

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.




Gradient descent is a fundamental concept in machine learning, and therefore one practitioners should be familiar with. In this post we will explore gradient descent from both theoretical and practical perspectives. First, we will establish some general definitions, review cost functions in the context of regression and binary classification, and introduce the chain rule of calculus. Then, we will put it all into practice to build a linear and a logistic regression models from the ground up. This is a short, introductory guide where a basic knowledge of statistics and calculus should be most helpful. Ready, set, go! 
Introduction
Most predictive algorithms learn by estimating a set of parameters

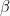

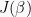

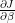



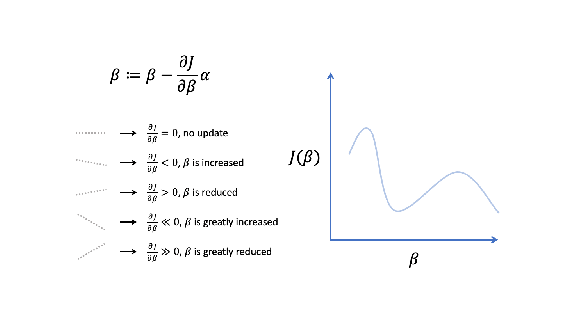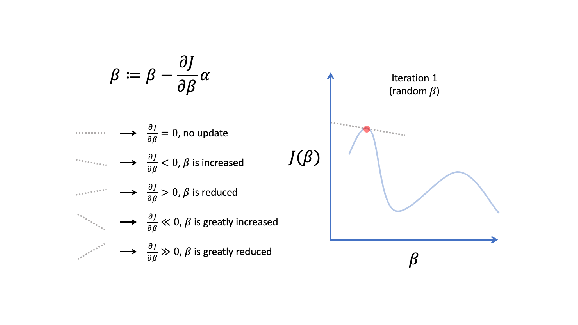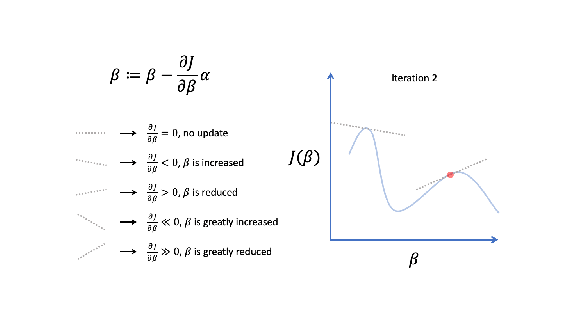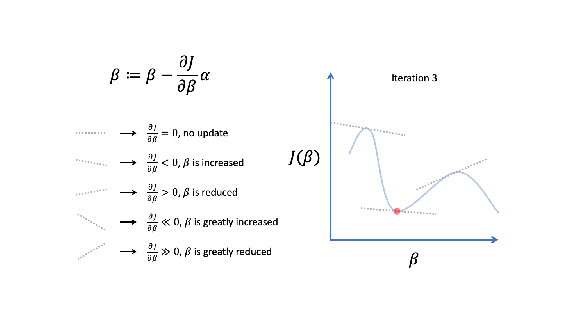
How gradient descent works will become clearer once we establish a general problem definition, review cost functions and derive gradient expressions using the chain rule of calculus, for both linear and logistic regression.
Problem definition 
We start by establishing a general, formal definition. Suppose we have a matrix

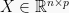

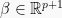

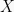
- In linear regression, we would like to predict the continuous target variable
- In logistic regression, we would like to predict the binary target variable



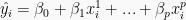

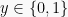



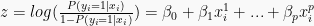
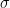
Note that in linear and logistic regression, in one shot you can directly access all n predictions and logit values, respectively, via the matrix product


Cost function 
In both linear and logistic regression, the aim is to find the parameter estimates that minimise the prediction error. This error is generally measured using a cost function:
- In linear regression, one can use the mean squared error (MSE),
- In logistic regression, one can use the binary cross-entropy,

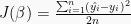

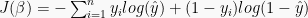
Putting it together, we have a recipe to predict a target

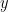

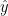
Gradient descent 
As we saw earlier, gradient descent is mainly driven by the partial derivatives of the cost function with respect to each individual parameter,
To this end, we can use of the chain rule of calculus, which posits that

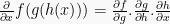




- For linear regression using a MSE cost function
- For logistic regression using a binary cross-entropy cost function

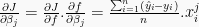

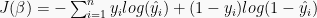



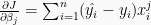
In both cases the application of gradient descent will iteratively update the parameter vector
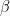

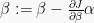

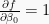
Now, I encourage you to apply the chain rule and try deriving these gradient expressions by hand, using the provided definitions of 




Let’s get started with R
Let us now apply these learnings to build two models using R:
- Linear regression, to predict the age of orange trees from their circumference

- Logistic regression, to predict engine shape from miles-per-gallon (mpg) and horsepower

In both cases we will implement batch gradient descent, where all training observations are used in each iteration. Mini-batch and stochastic gradient descent are popular alternatives that use instead a random subset or a single training observation, respectively, making them computationally more efficient when handling large sample sizes. Make sure that you have RColorBrewer installed.
Linear regression
Our first model, based on the Orange dataset, will have the following structure:


In the code below we will configure gradient descent such that in each of 25 iterations, a prediction is made and the two parameters b0 and b1, then plot and store their estimates under the lists intercepts and slopes, respectively. Finally, we will create a MSE cost function contour to visualise the trajectory of the same parameter estimates in the course of gradient descent.



< template class="js-file-alert-template">
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
< template class="js-line-alert-template">
< svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-alert">
< path d="M6.457 1.047c.659-1.234 2.427-1.234 3.086 0l6.082 11.378A1.75 1.75 0 0 1 14.082 15H1.918a1.75 1.75 0 0 1-1.543-2.575Zm1.763.707a.25.25 0 0 0-.44 0L1.698 13.132a.25.25 0 0 0 .22.368h12.164a.25.25 0 0 0 .22-.368Zm.53 3.996v2.5a.75.75 0 0 1-1.5 0v-2.5a.75.75 0 0 1 1.5 0ZM9 11a1 1 0 1 1-2 0 1 1 0 0 1 2 0Z">
| # Sun Nov 14 19:58:50 2021 —————————— | |
| # Regression Oranges | |
| library(RColorBrewer) | |
| data("Orange") | |
| # Determine number of iterations | |
| niter <- 25 | |
| # Determine learning rate / step size | |
| alpha <- 1e-4 | |
| set.seed(1) | |
| b0 <- rnorm(1) # intercept | |
| b1 <- rnorm(1) # slope | |
| # Set palette | |
| cols <- colorRampPalette(rev(brewer.pal(n = 7, name = "RdBu")))(niter) | |
| # Plot | |
| layout(matrix(c(1,1,2,2,3), nrow = 1, ncol = 5)) | |
| plot(age ~ circumference, data = Orange, pch = 16, | |
| xlab = "Circumference (mm)", | |
| ylab = "Age (days)", | |
| col = rgb(0,0,1,.5)) | |
| # Perform gradient descent | |
| slopes <- rep(NA, niter) | |
| intercepts <- rep(NA, niter) | |
| for(i in 1:niter){ | |
| # prediction | |
| y <- b0 + b1 * Orange$circumference | |
| # b0 = b0 – dJ/da * alpha | |
| b0 <- b0 – sum(y – Orange$age) / nrow(Orange) * alpha | |
| # b1 = b1 – dJ/db * alpha | |
| b1 <- b1 – sum((y – Orange$age) * Orange$circumference) / nrow(Orange) * alpha | |
| abline(a = b0, b = b1, col = cols[i], lty = 2) | |
| # Save estimates over all iterations | |
| intercepts[i] <- b0 | |
| slopes[i] <- b1 | |
| } | |
| title("Regression Fit") | |
| # Cost function contour | |
| allCombs <- expand.grid(b0 = seq(–50, 50, length.out = 100), | |
| b1 = seq(7.5, 8.5, length.out = 100)) | |
| res <- matrix(NA, 100, 100) | |
| # a by rows, b by cols | |
| for(i in 1:nrow(allCombs)){ | |
| y <- allCombs$b0[i] + allCombs$b1[i] * Orange$circumference | |
| res[i] <- sum((y – Orange$age)**2)/(2*nrow(Orange)) | |
| } | |
| # Plot contour | |
| contour(t(res), xlab = expression(beta[1]), | |
| ylab = expression(beta[0]), axes = F, nlevels = 25) | |
| axis(1, at = c(0, .5, 1), labels = c(7.5, 8, 8.5)) | |
| axis(2, at = c(0, .5, 1), labels = c(–50, 0, 50)) | |
| points((slopes – min(allCombs$b1)) / diff(range(allCombs$b1)), | |
| (intercepts – min(allCombs$b0)) / diff(range(allCombs$b0)), | |
| pch = 4, col = cols) | |
| title("MSE contour") | |
| # Add colorbar | |
| z = matrix(1:niter, nrow = 1) | |
| image(1, 1:niter, z, | |
| col = cols, axes = FALSE, xlab = "", ylab = "") | |
| title("Iteration No.") | |
| axis(2, at = c(1, seq(5, niter, by=5))) |

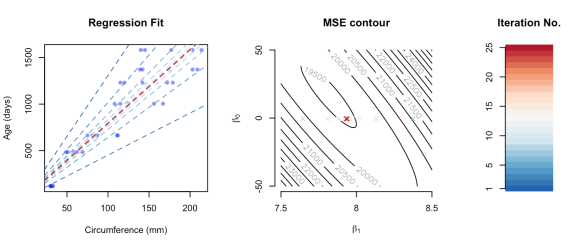
By colouring the iterations from blue (early) to red (late) using a diverging palette, we can see how gradient descent arrived at parameter estimates that minimise the prediction error! 
Logistic regression
Our second model, based on the mtcars dataset, will have the following structure:

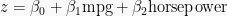

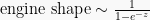
which is reminiscent of the generalised linear model employed in the past introduction to Bayesian models. In the code below, we will configure gradient descent such that in each of 100 iterations, a prediction is made and the three parameters b0, b1 and b2 and store their estimates under the lists intercepts, slopes1 and slopes2, respectively. Lastly, we will calculate and visualise the decision boundary from each iteration and examine how the parameter estimates change in the process.
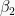
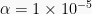
CALCULATING THE DECISION BOUNDARY
The decision boundary can be determined from setting the logit expression
to zero – equivalent to a target probability of 50% – then solving for either mpg or horsepower:
Solving for mpg here, we only need to pick at least two arbitrary values of horsepower, find their corresponding mpg values and connect the points with a line, in each iteration

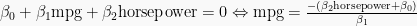
< template class="js-file-alert-template">
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
< template class="js-line-alert-template">
< svg aria-hidden="true" height="16" viewBox="0 0 16 16" version="1.1" width="16" data-view-component="true" class="octicon octicon-alert">
< path d="M6.457 1.047c.659-1.234 2.427-1.234 3.086 0l6.082 11.378A1.75 1.75 0 0 1 14.082 15H1.918a1.75 1.75 0 0 1-1.543-2.575Zm1.763.707a.25.25 0 0 0-.44 0L1.698 13.132a.25.25 0 0 0 .22.368h12.164a.25.25 0 0 0 .22-.368Zm.53 3.996v2.5a.75.75 0 0 1-1.5 0v-2.5a.75.75 0 0 1 1.5 0ZM9 11a1 1 0 1 1-2 0 1 1 0 0 1 2 0Z">
| # Sun Nov 14 20:13:12 2021 —————————— | |
| # Logistic regression mtcars | |
| library(RColorBrewer) | |
| data("mtcars") | |
| # Determine number of iterations | |
| niter <- 100 | |
| # Determine learning rate / step size | |
| alpha <- 1e-5 | |
| set.seed(1) | |
| b0 <- rnorm(1) # intercept | |
| b1 <- rnorm(1) # slope1 | |
| b2 <- rnorm(1) # slope2 | |
| # Set palette | |
| cols <- colorRampPalette(rev(brewer.pal(n = 7, name = "RdBu")))(niter) | |
| # Plot | |
| layout(matrix(c(1,1,2,2,3), nrow = 1, ncol = 5)) | |
| plot(mpg ~ hp, data = mtcars, pch = 16, | |
| xlab = "Horsepower", ylab = "Miles per gallon (mpg)", | |
| col = ifelse(mtcars$vs, rgb(0,0,1,.5), rgb(1,0,0,.5))) | |
| legend("topright", legend = c("Straight", "V-shaped"), | |
| col = c(rgb(0,0,1,.5), rgb(1,0,0,.5)), pch = 16, | |
| bty = "n") | |
| # Perform gradient descent | |
| slopes1 <- rep(NA, niter) | |
| slopes2 <- rep(NA, niter) | |
| intercepts <- rep(NA, niter) | |
| for(i in 1:niter){ | |
| # prediction | |
| logit <- b0 + b1 * mtcars$mpg + b2 * mtcars$hp | |
| y <- 1 / (1 + exp(–logit)) | |
| # b0 = b0 – dJ/da * alpha | |
| b0 <- b0 – sum(y – mtcars$vs) * alpha | |
| # b1 = b1 – dJ/db * alpha | |
| b1 <- b1 – sum((y – mtcars$vs) * mtcars$mpg) * alpha | |
| # b2 = b2 – dJ/db * alpha | |
| b2 <- b2 – sum((y – mtcars$vs) * mtcars$hp) * alpha | |
| # Solve for b0 + b1 * mtcars$mpg + b2 * mtcars$hp = 0 | |
| # mtcars$mpg = -(b2 * mtcars$hp + b0) / b1 | |
| db_points <- –(b2 * c(40, 400) + b0) / b1 | |
| # Plot decision boundary | |
| lines(c(40, 400), db_points, col = cols[i], lty = 2) | |
| # Save estimates over all iterations | |
| intercepts[i] <- b0 | |
| slopes1[i] <- b1 | |
| slopes2[i] <- b2 | |
| } | |
| title("Decision Boundary") | |
| plot(x=1:niter, intercepts, type = "l", lty=1, | |
| ylim = c(–1, 1), xlab = "Iteration No.", ylab = "Coefficient value") | |
| abline(h = 0, lty = 2, col="grey") | |
| lines(x=1:niter, slopes1, lty=3) | |
| lines(x=1:niter, slopes2, lty=4) | |
| legend("topright", | |
| legend = c(expression(beta[0]), | |
| expression(beta[1]), | |
| expression(beta[2])), | |
| lty = c(1, 3, 4), | |
| bty = "n") | |
| title("Coefficient Estimation") | |
| # Add colorbar | |
| z = matrix(1:niter, nrow = 1) | |
| image(1, 1:niter, z, | |
| col = cols, axes = FALSE, xlab = "", ylab = "") | |
| title("Iteration No.") | |
| axis(2, at = c(1, seq(20, niter, by=20))) |

Applying the same colouring scheme, we can see how gradient descent arrived at parameter estimates that minimise the prediction error!
Conclusion
Well done, we have just learned and applied gradient descent! Time to recap all the steps taken:
- A general problem definition was set to assign predictors, target, parameters and learning rate to well defined mathematical entities
- The MSE and the binary cross-entropy cost functions were introduced
- The chain rule of calculus was presented and applied to arrive at the gradient expressions based on linear and logistic regression with MSE and binary cross-entropy cost functions, respectively
- For demonstration, two basic modelling problems were solved in R using custom-built linear and logistic regression, each based on the corresponding gradient expressions
Finally, here are some ideas of where to go from here:
- Customisation. One major advantage of knowing the nuts and bolts of gradient descent is the high degree of customisation it allows. You could, for example, use the above recipe to add parameter regularisation to a cost function and derive the updated gradient expressions

- Interpretation. Although the focus of our two exercises was computational, I urge you to make sense of the resulting parameter estimates. It seems obvious that older trees have wider circumferences, not so much that V-shaped engines provide less mpg. Can we create models that explore causality? How much does a unit change in each predictor impact the target prediction? To me, these sort of questions serve as an enjoyable sanity check

- Experimentation. Use the code above as a template to experiment with different learning rates and number of iterations. Recall that the learning rate determines the step size of each parameter update, while the number of iterations determines how long learning takes place. Do your experiments conform to expected results?

- Benchmarking. It could be interesting to compare our estimation results with those obtained from using
lm()andglm()or similar. Do parameter estimates agree between? Which algorithm is faster? How do they differ?
I hope this tutorial has rekindled your interest in machine learning, inspired novel applications and demystified the underlying mathematics. As usual, please enter a comment below – a question, a suggestion, praise or criticism. Until next time!
Citation
de Abreu e Lima, F (2023). poissonisfish: Gradient descent in R. From https://poissonisfish.com/2023/04/11/gradient-descent/
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.