

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
The Bradley-Terry model
The Bradley-Terry model, named after R. A. Bradley and M. E. Terry, is a probability model for predicting the outcome of a paired comparison. Imagine that we have



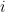






(Notice that the model implies that either i beats j or j beats i: there is no room for ties.) If we parameterize the scores by




Thus, estimating the parameters


One nice thing about the Bradley-Terry model is that it’s really easy to take home field advantage into account. Home field advantage amounts to including an intercept in the model (assuming that team i is the home team):


The Bradley-Terry model doesn’t just apply to sports teams: it applies whenever we are trying to rank items, e.g. which documents are most relevant to a user query.
An example: NBA regular season 2018-19
For the rest of this article, we demonstrate how to fit a Bradley-Terry model to NBA data. All the code in this post can be found in one script here.
Preparing the data
First, let’s import packages that we’ll use:
library(DBI) library(tidyverse) library(ggrepel) library(plotROC)
Next, let’s pull the relevant data from an SQLite database (your filepath to the data will probably be different from mine):
seasonYear <- 2018 # represents 2018-2019 season
# this filepath specific to my local drive
mainFile <- "../data/nba-kaggle-wyattowalsh/basketball.sqlite"
# get all regular season games (only relevant columns
# selected)
mydb <- dbConnect(RSQLite::SQLite(), mainFile)
df <- dbGetQuery(mydb, "SELECT * FROM Game")
dbDisconnect(mydb)
season_df <- df %>% mutate(GAME_DATE = as.Date(GAME_DATE),
SEASON = as.numeric(SEASON)) %>%
filter(SEASON == seasonYear) %>%
select(GAME_DATE, TEAM_NAME_HOME, TEAM_NAME_AWAY, WL_HOME, WL_AWAY) %>%
arrange(GAME_DATE)
head(season_df)
# GAME_DATE TEAM_NAME_HOME TEAM_NAME_AWAY WL_HOME WL_AWAY
# 1 2018-10-16 Golden State Warriors Oklahoma City Thunder W L
# 2 2018-10-16 Boston Celtics Philadelphia 76ers W L
# 3 2018-10-17 San Antonio Spurs Minnesota Timberwolves W L
# 4 2018-10-17 New York Knicks Atlanta Hawks W L
# 5 2018-10-17 Phoenix Suns Dallas Mavericks W L
# 6 2018-10-17 LA Clippers Denver Nuggets L W
The data contains information on which team is home and which is away: we can use that information when fitting the Bradley-Terry model with home field advantage.
To make our subsequent analysis and plots more readable, we get team names and abbreviations. Note that teams will only contain the team names from the 2018-19 season, while team_abbrev_df contains teams from all the seasons present in the original SQLite database.
# get team abbreviations and names
team_abbrev_df <- df %>% select(team = TEAM_NAME_HOME,
team_abbr = TEAM_ABBREVIATION_HOME) %>%
distinct()
teams <- sort(unique(season_df$TEAM_NAME_HOME))
Next, we make the data matrix needed for the Bradley Terry model. For each row of season_df representing one game, we need to turn that into a vector of 30 numbers. If team get_data_vec() does this for us, and we apply it to every row in season_df.
# get dataframe for Bradley-Terry model
get_data_vec <- function(home_team, away_team, teams) {
vec <- rep(0, length(teams))
vec[teams == home_team] <- 1
vec[teams == away_team] <- -1
vec
}
X <- apply(season_df, 1,
function(row) get_data_vec(row["TEAM_NAME_HOME"],
row["TEAM_NAME_AWAY"],
teams))
X <- t(X)
colnames(X) <- teams
dim(X)
# [1] 1230 30
Bundle X and the response (did team
y <- as.numeric(season_df$WL_HOME == "W") bt_df <- as.data.frame(cbind(X, y))
Fitting the Bradley-Terry model
Preparing the data was the hard part: fitting the model is simply logistic regression, which we can do with the glm() function:
# Bradley-Terry model with home advantage bt_mod <- glm(y ~ ., data = bt_df, family = binomial()) summary(bt_mod) # Call: # glm(formula = y ~ ., family = binomial(), data = bt_df) # # Deviance Residuals: # Min 1Q Median 3Q Max # -2.3657 -1.0417 0.5943 0.9370 2.0810 # # Coefficients: (1 not defined because of singularities) # Estimate Std. Error z value Pr(>|z|) # (Intercept) 0.45312 0.06451 7.024 2.15e-12 *** # `Atlanta Hawks` -0.14263 0.33801 -0.422 0.673045 # `Boston Celtics` 0.95279 0.33708 2.827 0.004704 ** # `Brooklyn Nets` 0.57338 0.33323 1.721 0.085313 . # `Charlotte Hornets` 0.42252 0.33290 1.269 0.204369 # `Chicago Bulls` -0.56384 0.35012 -1.610 0.107310 # `Cleveland Cavaliers` -0.77299 0.35977 -2.149 0.031668 * # `Dallas Mavericks` 0.18056 0.34024 0.531 0.595646 # `Denver Nuggets` 1.34069 0.34632 3.871 0.000108 *** # `Detroit Pistons` 0.51927 0.33477 1.551 0.120878 # `Golden State Warriors` 1.49502 0.35119 4.257 2.07e-05 *** # `Houston Rockets` 1.27371 0.34470 3.695 0.000220 *** # `Indiana Pacers` 0.88599 0.33580 2.638 0.008328 ** # `LA Clippers` 0.98431 0.33971 2.898 0.003761 ** # `Los Angeles Lakers` 0.39871 0.33801 1.180 0.238164 # `Memphis Grizzlies` 0.18822 0.33950 0.554 0.579314 # `Miami Heat` 0.42317 0.33174 1.276 0.202095 # `Milwaukee Bucks` 1.59581 0.35456 4.501 6.77e-06 *** # `Minnesota Timberwolves` 0.35609 0.33764 1.055 0.291591 # `New Orleans Pelicans` 0.15370 0.33992 0.452 0.651159 # `New York Knicks` -0.90066 0.36632 -2.459 0.013945 * # `Oklahoma City Thunder` 1.03916 0.34122 3.045 0.002323 ** # `Orlando Magic` 0.56597 0.33298 1.700 0.089184 . # `Philadelphia 76ers` 1.07406 0.34054 3.154 0.001611 ** # `Phoenix Suns` -0.68639 0.36436 -1.884 0.059590 . # `Portland Trail Blazers` 1.28427 0.34507 3.722 0.000198 *** # `Sacramento Kings` 0.49275 0.33739 1.460 0.144160 # `San Antonio Spurs` 0.97029 0.33981 2.855 0.004298 ** # `Toronto Raptors` 1.47941 0.34897 4.239 2.24e-05 *** # `Utah Jazz` 1.08503 0.34131 3.179 0.001478 ** # `Washington Wizards` NA NA NA NA # --- # Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 # # (Dispersion parameter for binomial family taken to be 1) # # Null deviance: 1662.6 on 1229 degrees of freedom # Residual deviance: 1441.9 on 1200 degrees of freedom # AIC: 1501.9 # # Number of Fisher Scoring iterations: 4
Some notes are in order:
- Since an intercept is included in the model, this is the Bradley-Terry model with home field advantage. We’ll see how to fit a model without an intercept later in this post.
- Notice that the Washington Wizards doesn’t have a coefficient associated with it. This is because the original model is unidentifiable: if we were to replace all the coefficients
Xbefore fitting the model. - Larger coefficients correspond to better teams. In the next code block, we examine the relationship between the Bradley-Terry coefficients and the team’s overall win percentage for the season:






# Compare BT coefficients with overall win percentage
coef_df <- data.frame(
team = teams,
beta = c(summary(bt_mod)$coefficients[2:length(teams), "Estimate"], 0)
)
# get team win percentages
home_df <- season_df %>% group_by(TEAM_NAME_HOME) %>%
summarize(home_win = sum(WL_HOME == "W"),
home_loss = sum(WL_HOME == "L"))
away_df <- season_df %>% group_by(TEAM_NAME_AWAY) %>%
summarize(away_win = sum(WL_AWAY == "W"),
away_loss = sum(WL_AWAY == "L"))
win_pct_df <- inner_join(home_df, away_df,
by = c("TEAM_NAME_HOME" = "TEAM_NAME_AWAY")) %>%
transmute(team = TEAM_NAME_HOME,
win = home_win + away_win,
loss = home_loss + away_loss) %>%
mutate(win_pct = win / (win + loss)) %>%
arrange(desc(win_pct)) %>%
left_join(team_abbrev_df)
win_pct_df %>% inner_join(coef_df) %>%
ggplot(aes(x = win_pct, y = beta)) +
geom_point() +
geom_text_repel(aes(label = team_abbr)) +
labs(x = "Win percentage", y = "Bradley-Terry beta",
title = "Bradley-Terry beta vs. Win %")

As we probably expected, there’s high agreement between the two measures of team quality. (Why not use win percentage right off the bat? That’s because win percentage depends on “strength of schedule”. A team that plays weaker teams is likely to have a win percentage that is biased upwards, and vice versa for a team that plays stronger teams. Win percentage does not account for this but the Bradley-Terry model does.)
(I also just noticed that there are some extraneous labels in the figure; it’s because some teams have had multiple abbreviations throughout the history of the game, and I should have filtered them out from team_abbrev_df.)
Bradley-Terry model without home advantage
Fitting the model without home advantage is the same as performing logistic regression without an intercept. This is easy to do: we just add + 0 in the formula argument.
bt_mod1 <- glm(y ~ . + 0, data = bt_df, family = binomial())
Let’s compare the coefficients for the teams from the two models:
coef_df1 <- data.frame(
team = teams,
beta = c(summary(bt_mod1)$coefficients[, "Estimate"], 0)
)
plot(coef_df$beta, coef_df1$beta, pch = 16,
xlab = "Beta with home adv.",
ylab = "Beta w/o home adv.")
abline(0, 1, col = "red", lty = 2)

The dotted red line is the


Predicting the second half of the season
We end off this post by showing how to use the Bradley-Terry model to make predictions. We split our data into two halves: we will use the first half of the season as training data, and will use the model to predict the results for the second half of the season.
n_train <- nrow(X) / 2 train_df <- bt_df[1:n_train, ] test_df <- bt_df[(n_train + 1):nrow(X), ]
Code for training and making predictions:
train_mod_home <- glm(y ~ ., data = train_df, family = binomial()) pred_home <- predict(train_mod_home, newdata = test_df, type = "response") train_mod_no_home <- glm(y ~ . + 0, data = train_df, family = binomial()) pred_no_home <- predict(train_mod_no_home, newdata = test_df, type = "response")
Let’s compare the predictions made by the two models:
plot(pred_home, pred_no_home, pch = 16, cex = 0.5,
xlab = "Prob. of home win (model w. home adv.)",
ylab = "Prob. of home win (model w/o home adv.)")
abline(0, 1)

As you might expect, the model that takes home advantage into account always gives a higher predicted probability of a home win. What’s interesting is that the size of this home advantage changes across the range: it is largest for probabilities around 0.5 and smallest for probabilities close to the extremes.
The code below plots the ROC curves for the two models on the test data. In this situation it looks like whether we incorporate home advantage or not doesn’t make much of a difference.
pred_df <- data.frame(
truth = test_df$y,
pred_home = pred_home,
pred_no_home = pred_no_home
) %>%
pivot_longer(pred_home:pred_no_home,
names_to = "model",
values_to = "prediction")
roc_plot <- ggplot(pred_df) +
geom_roc(aes(d = truth, m = prediction, color = model), labels = FALSE)
roc_plot +
labs(x = "True positive fraction",
y = "False positive fraction",
title = "Test set ROC plots") +
geom_abline(slope = 1, intercept = 0, linetype = "dashed") +
theme(legend.position = "bottom")

We can use the calc_auc() function from the plotROC package to compute the area under the curve (AUCs) from the plot object:
calc_auc(roc_plot) # PANEL group AUC # 1 1 1 0.7120678 # 2 1 2 0.7133042
We can also compute the Brier scores for the two models:
mean((pred_home - test_df$y)^2) # [1] 0.2130266 mean((pred_no_home - test_df$y)^2) # [1] 0.2186777
Recall that smaller Brier scores are better, and that a model that always outputs probability 0.5 has a Brier score of 0.25. Looking at the Brier scores and AUCs, it looks like these models are better than random guessing, but not a whole lot better.
Update (2022-02-01): In private correspondence, Justin Dyer correctly points out that it’s not clear a priori that Brier scores of ~0.21 are bad: we should benchmark the scores against other models, or the Brier scores implied by bookmaking odds. Presumably bookmaking odds incorporate a lot more information than the simple Bradley-Terry model above! We’ll leave this for a future blog post.
References:
- Wikipedia. Bradley-Terry model.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.