blank space
mutate(variable = str_replace_all(variable, "\\.", " ")) %>%
plot() +
labs(color = "",
x = "",
y = "",
subtitle = "Higher indicates more important",
title = "Feature Importance over 100 Permutations") +
theme_minimal(base_family = "Bricolage Grotesque",
base_size = 16) +
theme(legend.position = "none",
plot.title = element_text(hjust = 0.5,
size = 14,
face = "bold"),
plot.subtitle = element_text(hjust = 0.5, size = 12),
panel.grid.minor.x = element_blank(),
panel.grid.major.y = element_blank(),
plot.background = element_rect(fill = "#F0F0F0"))
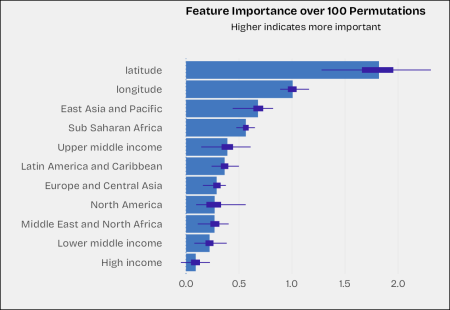
As could be extracted from the above chart, we can say that the geospatial variables are more important than the economic levels in affecting methane gas emission.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.