
Advent of 2023, Day 4 – Delta lake and delta tables in Microsoft Fabric
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
In this Microsoft Fabric series:
- Dec 01: What is Microsoft Fabric?
- Dec 02: Getting started with Microsoft Fabric
- Dec 03: What is lakehouse in Fabric?
Yesterday we looked into lakehouse and learned that Delta tables are the storing format. So, let’s explore what and how we can go around understanding and working with delta tables. But first we must understand delta lake.
Delta Lake is an open-source storage framework that enables building the lakehouse data layers. With Spark-based data lake processing, it adds the relational database framework to data lake processing.
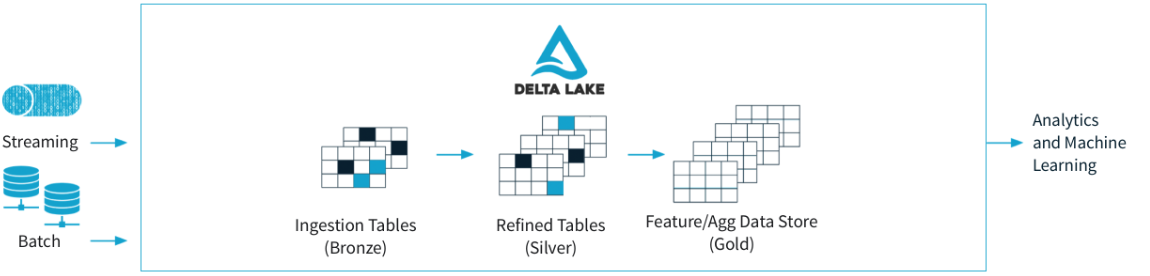
Delta Lake brings so many outstanding and needed features to end users in Microsoft Fabric. Just to name a few: bringing ACID transactions (great serializability, strongest level of isolation(s)), time travel to revert to earlier states of data, scalable metadata to handle petabyte-scale tables, efficient DML operations (with interoperable APIs), history auditing and many more.
Based on this layer, delta tables in Microsoft Fabric, are created (signified by the triangular Delta (▴) icon on tables in the lakehouse user interface). Delta tables are schema abstractions over data files, that are stored in Delta format. For each table, the lakehouse stores a folder containing Parquet data files and a _delta_Log folder in which transaction details are logged in JSON format.
Create a delta table
In the same lakehouse, we have created in previous blogpost, we will create a new notebook.
But before we start writing any Spark code, let’s upload a sample file (iris.csv) that is available my github repository.

In the dialog window select the file from your preferred location and upload it
And the file will be available in the lakehouse explorer under files:
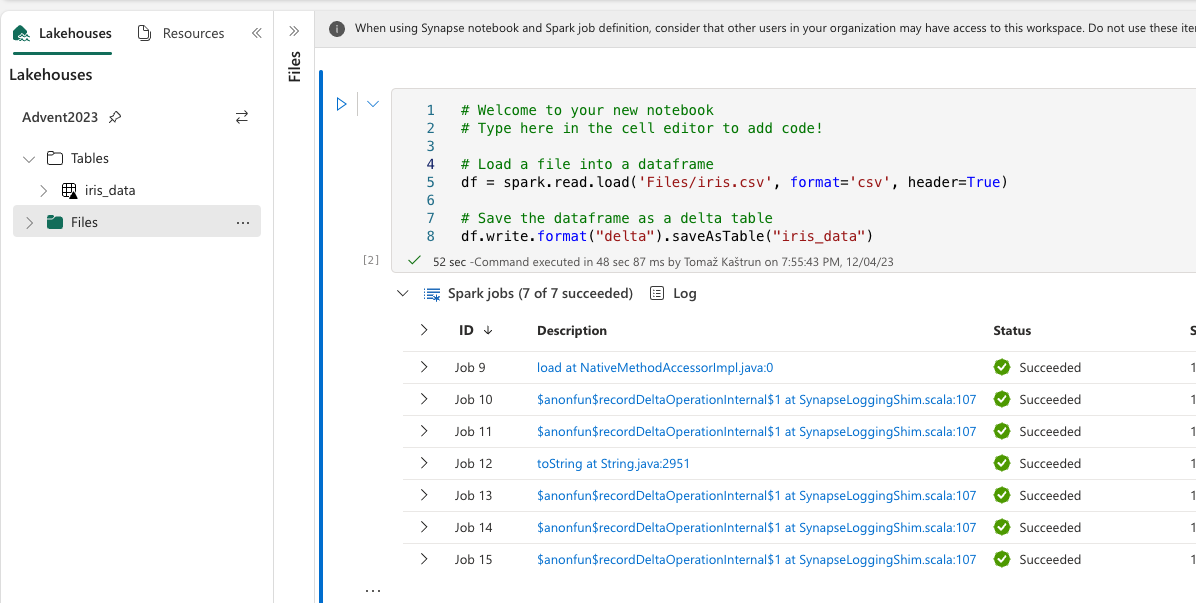
Let’s go back to notebook, we created earlier and run the following PySpark code:
# Welcome to your new notebook
# Type here in the cell editor to add code!
# Load a file into a dataframe
df = spark.read.load('Files/iris.csv', format='csv', header=True)
# Save the dataframe as a delta table
df.write.format("delta").saveAsTable("iris_data")
And congratulations, we have created a first delta table (table is signified with triangle code)
Data can be introduced to Delta lake in so many ways, this one is – for the sake of demo – the easiest to replicate. We can introduce the external files (abfss://..) or get data through API.
With delta table now available, we can choose the language of choice and drill the data. How about using Spark SQL.
%%sql SELECT 'Sepal.Length' ,'Sepal.Width' ,Species FROM iris_data WHERE Species = "setosa" LIMIT 5;
Or using R:
%%sparkr library(SparkR) deltaDataframe <- read.df(path = "abfss://[email protected]/{yourGUID}/Tables/iris_data", source = "delta")
Or Python:
from delta.tables import * from pyspark.sql.functions import * # Create a DeltaTable object delta_path = "abfss://[email protected]/{yourGUID}/Tables/iris_data" deltaTable = DeltaTable.forPath(spark, delta_path)
Tomorrow we will look continue exploring the delta tables and it’s great features!
Complete set of code, documents, notebooks, and all of the materials will be available at the Github repository: https://github.com/tomaztk/Microsoft-Fabric
Happy Advent of 2023! ![]()
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.