

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.

We developed an app that visualizes data from more than 100 studies standardized to one data model, and it didn’t go as smoothly as expected…
- “Why would I want to test the app with production data?”
- “Why should I extend my testing suite with {targets} if I already have unit-tests?”
- “Isn’t {targets} only for data science pipelines?”
- “How can I save time on manual tests?”
Those were the questions we faced during that project, read further to learn about our answers.
Table of contents:
- The project
- How we ensured the app worked correctly on new data
- Why should you use targets?
- Example: The test app
- What about unit tests?
- Setting up targets tests as a directory of a Rhino app
- Reuse existing unit tests
- Running a single test from targets pipeline
- Expanding the pipeline to run on multiple datasets
- Expanding the pipeline to run multiple tests
- Maintaining the pipeline
- Re-running targets when dataset is added or updated
- Caveats of using targets with box
- How it integrates with the software development lifecycle?
- Impact
The project
During the first stages of development, when most of the app architecture was implemented, we worked on one sample study.
- The study introduced a logical data model that helped us to learn about the domain.
- It allowed us to integrate the app with constraints posed by the model.
As more studies were loaded into the database we noticed that new edge cases were introduced, some studies were not compliant with the rules that the app was built on. Those edge cases were not present because studies didn’t comply with a schema (such errors would be caught by data validation pipeline), but it introduced new cases which were woven into datasets themselves, making the project more complex than imagined.
How we ensured the app worked correctly on new data
Our process for testing the app with new studies was as follows.
- Run the app manually, see if or where errors happen.
- Capture a bug report or mark the study as one that’s working as expected.
- If a bug was caught, decide on a correct solution (in agreement with a business expert).
- Put the business acceptance criteria in a backlog item and plan to implement it.
- Ensure new cases in data are captured as unit-tests.
This approach involves a lot of time spent on manual tests done on production datasets, as those new errors don’t appear in test datasets. The time spent on testing is even longer when datasets are added in cohorts, few at the same time, effectively reducing our time spent on app development.
This leads us to an idea, what if we run automated tests with production data as a method for bug discovery and regression?
Why should you use targets?
From the targets manual we learn that it:
[…] coordinate the pieces of computationally demanding analysis projects. The targets package is a Make-like pipeline tool for statistics and data science in R. The package skips costly runtime for tasks that are already up to date, orchestrates the necessary computation with implicit parallel computing, and abstracts files as R objects.
If we have 100 datasets to run tests on, even if tests for one dataset takes 1 minute, it’s 100 minutes of tests runtime!
But this amount of time is even longer for manual testing, so there is a lot of potential to save time and money.
In our case, there were 3 triggers for re-running tests:
- update of a study,
- addition of a new study,
- change in production code.
Given those triggers, it becomes apparent that those tests would need to be run quite often.
Now, let’s imagine the app hasn’t changed since the upload of the 101st dataset. If it was a simple testing script, we would need to rerun all 101 cases, but targets caches results and runs only for the tests for the 101st dataset, providing feedback much faster than a regular script.
Given those triggers and potential for caching, running tests with live data sounds very close to the core purpose of targets.
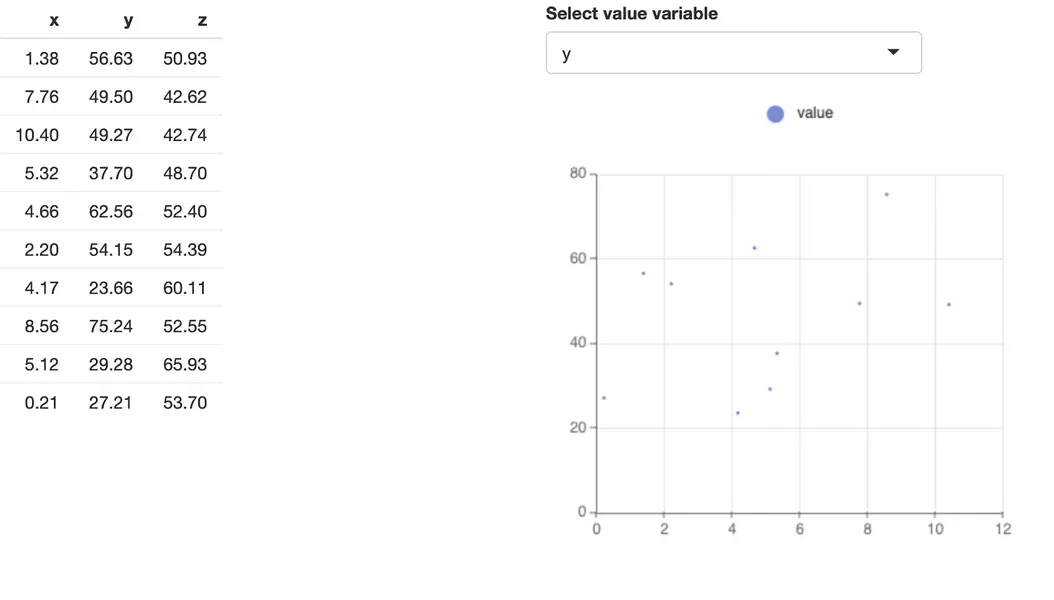
Example: The test app
The app displays the dataset as a table, and it plots a scatterplot with Y axis variable selectable using a dropdown. It’s a very simple app to showcase the method, your app can be arbitrarily complex, but the setup of such tests will be the same.
Check out this repository to see the full project.

#' app/main.R
#' @export
ui <- function(id) {
ns <- NS(id)
bootstrapPage(
fluidRow(
column(6, table$ui(ns("table"))),
column(6, plot$ui(ns("plot")))
)
)
}
#' @export
server <- function(id) {
moduleServer(id, function(input, output, session) {
db <- database$new()
data <- db$get_data()
table$server("table", data)
plot$server("plot", data)
})
}
Two main features of the app are split into modules. The responsibility of the table module is just to display the dataset, the responsibility of the plot module is to select a variable and display a scatter plot.
Since there are no interactions between modules, we will focus on testing modules in isolation. To test how modules interact with each other, you can use shinytest2. Refer to this vignette for more details.
What about unit tests?
It’s important to have unit tests as the feedback we get from them is very fast, if set up correctly they have the potential to catch many undesired changes in behavior of the app.
But since unit tests run on fixed test data, they won’t show if the code is not working as expected on new data.
Let’s take a look at unit tests of plot module:
#' tests/testthat/test-plot.R
box::use(
testthat[...],
shiny[testServer],
jsonlite[fromJSON],
mockery[
expect_args,
mock,
stub,
],
)
box::use(
module = app/view/modules/plot,
)
expect_plot <- function(x) {
x <- fromJSON(x)
expect_is(x, "list")
expect_setequal(names(x), c("x", "evals", "jsHooks", "deps"))
}
describe("plot", {
it("should render a plot", {
# Arrange
args <- list(
data = data.frame(
x = 1:10,
y = 1:10,
z = 11:20
)
)
testServer(module$server, args = args, {
# Act
session$setInputs(variable = "y")
plot <- output$plot
# Assert
expect_plot(plot)
})
})
it("should pass data to plotting function", {
# Arrange
args <- list(
data = data.frame(
x = 1:10,
y = 1:10,
z = 11:20
)
)
mock_plot <- mock()
stub(module$server, "scatterplot$plot", mock_plot)
testServer(module$server, args = args, {
# Act
session$setInputs(variable = "y")
plot <- output$plot
# Assert
expect_args(
mock_plot,
n = 1,
data = data.frame(
x = 1:10,
value = 1:10
)
)
})
})
})
They focus on testing 2 behaviors of the module:
- Asserting that it produces a plot, by checking if output is a
htmlwidget. - Asserting that it passes correct data to the plotting function, this includes a data preparation step – selection of a variable.
Notice we’re not asserting how the plot will look like, with each dataset the plot will look differently. Asserting only on the type of the returned object allows us to run these tests on multiple test datasets and test the property of the code that it produces a given widget.
If something goes wrong, we should expect it to throw an error, for example when input data validation fails in plot function:
#' app/view/plotting/scatterplot.R
box::use(
echarts4r[
e_charts,
e_scatter,
echarts4rOutput,
renderEcharts4r,
],
checkmate[
assert_data_frame,
assert_numeric,
assert_subset,
],
)
#' @export
plot <- function(data) { assert_data_frame(data) assert_subset(c("x", "value"), colnames(data)) assert_numeric(data$x) assert_numeric(data$value) data |>
e_charts(x) |>
e_scatter(value)
}
#' @export
output <- echarts4rOutput
#' @export
render <- renderEcharts4r
Whether the plot produces a correct output should be a responsibility of scatterplot module tests. In those tests, we can introduce a more controlled environment in which we can assert if it produces the correct visual given certain data.
This test falls more into an acceptance test category. How to implement such a test is out of scope of this article. It could be implemented with the vdiffr package – we expect that for given data a certain image will be produced – if the implementation of the function changes we can accept or reject the image that it produces.
Step 1: Setting up targets tests as a directory of a Rhino app
Targets usually serves as a project on its own, but we can leverage Rhino app flexibility to place targets in one of the project directories.
Since we’re using targets for tests, let’s create a tests/targets/ directory and add tests/targets/_targets.R which is the starting point of any targets’ project.
Let’s add a code>_targets.yaml config file in project root directory:
#' _targets.yaml main: script: tests/targets/_targets.R store: tests/targets/_targets
The script entry enables running targets’ pipeline with targets::tar_make() command from tests/targets/_targets.R script. The store entry configures a directory where targets metadata and results will be stored.
Step 2: Reuse existing unit tests
In case we already have test cases that we want to rerun with production data, we can extract those cases in a way that they can be used in targets and in unit tests to reduce code repetition.
Let’s start with the first test case of plot module:
#' tests/testthat/test-plot.R
describe("plot", {
it("should render a plot", {
# Arrange
args <- list(
data = data.frame(
x = 1:10,
y = 1:10,
z = 11:20
)
)
testServer(module$server, args = args, {
# Act
session$setInputs(variable = "y")
plot <- output$plot
# Assert
expect_plot(plot)
})
})
...
})
We will separate Act and Assert blocks from Arrange, as only Arrange block will be different for unit tests and target tests.
#' tests/testthat/test-plot.R
assert_render_plot <- function(args) {
testServer(module$server, args = args, {
# Act
session$setInputs(variable = "y")
plot <- output$plot
# Assert
expect_plot(plot)
})
}
describe("plot", {
it("should render a plot", {
# Arrange
args <- list(
data = data.frame(
x = 1:10,
y = 1:10,
z = 11:20
)
)
# Act & Assert
assert_render_plot(args)
})
...
})
Now the assert_render_plot can be extracted to another module that will be used by tests/testtthat/test-plot.R and tests/targets/_targets.R. Let’s introduce test_cases module, tests directory will look like this:
├── tests │ ├── targets │ │ ├── _targets.R │ ├── test_cases │ │ ├── __init__.R │ │ ├── plot.R │ ├── testthat │ │ ├── test-plot.R │ │ ├── test-table.R
We’ll use __init__.R file in tests/test_cases/ to be able to reexport test cases for multiple modules.
tests/test_cases/plot.R will look like this:
#' tests/test_cases/plot.R
box::use(
testthat[
expect_is,
expect_setequal,
],
shiny[testServer],
jsonlite[fromJSON],
)
box::use(
module = app/view/modules/plot,
)
expect_plot <- function(x) {
x <- fromJSON(x)
expect_is(x, "list")
expect_setequal(names(x), c("x", "evals", "jsHooks", "deps"))
}
#' @export
assert_render_plot <- function(args) {
testServer(module$server, args = args, {
# Act
session$setInputs(variable = "y")
plot <- output$plot
# Assert
expect_plot(plot)
})
}
And tests/test_cases/__init__.R being:
#' tests/test_cases/__init__.R #' @export box::use( tests/test_cases/plot, )
And tests/testthat/test-plot.R updated to reuse imported test case:
#' tests/testthat/test-plot.R
box::use(
module = app/view/modules/plot,
test_cases = tests/test_cases/plot,
)
describe("plot", {
it("should render a plot", {
# Arrange
args <- list(
data = data.frame(
x = 1:10,
y = 1:10,
z = 11:20
)
)
# Act & Assert
test_cases$assert_render_plot(args)
})
...
})
Step 3: Running a single test from targets pipeline
Now we are ready to run our first test case from targets.
#' tests/targets/_targets.R
box::use(
targets[
tar_target,
]
)
box::use(
tests/test_cases,
)
dataset <- data.frame(x = 1:10, y = 1:10, z = 1:10)
list(
tar_target(
name = test,
command = test_cases$plot$assert_render_plot(list(data = dataset))
)
)
This script will run an assert_render_plot case with the provided dataset. We’ve defined it by hand, but it could be a dataset fetched from a production database. When inspecting the pipeline with targets::tar_visnetwork() we see that our test case depends on the test_cases module and dataset. The test will be invalidated anytime the dataset or test_case module changes.


Running the pipeline with targets::tar_make() will produce artifacts stored in tests/targets/_targets/ as configured in _targets.yaml.
Let’s check if the test has the ability to fail. After all, we’re interested in the conditions in which our code fails to execute.
Let’s try with a given dataset:
dataset <- data.frame(x = as.character(1:10), y = as.character(1:10))
It will result in pipeline failing on input data validation as plot function expects numeric x and y variables, it will fail on validation of x variable, as it’s the first assertion:
r$> targets::tar_make() ▶ start target test Loading required package: shiny ✖ error target test ▶ end pipeline [0.118 seconds] Error: ! Error running targets::tar_make() Error messages: targets::tar_meta(fields = error, complete_only = TRUE) Debugging guide: <https://books.ropensci.org/targets/debugging.html> How to ask for help: <https://books.ropensci.org/targets/help.html> Last error: Assertion on 'data$x' failed: Must be of type 'numeric', not 'character'.dataset <- data.frame(x = as.character(rnorm(10, 5, 3)), y = as.character(rnorm(10, 50, 12))
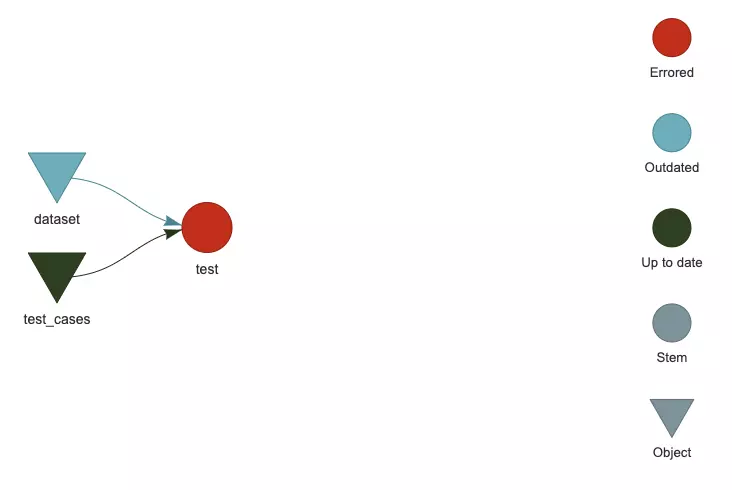

targets::tar_load() function can be used to load pipeline results from a selected node. Our result is stored in test node:
targets::tar_load(test)
But the loaded test object is NULL as test node didn’t produce any output.
We need to collect errors from all test cases to be reported at the end of the pipeline. To capture them, we can use purrr::safely function. It modifies a function to return not only the result value, but also errors.
#' tests/targets/_targets.R
box::use(
targets[
tar_target,
],
purrr[
safely,
]
)
box::use(
tests/test_cases,
)
dataset <- data.frame(x = as.character(1:10), y = as.character(1:10))
list(
tar_target(
name = test,
command = safely(test_cases$plot$assert_render_plot)(list(data = dataset))
)
)
After rerunning the pipeline, we get the following:
r$> targets::tar_load(test) r$> test $result NULL $error
Now the pipeline allows us to easily target (pun intended) the function which fails and to see the exact error message it produced.
Step 4: Expanding the pipeline to run on multiple datasets
Let’s increase the number of test datasets to 2, from now on it won’t matter if it’s 2 datasets or 100.
Iteration in targets is done via branching. There are 2 branching options:
In this example we’ll use static branching strategy as it allows you to see all branches upfront when inspecting the pipeline with targets::tar_visnetwork(). The input of static branching is either a list or a data.frame. In the case of data.frame the iteration is rowwise.
Let’s create a list of datasets and the grid and use tarchetypes::tar_map to iterate over the parameters:
#' tests/targets/_targets.R
box::use(
targets[
tar_target,
],
tarchetypes[
tar_combine,
tar_map,
],
purrr[
safely,
],
dplyr[
bind_rows,
tibble,
],
rlang[`%||%`]
)
box::use(
tests/test_cases,
)
datasets <- list(
"1" = data.frame(x = as.character(1:10), y = as.character(1:10)),
"2" = data.frame(x = 1:10, y = 1:10)
)
grid <- tibble(
dataset_name = c("1", "2"),
module = c("plot", "plot"),
test_case = c("assert_render_plot", "assert_render_plot")
)
safe_test <- function(module, test_case, dataset_name) {
# Get data from datasets list
data <- datasets[[dataset_name]]
# Get test function from a module
test_function <- test_cases[[module]][[test_case]]
result <- safely(test_function)(list(data = data))
tibble(
module = module,
test_case = test_case,
dataset_name = dataset_name,
# Don't omit rows in which error == NULL by replacing it with NA
error = as.character(result$error %||% NA)
)
}
test_grid <- list(
tar_map(
values = grid,
tar_target(
name = test,
command = safe_test(module, test_case, dataset_name)
)
)
)
test_results <- tar_combine(
name = results,
test_grid,
command = bind_rows(!!!.x, .id = "id")
)
list(
test_grid,
test_results
)
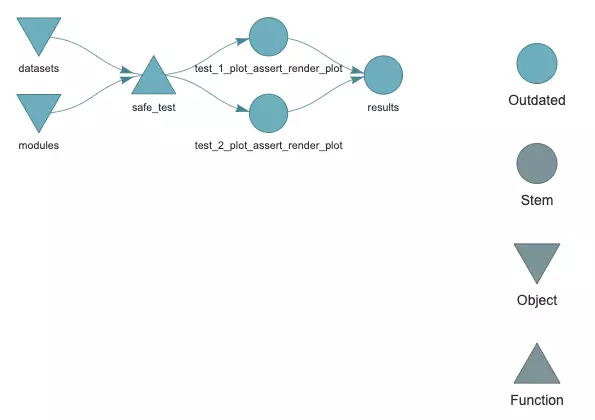

r$> targets::tar_make() ▶ start target test_1_plot_assert_render_plot Loading required package: shiny ● built target test_1_plot_assert_render_plot [0.167 seconds] ▶ start target test_2_plot_assert_render_plot ● built target test_2_plot_assert_render_plot [0.173 seconds] ▶ start target results ● built target results [0.001 seconds] ▶ end pipeline [0.398 seconds]
The result of the pipeline is now a single data.frame:
r$> targets::tar_load(results)
r$> results
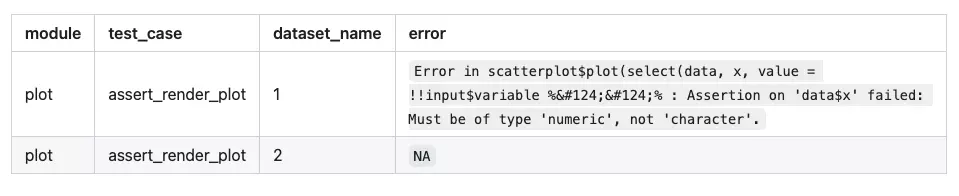
# A tibble: 2 × 5
id module test_case dataset_name error
1 test_1_plot_assert_render_plot plot assert_render_plot 1 "Error in scatterplot$plot(select(dat…
2 test_2_plot_assert_render_plot plot assert_render_plot 2
Inspecting the data.frame tells us which test cases fail, it’s easy to trace back what conditions made the code to fail.
Having the result as a data.frame allows us to use it to create a custom test report, e.g., in Markdown format, which may be a better format to display results for app stakeholders.

Step 5: Expanding the pipeline to run multiple tests
To add more tests, we may either expand the list of test cases for plot module or add a test case for table module. Let’s do the latter. It requires us to do the following:
- Add tests/test_cases/table.R module
- refactor tests/testthat/test-table.R to reuse test case from tests/test_cases/table.R
- export table module from tests/test_cases/__init__.R
- expand parameters grid in tests/targets/_targets.R
#' tests/targets/_targets.R
box::use(
targets[
tar_target,
],
tarchetypes[
tar_combine,
tar_map,
],
purrr[
safely,
],
dplyr[
bind_rows,
tibble,
],
rlang[`%||%`]
)
box::use(
tests/test_cases,
)
datasets <- list(
"1" = data.frame(x = as.character(1:10), y = as.character(1:10)),
"2" = data.frame(x = 1:10, y = 1:10)
)
grid <- tibble(
dataset_name = c("1", "2", "1", "2"),
module = c("plot", "plot", "table", "table"),
test_case = c("assert_render_plot", "assert_render_plot", "assert_render_table", "assert_render_table")
)
safe_test <- function(module, test_case, dataset_name) {
data <- datasets[[dataset_name]]
test_function <- test_cases[[module]][[test_case]]
result <- safely(test_function)(list(data = data))
tibble(
module = module,
test_case = test_case,
dataset_name = dataset_name,
error = as.character(result$error %||% NA)
)
}
test_grid <- list(
tar_map(
values = grid,
tar_target(
name = test,
command = safe_test(module, test_case, dataset_name)
)
)
)
test_results <- tar_combine(
name = results,
test_grid,
command = dplyr::bind_rows(!!!.x)
)
list(
test_grid,
test_results
)
Now the pipeline will run 4 tests:
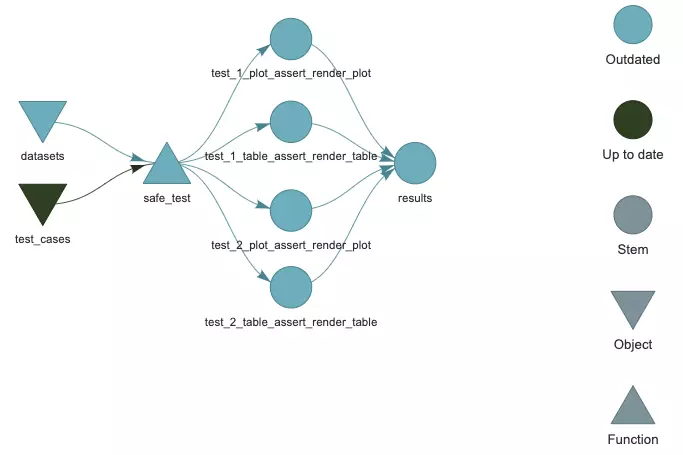

r$> targets::tar_load(results)
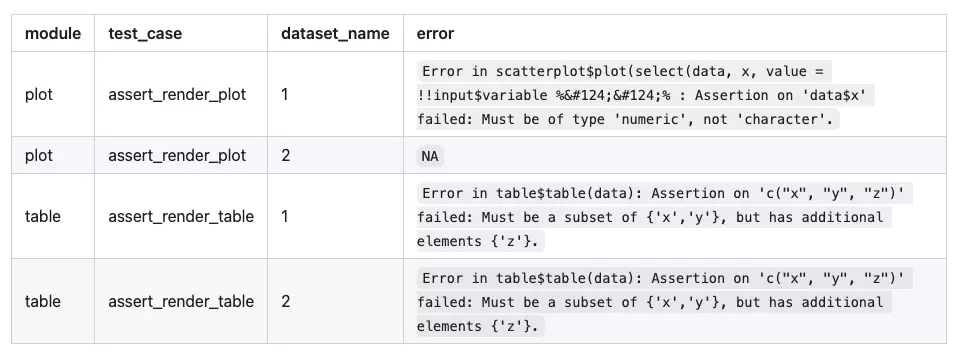
r$> results
# A tibble: 4 × 4
module test_case dataset_name error
1 plot assert_render_plot 1 "Error in scatterplot$plot(sel…
2 plot assert_render_plot 2 NA
3 table assert_render_table 1 "Error in table$table(data): A…
4 table assert_render_table 2 "Error in table$table(data): A…

Step 6: Maintaining the pipeline
Other than keeping a single repository for parameterized test cases, automatic creation of parameters grid for the pipeline will help with its maintenance.
Knowing how to list datasets on which we want pipeline to run and using ls() to list objects in the box module, we can use tidyr::expand_grid to automatically create the grid and never bother to update tests/targets/_targets.R script.
Step 7: Re-running targets when dataset is added or updated
In the provided example, we have in-memory test datasets, but it’s easy to refactor the code to pull datasets from a remote database. In this case, we can provide a method that will poll the database to list the tables and check if they have been updated. It could be a pair of table names and an update timestamp. When this tuple is passed to safe_test function it will become its dependency, re-running only targets for new tables, or tables with changed timestamp.
Caveats of using targets with {box}
Functions imported with box are placed in an environment. Targets will depend on the modules from which we import test cases. That means if we change one case, the tests/test_cases module will change, effectively invalidating all cases. To not depend on module changing, we can take advantage of local box imports and refactor the safe_test function to be:
#' tests/targets/_targets.R
safe_test <- function(module, test_case, dataset_name) {
# Don;t depend on test cases module
box::use(
tests/test_cases,
)
data <- datasets[[dataset_name]]
test_function <- test_cases[[module]][[test_case]]
result <- safely(test_function)(list(data = data))
tibble(
module = module,
test_case = test_case,
dataset_name = dataset_name,
error = as.character(result$error %||% NA)
)
}
Notice that this will also break dependency of target nodes on changes in tested functions as well. To invalidate pipeline nodes, we can introduce dependency on modules’ production code:
#' tests/targets/_targets.R
box::use(
app/view/modules,
)
safe_test <- function(module, test_case, dataset_name) {
# Don't depend on test cases module
box::use(
tests/test_cases,
)
# Depend on production module
modules[[module]]
data <- datasets[[dataset_name]]
test_function <- test_cases[[module]][[test_case]]
result <- safely(test_function)(list(data = data))
tibble(
module = module,
test_case = test_case,
dataset_name = dataset_name,
error = as.character(result$error %||% NA)
)
}
In this form, pipeline will rerun tests when the module’s production code has changed. Different forms of box imports allow you to create custom invalidation rules of targets.
How does E2E testing integrate with the Shiny software development lifecycle?
This approach shouldn’t serve as a replacement of unit-testing and E2E testing methods, but as an additional safety net that can help us produce bug-free software.
These tests can serve as one of last checks before the release, it can improve the confidence in our software that it integrates with production systems as expected.
Feedback obtained from this test will be definitely slower than the one from unit tests. We still can use rhino::test_r() as the main source of feedback, with targets::tar_make() being run only just before committing to the trunk.
The pipeline can be run:
- locally with
targets::tar_make() - as a scheduled Markdown in Posit Connect
- as a part of data validation workflow
- with cloud storage to keep the same cache for all developers, reducing pipeline runtime.
It’s up to you to find the best way to integrate the pipeline with the rest of your processes.
Impact of {targets} for developing a production Shiny app
The solution described helped us save tens of hours of developers time, allowing us to focus on solving issues and developing new features instead of manual validation.
Tests implemented with such a pipeline were more detailed than manual testing, allowing us to catch more issues. Each time the pipeline was run we had a detailed description of which tests were executed and what was their result which was not possible with manual testing.
If this is a problem you’re facing in your project, give it a shot. Let’s leverage existing solutions and use targets to make our Shiny apps safer!
The post appeared first on appsilon.com/blog/.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.