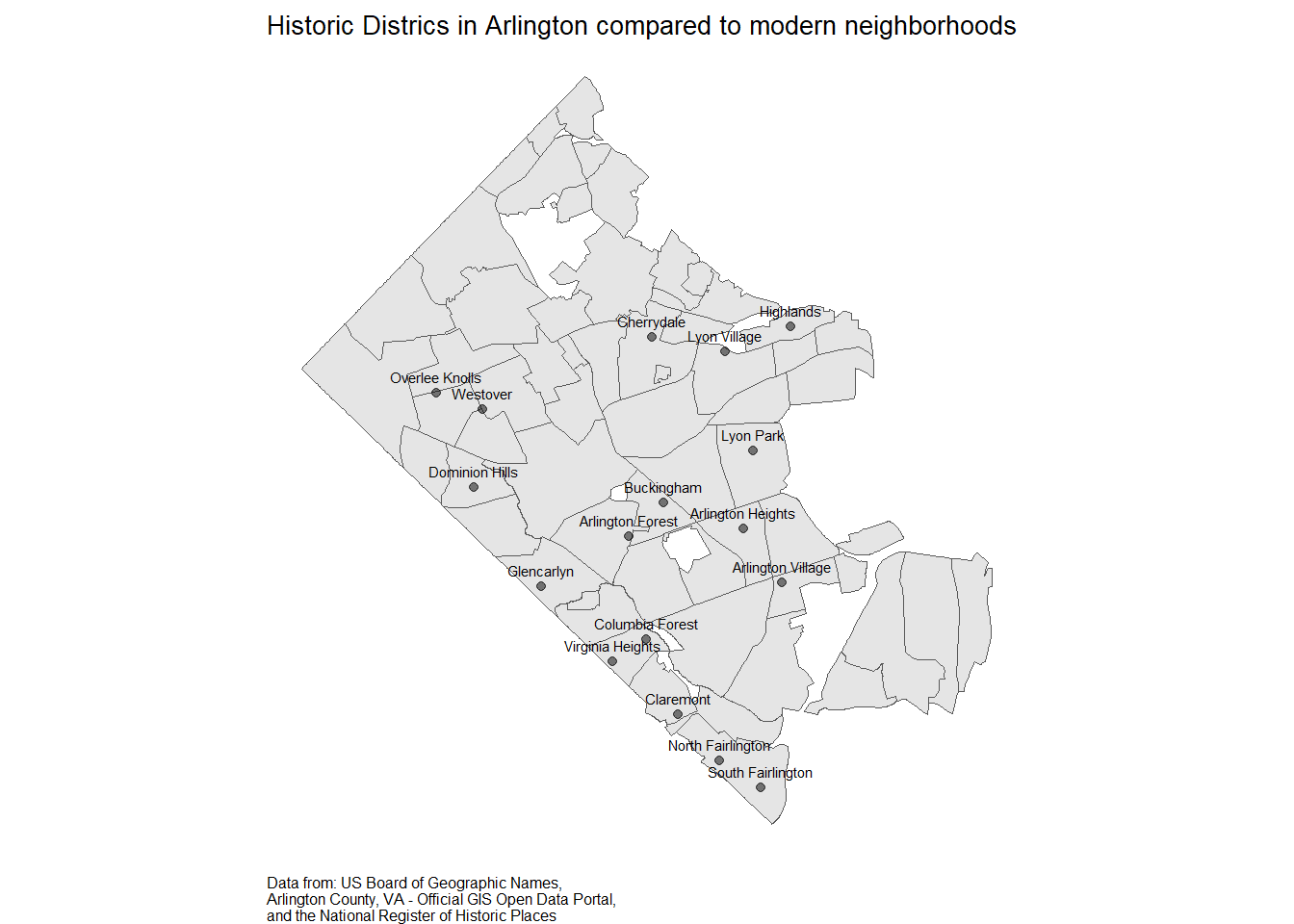
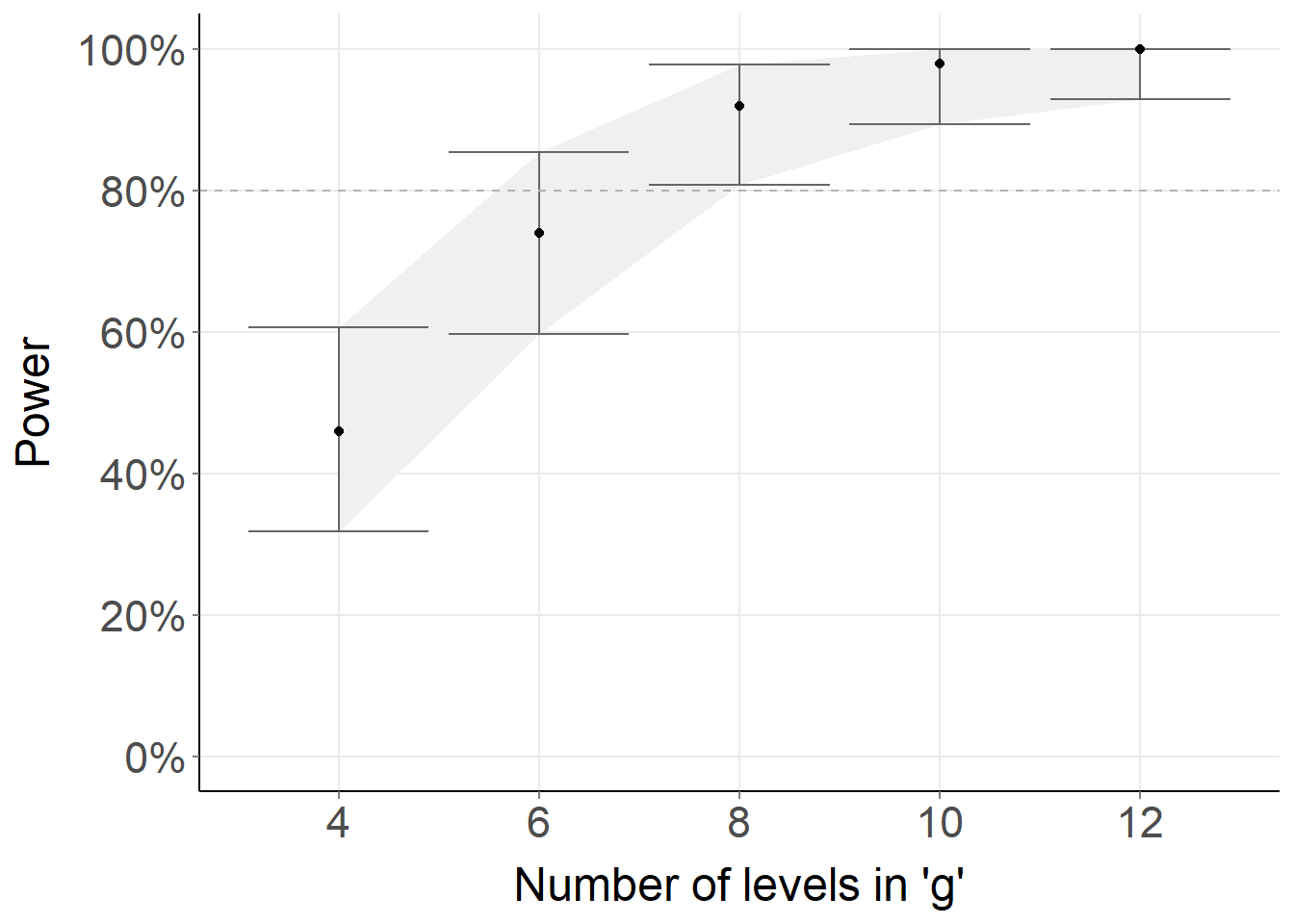
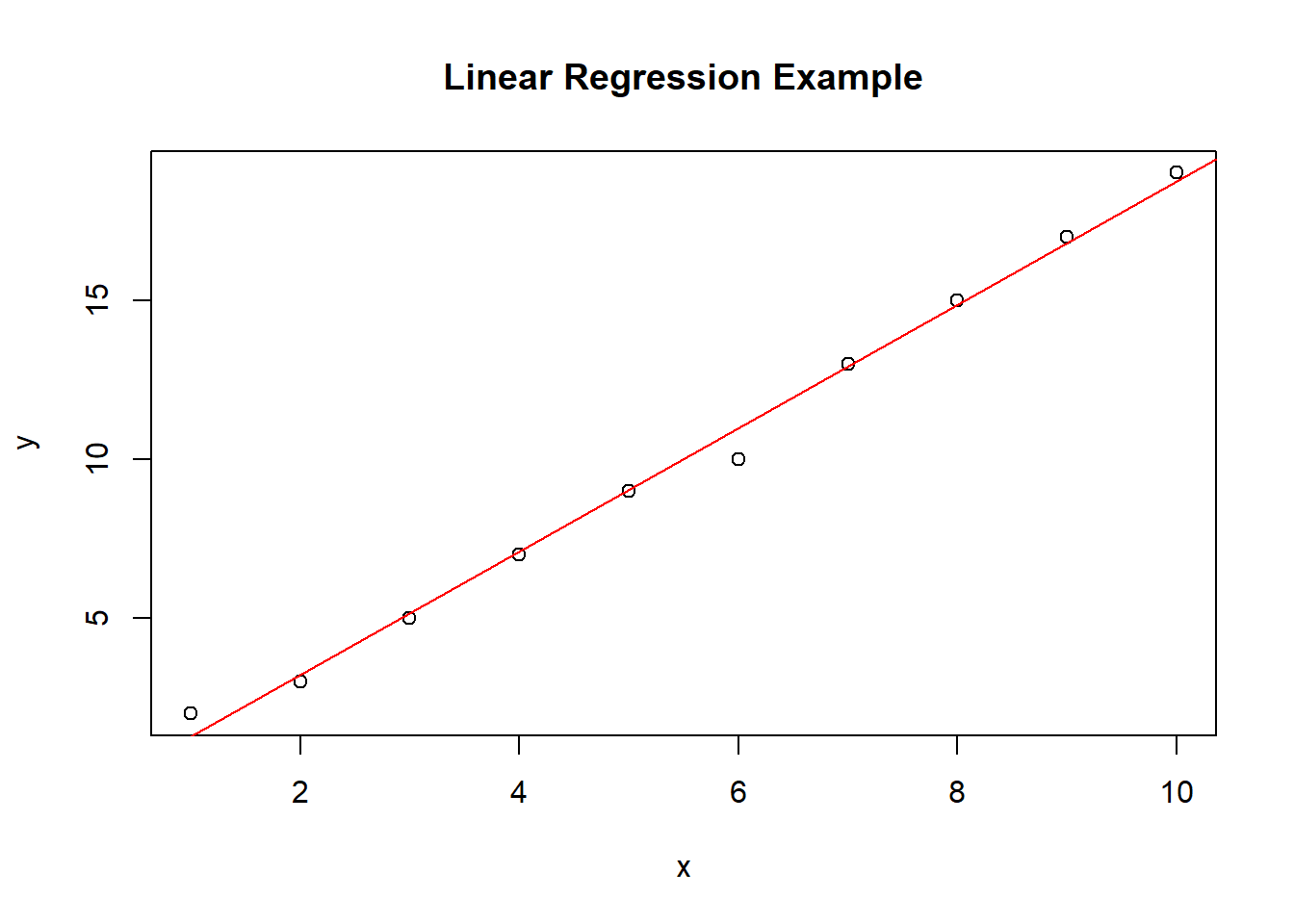
Here’s an example of fuzzy-matching strings in R that I shared on StackOverflow. In stringdist_join, the max_dist argument is used to constrain the degree of fuzziness.
library(fuzzyjoin)
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(knitr)
small_tab = data.frame(Food.Name = c('Corn', 'Squash', 'Peppers'),
Food.Code = c(NA, NA, NA))
large_tab = data.frame(Food.Name = c('Sweet Corn', 'Red Corn', 'Baby Corns',
'Squash', 'Long Squash', 'Red Pepper',
'Green Pepper', 'Red Peppers'),
Food.Code = c(532, 532, 944, 111, 123, 654, 655, 654))
joined_tab = stringdist_join(small_tab, large_tab, by = 'Food.Name',
ignore_case = TRUE, method = 'cosine',
max_dist = 0.5, distance_col = 'dist') %>%
# Tidy columns
select(Food.Name = Food.Name.x, -Food.Name.y,
Food.Code = Food.Code.y, -dist) %>%
# Only keep most frequent food code per food name
group_by(Food.Name) %>% count(Food.Name, Food.Code) %>%
slice(which.max(n)) %>% select(-n) %>%
# Order food names as in the small table
arrange(factor(Food.Name, levels = small_tab$Food.Name))
# Show table with columns renamed
joined_tab %>%
rename('Food Name' = Food.Name,
'Food Code' = Food.Code) %>%
kable()
Food Name
Food Code
Corn
532
Squash
111
Peppers
654
Created on 2023-05-31 with reprex v2.0.2
[Read more...]