

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
The Turkish central bank president has changed, and she has started to execute new economic policies. Regarding that, the Turkish Lira-related currency rates have risen. Therefore, I wonder how the Euro to Turkish lira exchange rates will look by the end of the year.
While we will model the exchange rates, we will benefit from multiple model screening techniques via the tidymodels and modeltime packages. The models we will use to compare:
arima_regarima_boostexp_smoothing(ETS – Automated Exponential Smoothing)prophet_reglinear_reg(glmnet)mars(EARTH)
Before we start modeling, we have to take one issue into consideration. The modeltime models are built with date objects only, while parsnip models take derivatives of date objects. The only exception in this example is the arima_boost model; it takes both. Because of this, we will separate the models into three workflow sets.
#EUR/TRY monthly prices
library(tidyverse)
library(tidyquant)
df_eurtry <-
tq_get("EURTRY=X",
from = "2005-01-01") %>%
tq_transmute(select = close,
mutate_fun = to.monthly) %>%
mutate(date = as.Date(date)) %>%
rename(price = close)
# Split Data 90/10
library(timetk)
splits <- initial_time_split(df_eurtry, prop = 0.9)
df_train <- training(splits)
df_test <- testing(splits)
df_folds <- time_series_cv(df_eurtry,
initial = 191,
assess = 24)
#Modeltime models only with date object
library(tidymodels)
library(modeltime)
# Model 1: auto_arima
model_fit_arima_reg <-
arima_reg() %>%
set_engine(engine = "auto_arima") %>%
fit(price ~ date, data = df_train)
# Model 2: exp_smoothing via ets
model_fit_ets <-
exp_smoothing() %>%
set_engine(engine = "ets") %>%
fit(price ~ date, data = df_train)
# Model 3: prophet_reg
model_fit_prophet <-
prophet_reg() %>%
set_engine(engine = "prophet") %>%
fit(price ~ date, data = df_train)
#Models with date-derivatives
# Model 4: arima_boost
model_arima_boost <-
arima_boost(
min_n = tune(),
learn_rate = tune(),
trees = tune()
) %>%
set_engine(engine = "auto_arima_xgboost")
# Model 5: linear_reg via glmnet
library(glmnet)
model_lm <-
linear_reg(penalty = tune(),
mixture = tune()) %>%
set_engine("glmnet")
# Model 6: mars via earth
model_mars <-
mars(prod_degree = tune(),
prune_method = tune()) %>%
set_engine("earth",
nfold = 10) %>%
set_mode("regression")
#Building workflow sets
library(workflowsets)
#With date object for modeltime models
modeltime_rec <-
recipe(price ~ date, data = df_train)
wflw_modeltime <-
workflow_set(
preproc = list(with_date = modeltime_rec),
models = list(ARIMA_reg = model_arima_reg,
ETS = model_ets,
Prophet = model_prophet)
)
#Both the date object and the derivatives of it for arima_boost
arima_boost_rec <-
modeltime_rec %>%
step_timeseries_signature(date) %>%
step_rm(contains("iso"),
contains("minute"),
contains("hour"),
contains("am.pm"),
contains("xts")) %>%
step_normalize(contains("index.num"), date_year) %>%
step_zv(all_predictors()) %>%
step_dummy(contains("lbl"), one_hot = TRUE)
wflw_arima_boost <-
workflow_set(
preproc = list(date_derivative = arima_boost_rec),
models = list(ARIMA_boost = model_arima_boost)
)
#Without date object for parsnip models
parsnip_rec <-
arima_boost_rec %>%
step_rm(date)
wflw_parsnip <-
workflow_set(
preproc = list(without_date = parsnip_rec),
models = list(Linear_glmnet = model_lm,
MARS = model_mars)
)
#Combining all the workflows we built above
all_wflws <-
bind_rows(wflw_parsnip,
wflw_arima_boost,
wflw_modeltime) %>%
# Make the workflow ID's a little more simple:
mutate(wflow_id = gsub("(without_date_)|(date_derivative_)|(with_date_)",
"",
wflow_id))
#Tuning and evaluating all the models
grid_ctrl <-
control_grid(
save_pred = TRUE,
parallel_over = "everything",
save_workflow = TRUE
)
grid_results <-
all_wflws %>%
workflow_map(
seed = 12345,
resamples = df_folds,
grid = 10,
control = grid_ctrl
)
Now, we will draw a plot to compare the results that we found above.
#Accuracy plot for ranking the models
library(ragg)#google setting
#rmse values for the geom_text layer
grid_rmse <-
grid_results %>%
rank_results(select_best = TRUE,
rank_metric = "rsq") %>%
select(wflow_id, .metric, mean, .config) %>%
filter(.metric == "rmse") %>%
pull(mean)
autoplot(
grid_results,
rank_metric = "rsq", # <- how to order models
metric = "rsq", # <- which metric to visualize
select_best = TRUE, # <- one point per workflow
) +
geom_text(aes(y = mean,
label = glue::glue("{wflow_id} - RMSE: {round(grid_rmse,2)}")),
angle = 0,
hjust = 0.5,
vjust = 1.5,
family = "Bricolage Grotesque",
face = "bold") +
labs(x="",
y="",
title = "Comparing R-square and RMSE Values of All Models") +
coord_flip() +
theme_minimal(base_family = "Bricolage Grotesque",
base_size = 20) +
theme(legend.position = "none",
plot.title = element_text(hjust = 0.5,
size = 16),
plot.margin = margin(0.5,
1,
0.5,
0.5,
unit = "cm"),
axis.text.y = element_blank(),
panel.grid.minor.y = element_blank(),
panel.grid.major.y = element_blank(),
panel.grid.minor.x = element_blank())

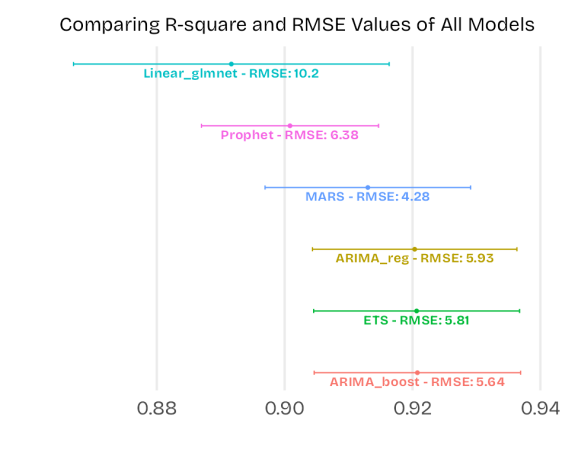
Although the three models that are at the bottom look the same based on the out-of-sample R-squared values, the ARIMA_boost model has the least RMSE score. Hence, we will select the boosted ARIMA regression model to forecast the exchange rates.
But first, we will pick the best XGBoost parameters in the boosted ARIMA and refit with them.
#Finalizing the model with the best parameters
arima_boost_best_param <-
grid_results %>%
extract_workflow_set_result("ARIMA_boost") %>%
select_best(metric = "rsq")
arima_boost_fit_wflw <-
grid_results %>%
extract_workflow("ARIMA_boost") %>%
finalize_workflow(grid_best_param) %>%
fit(df_train)
#Add fitted model to a Model Table
models_tbl_arima_boost <-
modeltime_table(arima_boost_fit_wflw)
#Calibrate the model to the testing set
calibration_tbl_arima_boost <-
models_tbl_arima_boost %>%
modeltime_calibrate(new_data = df_test)
#Refit to Full Dataset
refit_tbl_arima_boost <-
calibration_tbl_arima_boost %>%
modeltime_refit(data = df_eurtry)
Finally, we can build a forecasting table with the kableExtra package.
#Forecasting table
library(kableExtra)
refit_tbl_arima_boost %>%
modeltime_forecast(h = "4 months",
actual_data = df_eurtry) %>%
drop_na() %>%
mutate(Rate = round(.value,2),
Date = format(.index, "%Y %b"),
Conf_lower = round(.conf_lo,2),
Conf_upper = round(.conf_hi,2)) %>%
select(Date,
Rate,
Conf_lower,
Conf_upper) %>%
kbl() %>%
kable_styling(full_width = T,
position = "center") %>%
column_spec(column = 2,
color= "white",
background = spec_color(1:4, end = 0.7)) %>%
row_spec(0:4, align = "c") %>%
kable_minimal(html_ = "Bricolage Grotesque")


R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.