

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.

Welcome to the final part of our “Unlocking the Power of Functional Programming in R” series.
In this article, we’ll explore how functional programming enhances reproducibility and testing in data analysis, particularly in industries like pharmaceutical research. We’ll also address the challenges of transitioning to functional programming in R and concerns related to performance and resource usage.
TL;DR
- This is the fourth and final part of our Unlocking the Power of Functional Programming in R series.
- Here’s Part 1: a general overview of functional programming, Part 2: key concepts and analytical benefits of functional programming in R, and Part 3: advanced techniques & practical applications.
- Functional programming, characterized by immutability and pure functions, enhances reproducibility and testing in data analysis, which is crucial in industries like pharmaceutical research.
- It promotes modular code, simplifying unit testing and property-based testing.
- While transitioning from imperative to functional coding presents challenges, starting small and learning from others can ease the process.
- Functional programming helps with addressing performance concerns with lazy evaluation and profiling ensures efficient code.
- You can use functional programming for clearer, maintainable, and reliable data analysis.
Table of Contents
- Achieving Reproducibility and Testing
- Data-Driven Industries and Pharmaceutical Research
- Challenges and Considerations
- Conclusion
Achieving Reproducibility and Testing
Reproducibility and testing are paramount in the realm of data analysis, where robust and dependable results can have profound implications. Functional programming, with its emphasis on immutability and pure functions, plays a pivotal role in enhancing reproducibility and facilitating effective testing.
In this section, we’ll explore how functional programming elevates reproducibility and discuss strategies for rigorous testing, especially in data-driven industries like pharmaceuticals.


Enhancing Reproducibility
Immutability
Functional programming encourages immutability, meaning once data is created, it remains unchanged. This inherent immutability reduces the risk of accidental alterations in data or code, a common source of reproducibility issues.
Example in R:
# Immutable data using `dplyr` library(dplyr) data <- mtcars filtered_data <- data %>% filter(cyl == 6)
Pure Functions
Functional code relies on pure functions, which produce the same output for the same input, free of side effects. This property ensures that the results of computations remain consistent across runs.
Example in R:
# Pure function in R
square <- function(x) {
return(x^2)
}
result <- square(4) # Result is always 16
In this example, the calculate_mean() function is a pure function. It always produces the same output for the same input, making it predictable and reproducible.
Functional programming also encourages modular code design, where you break down your analysis into small, reusable functions. This modularity simplifies the verification and validation of individual components.
Rigorous Testing
Unit Testing
Functional programming simplifies unit testing by breaking down code into small, testable functions. These units can be tested independently, ensuring that each component of the analysis works correctly.
Example in R:
# Unit testing with 'testthat'
library(testthat)
test_that("Square function returns correct results", {
expect_equal(square(4), 16)
expect_equal(square(0), 0)
})
Property-Based Testing
Property-based testing, where code is tested against a set of properties, is particularly effective in functional programming. It verifies that functions adhere to specified properties, enhancing confidence in the code’s correctness.
Example in R:
# Property-based testing with 'fuzzr'
library(fuzzr)
fuzz(function(x) {
prop_square_positive(x) <- x >= 0
}, seed = 42)
Discover the impact of open-source applications in the pharmaceutical sector. Explore our ‘How Open Source (R and Shiny) Is Transforming Processes in the Pharmaceutical Industry‘ to learn how it’s revolutionizing the industry.
Data-Driven Industries and Pharmaceutical Research
In data-driven industries like pharmaceuticals, the importance of reproducibility and testing cannot be overstated. Reliable analyses are essential for making critical decisions related to drug development, clinical trials, and patient well-being. Functional programming, with its rigorous approach to data manipulation and testing, aligns perfectly with the stringent requirements of these industries.
Ensuring reproducibility in pharmaceutical research involves not only code but also data management and documentation. Functional programming methodologies, such as functional pipelines, can be applied to data preprocessing, analysis, and reporting, making the entire workflow more transparent and reproducible.

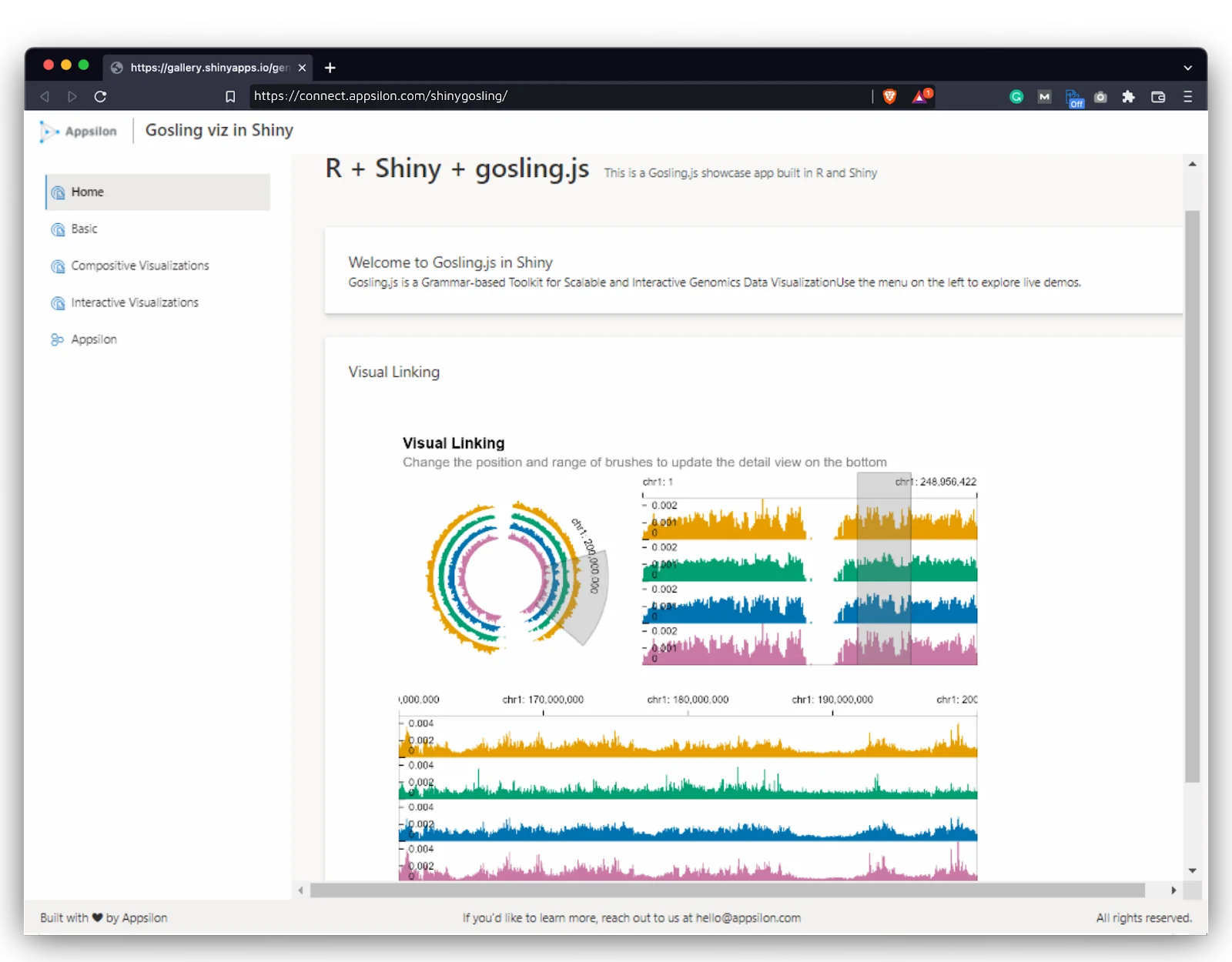
Interactive Application for Genomics with {shiny.gosling} & R
In essence, functional programming is a valuable ally in the pursuit of reproducibility and testing excellence in data analysis, particularly in industries where the stakes are high.
By embracing immutability, pure functions, and systematic testing practices, data professionals can enhance the reliability and trustworthiness of their analyses, providing a solid foundation for data-driven decision-making in critical fields like pharmaceuticals.
Challenges and Considerations
Functional programming has gained popularity in recent years for its elegant and concise coding style, as well as its potential for improving code maintainability and readability. However, transitioning from imperative to functional programming in R can present its own set of challenges and considerations.
In this section, we’ll acknowledge these challenges, offer tips for a smooth transition, and address concerns about performance and resource usage.
Challenges
Paradigm Shift
One of the most significant challenges when adopting functional programming in R is the paradigm shift it requires. Traditional imperative programming emphasizes mutable state and explicit loops. In contrast, R’s functional programming relies on immutability and higher-order functions. This change in mindset can be a stumbling block for many developers.

lapply, sapply, and purrr package functions, which make it easier to work with functional constructs in R.

# Using lapply for a simple transformation data <- list(1, 2, 3, 4, 5) result <- lapply(data, function(x) x * 2)
Performance Concerns
Functional programming can sometimes be perceived as slower than imperative code due to the creation of new objects and increased memory usage. While this is a valid concern, modern R packages have made efforts to mitigate this problem.
For example, R supports lazy evaluation so we can execute computation only when it is needed. Profiling packages like {profvis} can help in determining bottlenecks and memory usage which helps in optimizing performance.
profvis and microbenchmark can help you measure and optimize code execution.
# Profiling code execution with profvis
library(profvis)
profvis({
# Your code here
})
Transitioning from Imperative to Functional Coding
Start Small
To ease the transition, start by rewriting small sections of your codebase in a functional style. This gradual approach allows you to become comfortable with functional programming concepts without overwhelming yourself.
filter, map, and reduce.
# Using dplyr for data filtering library(dplyr) filtered_data <- data %>% filter(value > 3)
Learn from Others
Study functional R code written by experienced developers. Open-source R packages, GitHub repositories, and online communities are great places to find well-structured functional code examples. Learning from others’ code can provide valuable insights into best practices.
Addressing Concerns about Performance and Resource Usage
Lazy Evaluation
R employs lazy evaluation, which means that expressions are not evaluated until their results are actually needed. This can help mitigate some performance concerns, as only the necessary computations are performed when required.
lazyeval::lazy() to delay the execution of code until necessary.
# Using lazy evaluation to defer computation
library(lazyeval)
lazy_result <- lazy({
# Expensive computation here
})
Profiling and Benchmarking
As mentioned earlier, use profiling and benchmarking tools to identify performance bottlenecks and areas for improvement. Regularly optimizing your functional code can help ensure it performs efficiently.
Remember that the perceived performance impact of functional programming in R largely depends on the specific use case and the efficiency of your code implementation. By understanding these challenges and employing best practices, you can harness the power of functional programming to write cleaner, more maintainable, and potentially more performant R code.
Conclusion
Functional programming is a game-changer in data analysis, particularly in pharmaceutical research. It enhances reproducibility through immutability and pure functions, while modular code design simplifies rigorous testing. Data-driven industries can benefit greatly from these methodologies.
Ready to elevate your data analysis? Embrace functional programming for robust, reproducible, and trustworthy outcomes. Start small, explore open-source resources, and optimize performance using R’s tools.
Dive into our eBook on Functional Programming in R to kickstart your journey.


The post appeared first on appsilon.com/blog/.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.