

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.


If there’s one type of data no company has a shortage of, it has to be time series data. Yet, many beginner and intermediate R developers struggle to grasp their heads around basic R time series concepts, such as manipulating datetime values, visualizing time data over time, and handling missing date values.
Lucky for you, that will all be a thing of the past in a couple of minutes. This article brings you the basic introduction to the world of R time series analysis. We’ll cover many concepts, from key characteristics of time series datasets, loading such data in R, visualizing it, and even doing some basic operations such as smoothing the curve and visualizing a trendline.
We have a lot of work to do, so let’s jump straight in!
Looking to start a career as an R/Shiny Developer? We have an ultimate guide for landing your first job in the industry.
Table of contents:
- Key Characteristics of Time Series Datasets
- Loading an R Time Series Dataset
- Manipulating Datetime Values of a R Time Series Dataset
- Visualizing R Time Series Datasets
- Handling Missing Dates and Values
- Basic Time Series Operations: Data Smoothing and Trendlines
- Summing up R Time Series Analysis
Key Characteristics of Time Series Datasets
Time series datasets are always characterized by at least two features – a time period and a floating point value. They both represent an event, such as Microsoft stock value at November 16th, 2023 at 3 PM.
That’s essentially the basics, but this section will dive into the core characteristics of time series datasets, and provide you with a foundational understanding of their nature and behaviour. By recognizing these, you will be able to more effectively interpret, analyze, and make predictions based on time series data.
Here’s the list of all key characteristics you need to know:
- Datetime information – In all-time series datasets, one or more columns are dedicated to show datetime information. You could have the date and time stored in separate columns, or you can have them combined as a single feature. This column(s) serves as an index, marking the exact time at which each observation was recorded.
- Measurement of variable(s) over time – Time series datasets usually measure one or more variables over time, e.g., the before-mentioned Microsoft stock price. The key aspect to remember is that these measurements are taken at regular intervals, be it hourly, daily, monthly, or yearly. It’s this regularity that allows you to spot patterns, fluctuations, and general changes over time.
- Seasonality – Seasonality refers to the occurrence of regular and predictable patterns or cycles in a time series dataset over specific intervals. These patterns are often tied to time-related variables like days of the week, months, or quarters. For example, airplane tickets are always in demand, particularly in the summer months when people go on vacations.
- Trend – A trend in time series data is observed when there’s a long-term increase or decrease in the data. It doesn’t have to be linear; trends can take various forms, such as exponential or logarithmic, so keep that in mind. For example, a company might see a gradual increase in sales over several years, indicating a positive trend. On the other hand, the exact opposite can happen, indicating a downward trend in sales.
If you understand these key characteristics, you’ll be one step closer to gaining valuable insights from time series datasets. This will allow you and your business to understand your data and make accurate predictions and informed decisions.
But, how do you actually load a time series dataset in R? Let’s explore that in the following section.
Loading an R Time Series Dataset
In a nutshell, time series datasets are not different from other types of datasets you’re used to. They’re also typically stored in CSV/Excel files or in databases, which means you can use your existing R knowledge to load these files into memory.
The dataset of choice for today will be Airline passengers, showing the number of passengers in thousands from 1949 to 1960, at monthly intervals.
Assuming you have the dataset downloaded, here’s the R code you can use to load it:
data <- read.csv("airline-passengers.csv")
The dataset is now in memory, which means you can use the convenient head() function to display the first couple of rows. Let’s go with 12 since the dataset shows monthly totals:
head(data, 12)
This is what you’ll see printed out:

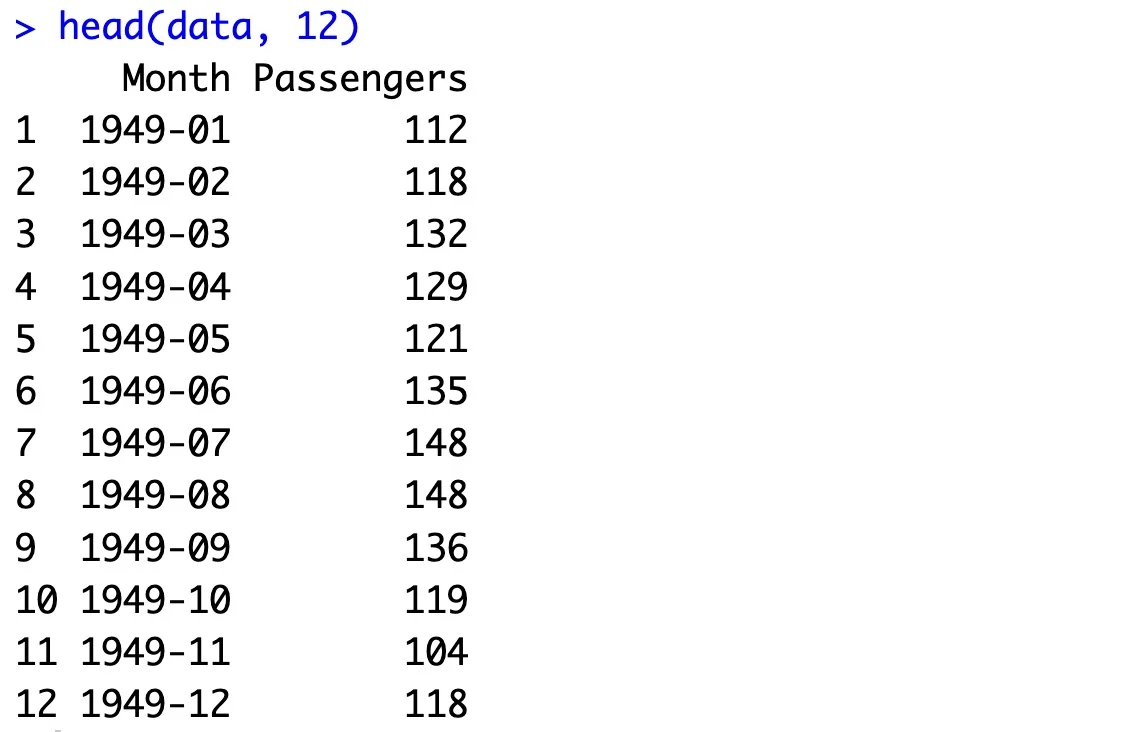
Image 1 – Loading a time series dataset
What makes Airline passengers a time series dataset is the fact that it has a time-related column on regular intervals, and also has a numeric value attached to every time interval. These are the basic two premises described in the previous section.
As for trend and seasonality, we’ll explore these later in the visualization section.
Manipulating Datetime Values of a R Time Series Dataset
You’ve probably spotted that the date column isn’t formatted correctly in the previous section. The current values are in the form of “year-month”. Adding insult to injury, it also looks like the column has a character data type:


Image 2 – Column data types
This section will show you how to fix the data type, and also how to convert the date in the format of month end, just in case you don’t like the default month start format.
We’ll use the lubridate package through this section, so make sure you have it installed.
Convert String to Datetime
The lubridate package ships with a ym() function which converts a string date representation in the format of “year-month” to a proper date object.
You don’t have to apply this function to each row manually – you can pass the entire column instead:
library(lubridate) data$date <- ym(data$Month) head(data)
This is what the dataset looks like now:


Image 3 – Dataset after adding the datetime column
If you check the data types with str() again, you’ll see the following:


Image 4 – Column data types
Which means we now have a proper date column at our disposal.
Change the Date Formatting
The next thing you might want to do is to change how the date column is formatted. Maybe you prefer to see the last day of the month instead of the first – the change is really easy to implement:
data$date_mth_end <- ceiling_date(data$date, "month") - days(1) head(data)
This is what you will see:

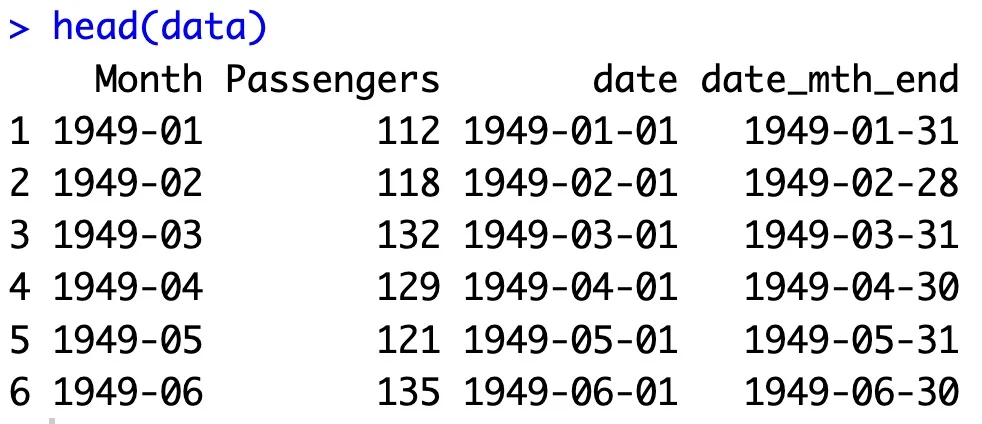
Image 5 – Changing the date format
There are many ways you can format the date column. In the end, it’s just personal preference – R won’t treat it any differently behind the scenes.
We now have some proper data to visualize. Let’s explore how in the following section.
Visualizing R Time Series Datasets
We humans aren’t the best at spotting patterns from tabular data. But it’s a whole different story when the same data is visualized. This section will show you how to make a basic time series data visualization with ggplot2, and also how to make it somewhat aesthetically pleasing.
Before creating the chart, you should make sure your datetime column is a Date object, and not just a string representation of it. Also, make sure the count column is numeric, and not just a number wrapped by quotes.
Lucky for you – both conditions are met if you’ve followed through the previous section!
Time series data is often visualized as a line chart. It makes sense since data is continuous and sampled on identical intervals. Here’s the code you’ll need to make the most basic line chart with ggplot2:
library(ggplot2) ggplot(data, aes(x = date, y = Passengers)) + geom_line()
This is what the chart looks like:

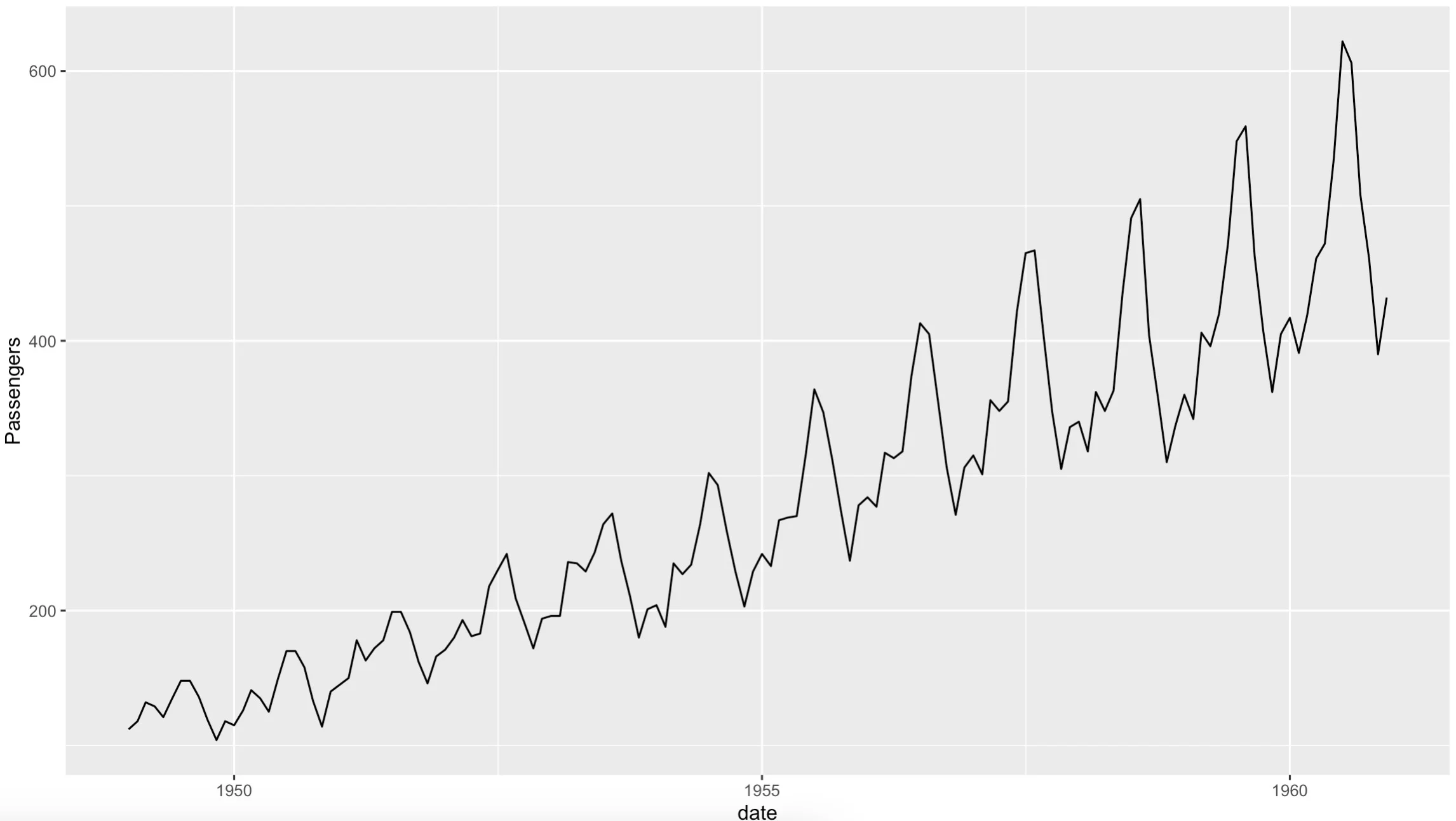
Image 6 – Basic line chart
It’s not the prettiest, but it gets the job done. You can see a clear upward trend and a strong seasonality in the summer months. That’s something we’ll explore later.
The issue that requires immediate attention is the style of this chart. It’s nowhere near ready to show to your client or boss, since the title is missing, axis labels could do with some retouch, and the overall theme is awful.
Here’s a code snippet that will fix all of the listed issues:
ggplot(data, aes(x = date, y = Passengers)) +
geom_line(color = "#0099f9", size = 1.4) +
theme_classic() +
theme(
axis.text = element_text(size = 14, face = "bold"),
axis.title = element_text(size = 15),
plot.title = element_text(size = 18, face = "bold")
) +
labs(
title = "Airline Passengers Dataset",
x = "Time period",
y = "Number of passengers in 000"
)
This is what the chart looks like now:

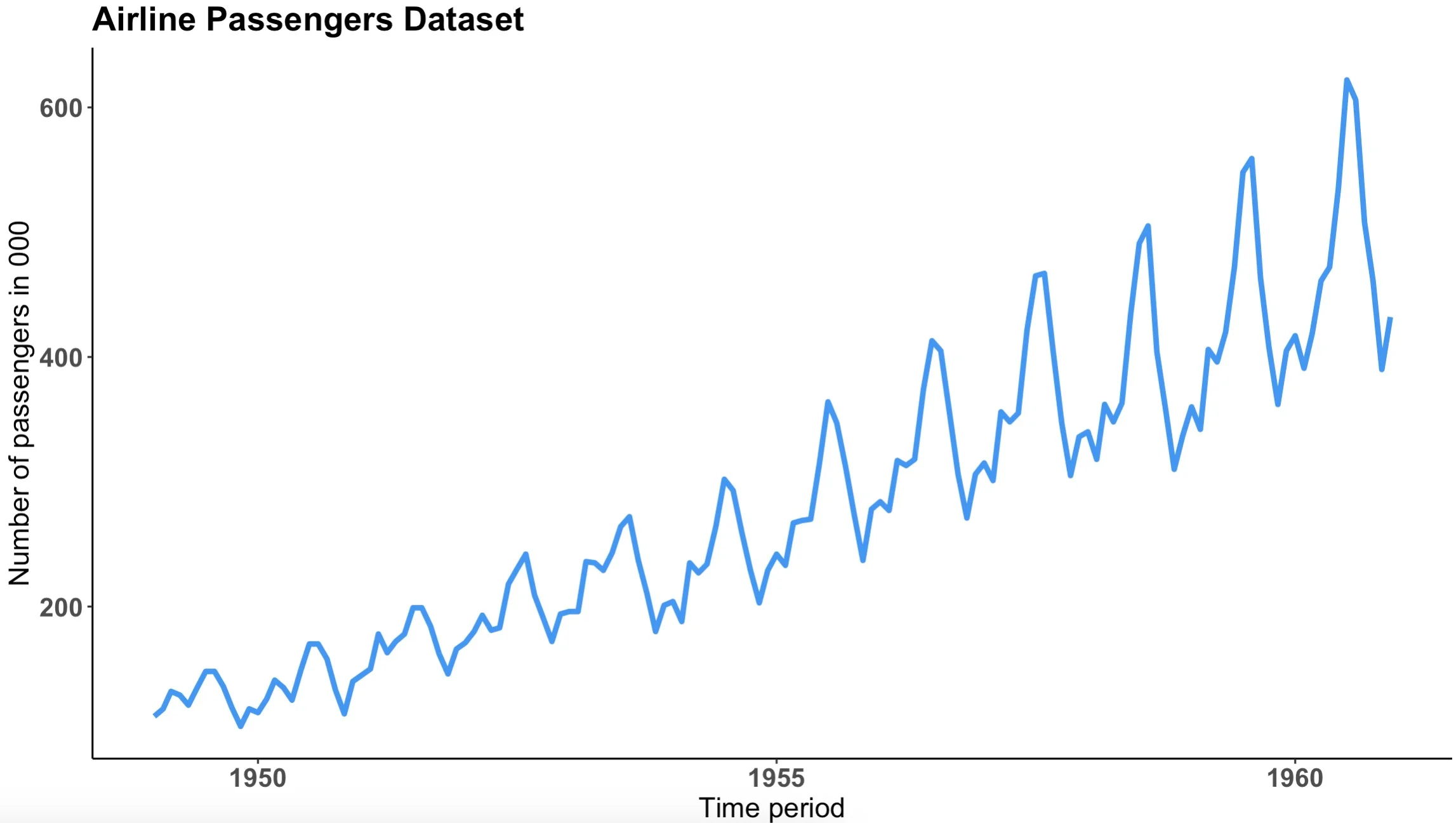
Image 7 – Styled line chart
Now we’re talking! We’ve gone from plain to stunning in just a couple of lines of code.
Are you new to data visualization wtih ggplot2? This article will teach you how to make stunning line charts.
Up next, let’s discuss an issue present in many time series datasets (but not in Airline passengers) – missing values.
Handling Missing Dates and Values
When working with time series datasets, it’s crucial that you have a full picture in front of you, which is a term describing a dataset that has no missing dates or values. There are ways of dealing with missing values, but dates are a lot trickier.
Let’s explore them first.
Time Series with Missing Dates
To demonstrate the point, we’ll create a dummy time series dataset containing monthly sampled data for all months in 2023. But here’s the thing – there are no records for March, July, and August:
ts <- data.frame(
date = c("2023-01-01", "2023-02-01", "2023-04-01", "2023-05-01", "2023-06-01",
"2023-09-01", "2023-10-01", "2023-11-01", "2023-12-01"),
value = c(145, 212, 265, 299, 345, 278, 256, 202, 176)
)
ts$date <- ymd(ts$date)
ts
You can clearly see the records are missing in the following image:


Image 8 – Time series dataset with rows missing
So, what can you do?
The usual operating procedure is the following:
- Create a new
data.framethat has an entire sequence of dates. Use thelubridate::seq()for the task instead of implementing the logic manually - Merge the new
data.framewith the one that contains missing records – this will essentially add the missing records to the right place and set the value toNA - Replace
NAvalues with something appropriate – zeros will do fine for now.
If you prefer code over text, here’s a snippet for you:
# 1. Create a new data.frame that has a full sequence of dates full_date_df <- data.frame( date = seq(min(ts$date), max(ts$date), by = "month") ) # 2. Merge with the old one on the `date` column new_ts <- merge(full_date_df, ts, by = "date", all.x = TRUE) # 3. Some values are now missing - replace them with 0 new_ts$value[is.na(new_ts$value)] <- 0 new_ts
This is what the reformatted R time series dataset looks like:

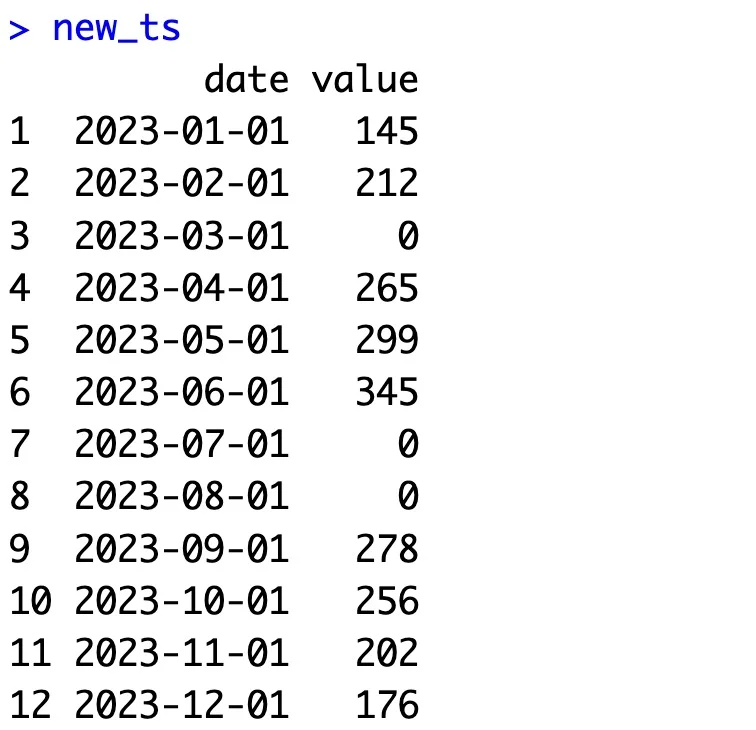
Image 9 – Time series dataset with added rows
Great, that takes care of missing dates, but what about values? That’s what we’ll cover next.
Time Series with Missing Values
Code-wise, missing values are a lot easier to deal with. It’s best if you can find out why the values are missing in the first place, but if you can’t, there are various statistical methods available for imputing them.
With missing values in time series datasets, you usually have the data column fully populated, and the value field is set to NA.
Here’s an example of one such dataset:
ts <- data.frame(
date = seq(ymd("20230101"), ymd("20231231"), by = "months"),
value = c(145, 212, NA, 265, 299, 345, NA, NA, 278, 256, 202, 176)
)
ts
This is what it looks like:

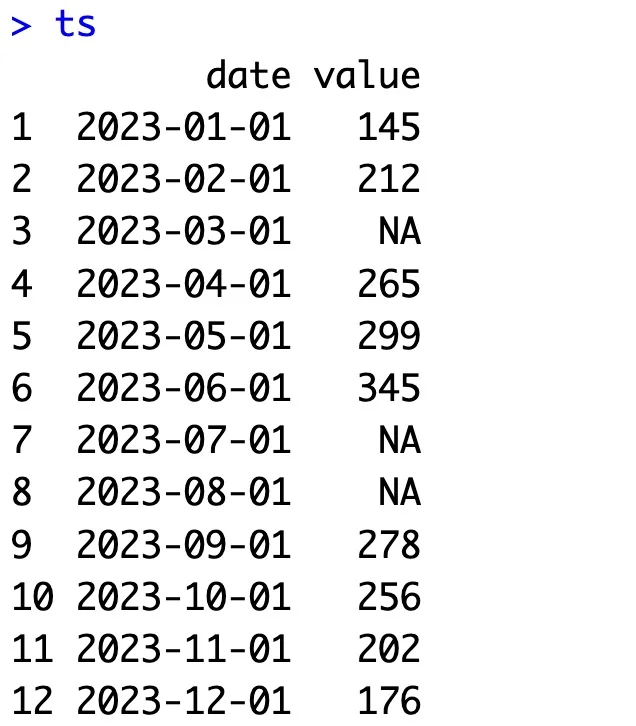
Image 10 – Time series dataset with missing values
This time, only the values for April, July, and August are missing. We’ll show you four techniques for imputing them:
- Mean value – All missing values will be replaced with a simple average of the series.
- Forward fill – The missing value at the point T is filled with a non-missing value at T-1.
- Backward fill – The missing value at the point T is filled with a non-missing value at T+1.
- Linear interpolation – The missing value at the point T is filled with an average of non-missing values at T-1 and T+1.
This is how you can implement all of them in code:
library(zoo) # 1. Mean value imputation mean_value <- mean(ts$value, na.rm = TRUE) ts$mean <- ifelse(is.na(ts$value), mean_value, ts$value) # 2. Forward fill ts$ffill <- na.locf(ts$value, na.rm = FALSE) # 3. Backward fill ts$bfill <- na.locf(ts$value, fromLast = TRUE, na.rm = FALSE) # 4. Linear interpolation ts$interpolated <- na.approx(ts$value) ts
And here’s what the dataset looks like afterward:

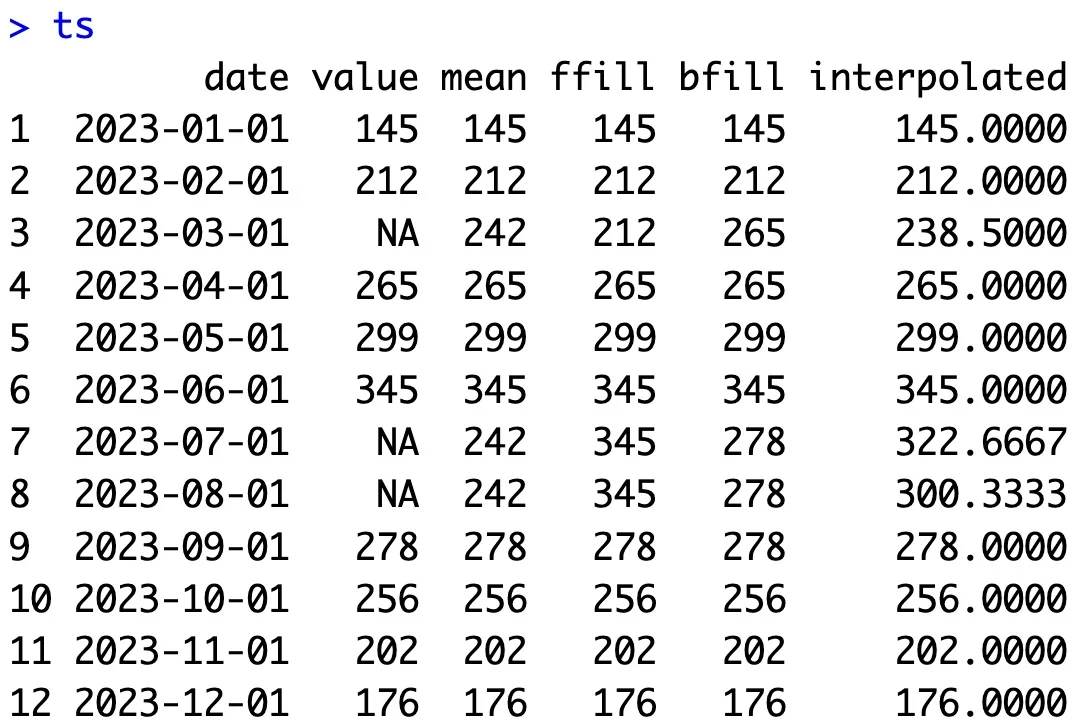
Image 11 – Time series dataset after missing value imputation
That covers handling missing dates and values. Up next, you’ll learn how to add a couple of useful visualizations to your existing time series charts.
Basic Time Series Operations: Data Smoothing and Trendlines
In this final section, you’ll learn two basic but vital time series tasks – smoothing the data curve via moving averages and calculating trendlines.
As for the dataset, we’re back to Airline passengers. We’ve loaded the whole thing from scratch, just to have a clean start.
library(lubridate)
data <- read.csv("airline-passengers.csv")
data$Month <- ym(data$Month)
head(data)
Here’s what the data looks like:

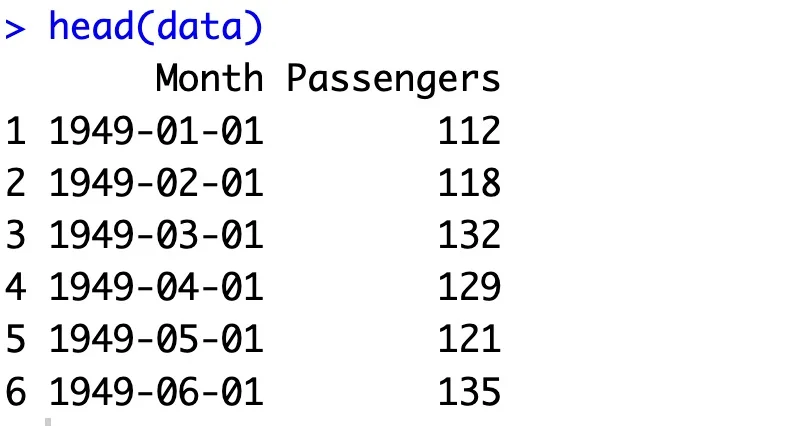
Image 12 – Airline passengers dataset
First, let’s see what smoothing the values curve brings us.
Smoothing the Data Curve
Okay, so, moving averages – what are they? Think of them as a technique that allows you to smooth out short-term fluctuations in a time series dataset. Doing so enables you to shift the focus from extremes to the overall shape of the data.
Calculating moving averages involves taking an average of a subset of the total data points at different time intervals, which then “moves” along with the data. In a nutshell, each point on a moving average line represents the average value of the dataset over a specific preceding period.
One important parameter worth discussing with moving averages is the window size. In plain English, it determines the number of consecutive data points used to calculate each point in the moving average. When you use a moving average with different factors, such as 3, 6, or 12, it impacts the smoothness of the resulting average and the sensitivity to changes in the data.
Now onto the code. We’ll use the zoo package to calculate moving averages with window sizes of 3, 6, and 12:
library(zoo) data$Passengers_MA3 <- rollmean(data$Passengers, 3, fill = NA) data$Passengers_MA6 <- rollmean(data$Passengers, 6, fill = NA) data$Passengers_MA12 <- rollmean(data$Passengers, 12, fill = NA) head(data, 12)
This is what the dataset looks like after the calculation:


Image 13 – Airline passenger dataset with moving averages
Some values at each end of the dataset are missing, and that’s simply because there’s no way to calculate a moving average for data points before a certain point, depending on the window size.
Further, missing values are irrelevant for the point we’re trying to prove.
You’ll get the idea why moving averages are useful as soon as you visualize them:
ggplot(data, aes(x = Month)) +
geom_line(aes(y = Passengers), color = "black", size = 1) +
geom_line(aes(y = Passengers_MA3), color = "red", size = 1) +
geom_line(aes(y = Passengers_MA6), color = "green", size = 1) +
geom_line(aes(y = Passengers_MA12), color = "blue", size = 1) +
theme_classic() +
theme(
axis.text = element_text(size = 14, face = "bold"),
axis.title = element_text(size = 15),
plot.title = element_text(size = 18, face = "bold"),
legend.position = "bottom"
) +
labs(
title = "Airline Passengers Dataset with Moving Averages",
x = "Time period",
y = "Number of passengers in 000"
)
This is the chart you’ll end up with:

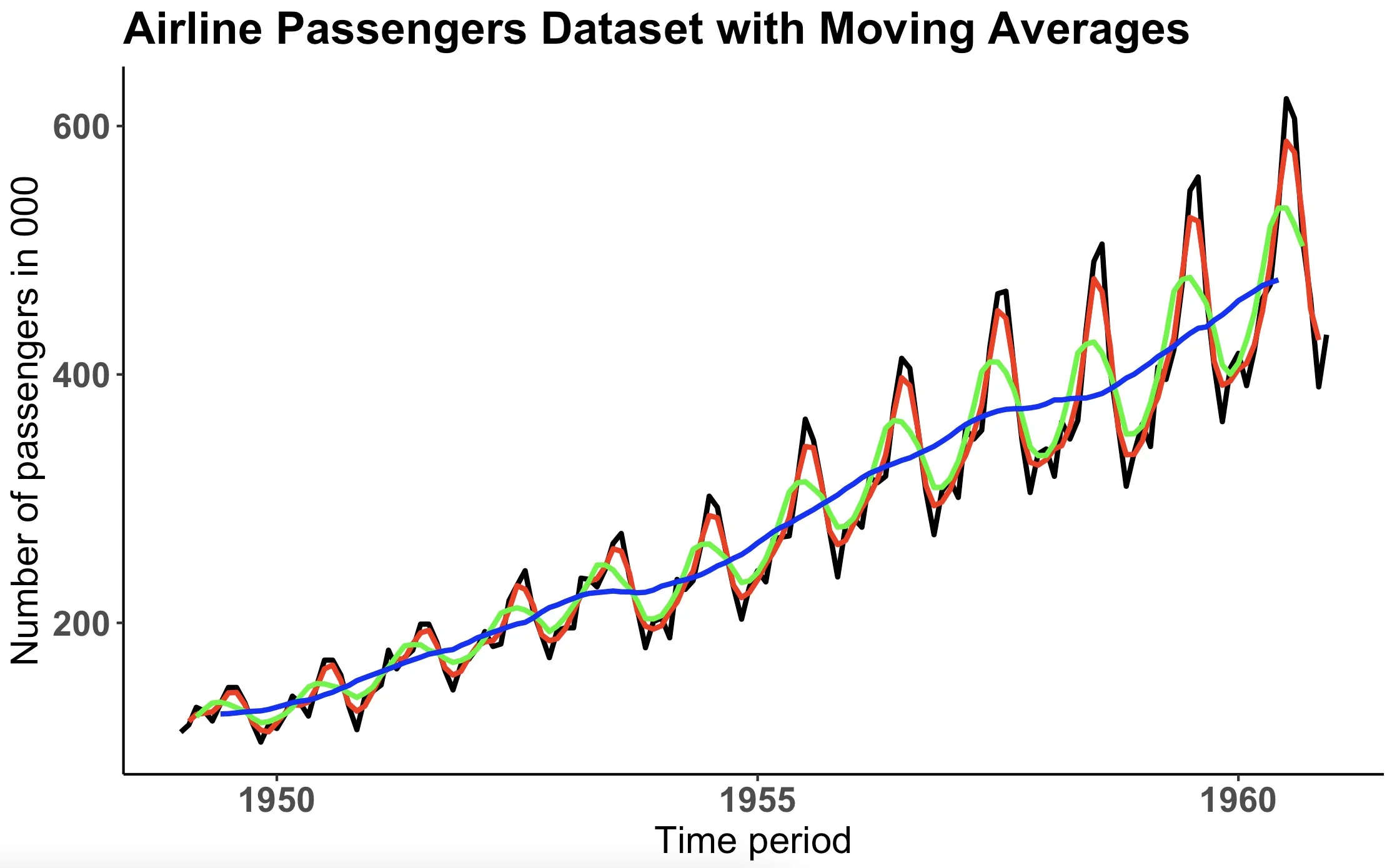
Image 14 – Original Airline passengers dataset with moving averages
Overall, the larger the window size, the smoother the data curve.
To conclude, moving averages allow you to see a generalized pattern in your data, rather than focusing on short-term fluctuations.
Up next, let’s go over trendlines.
Plotting a Trendline
A trendline does just what the name suggests – it shows a general trend of your data – either neutral, positive, or negative.
To calculate a trendline, you’ll want to fit a linear regression model on a derived numeric feature, and then use the same feature to calculate predictions.
This will return a line of best fit – or line that best describes the data – or trendline.
Here’s the code needed to fit a linear regression model:
# Create a numeric feature
data$Month_num <- as.numeric(data$Month)
# Fit a linear regression model
model <- lm(Passengers ~ Month_num, data = data)
# Get predictions
data$Trend_Line <- predict(model, newdata = data)
head(data[c("Month", "Passengers", "Trend_Line")], 12)
The code also prints the first 12 rows of the dataset:

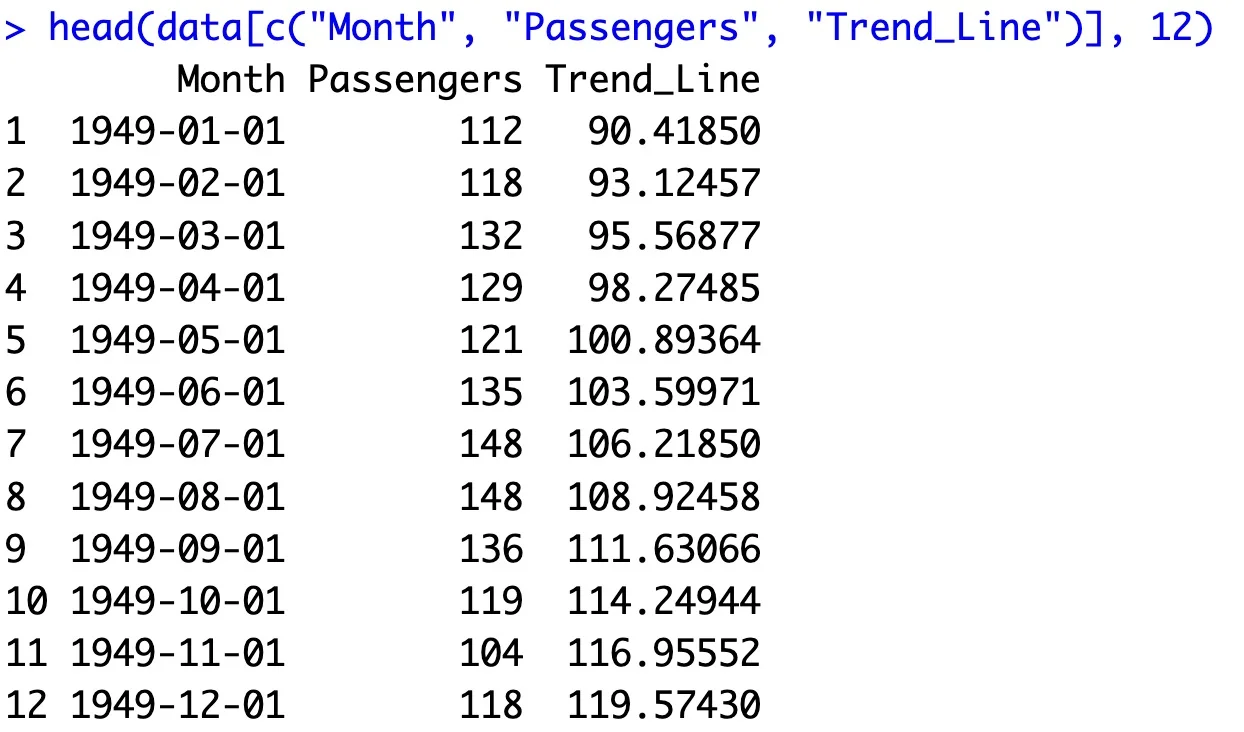
Image 15 – Airline passengers dataset with a trendline
It doesn’t make much sense numerically, so let’s visualize it. You know the drill by now:
ggplot(data, aes(x = Month)) +
geom_line(aes(y = Passengers), color = "#0099f9", size = 1) +
geom_line(aes(y = Trend_Line), color = "orange", size = 1.4) +
theme_classic() +
theme(
axis.text = element_text(size = 14, face = "bold"),
axis.title = element_text(size = 15),
plot.title = element_text(size = 18, face = "bold"),
legend.position = "bottom"
) +
labs(
title = "Airline Passengers Dataset with a Trend Line",
x = "Time period",
y = "Number of passengers in 000"
)
This is the chart you’ll end up with:

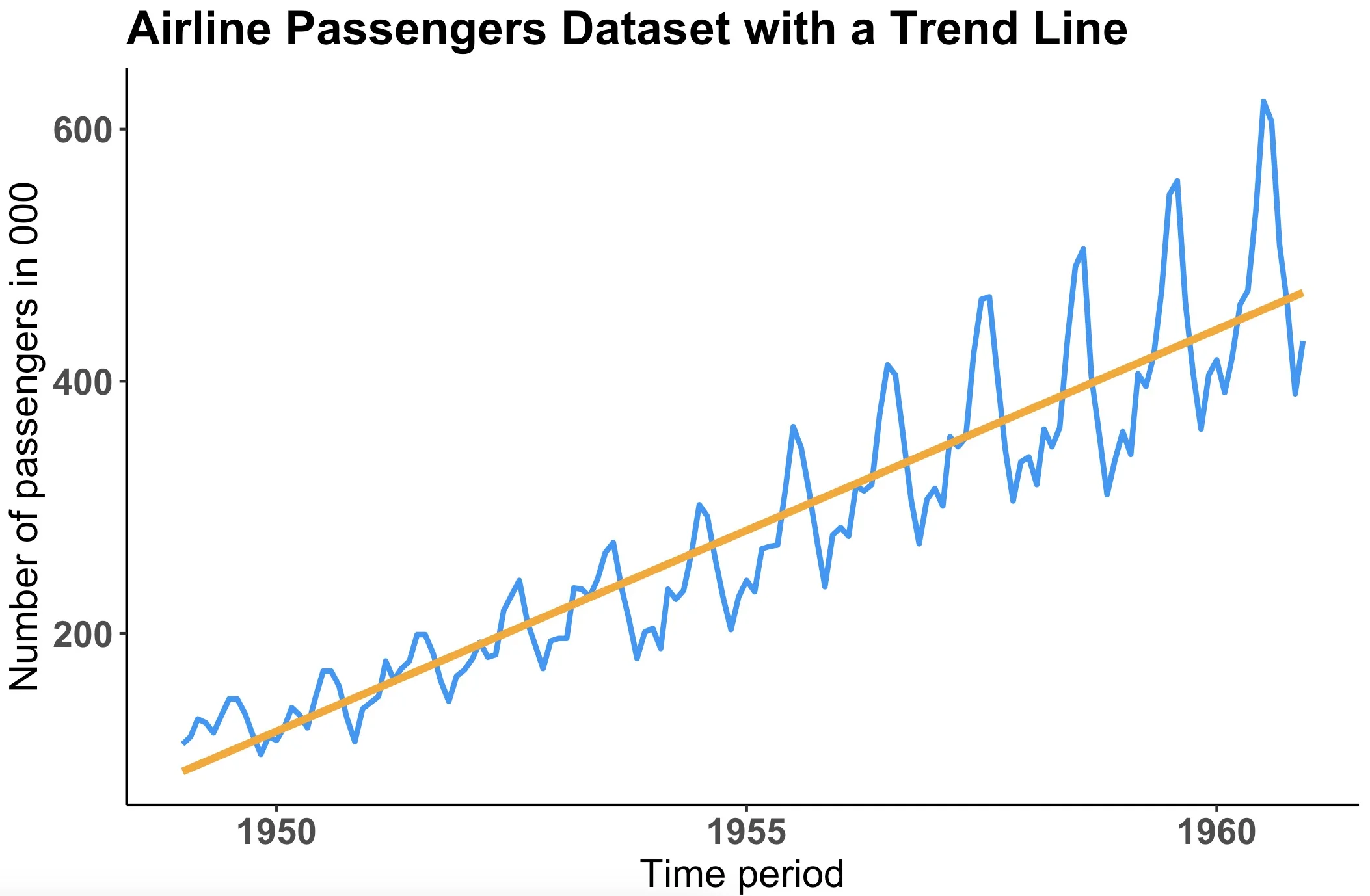
Image 16 – Visualized Airline passengers dataset with a trendline
Long story short, a trendline is just a straight line that best describes the general movement, or trend, of your data. You could also try fitting a polynomial regression model to this dataset if you suspect the trend shouldn’t be linear, but that’s a topic for some other time.
Summing up R Time Series Analysis
And there you have it – pretty much everything a newcomer to time series analysis and forecasting needs. We’ve covered a lot of analysis ground today, and you’ve learned how to load time series datasets, visualize them, work with missing values, and even something a bit more advanced – moving averages and trendlines.
The next natural step to take is to take a closer look into time series forecasting. That’s the topic we’ll cover in a follow-up article, so make sure to stay tuned to the Appsilon blog so you don’t miss it.
What else can you do with R? Here are 7 essential and beginner-friendly packages you must know.
The post appeared first on appsilon.com/blog/.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.