

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
In the last article of the current year, we will examine and compare some of the tree algorithms for the classification. The dataset we are going to use for this will be the answers given to the loan applicants and their evaluated features for it.
library(tidyverse)
library(tidymodels)
library(tsibble)
library(C50)
library(caret)
library(pROC)
data <- readr::read_csv("https://raw.githubusercontent.com/mesdi/trees/main/credit.csv")
The first algorithm we will talk about is the C5.0 decision tree. This method is based upon entropy to select optimal features to split upon. The high entropy means that there is little or no homogeneity within the set of class values. The algorithm aims to find splits that reduce the entropy. (Lantz, 2015: 133)


- The




The algorithm calculates the difference in the entropy of the last two segments on a feature, F, to determine the change of homogeneity. This is called information gain. The higher the information gain the better the homogeneity in groups after the split. (Lantz, 2015: 134)

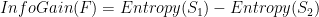
Now after some brief information, we can begin the fitting process.
#Building tibble dataset
df <-
data %>%
mutate_if(sapply(data,is_character),as_factor) %>%
mutate(default= default %>% factor(labels=c("no","yes")))
#Creating train and test set
set.seed(36894)
df_split <- initial_split(df, prop = 9/10, strata = "default")
df_train <- training(df_split)
df_test <- testing(df_split)
#C5.0 model
model_c50 <- C5.0(df_train[-17],df_train$default,trials = 10)
pred_c50 <- predict(model_c50, df_test)
confusionMatrix(pred_c50,df_test$default)
#Confusion Matrix and Statistics
# Reference
#Prediction no yes
# no 65 12
# yes 5 18
# Accuracy : 0.83
# 95% CI : (0.7418, 0.8977)
# No Information Rate : 0.7
# P-Value [Acc > NIR] : 0.002163
No information rate(NIR) means that the largest proportion of the class levels in our response variable. So, when we look at the above results, we can see this rate is %70 and, our accuracy result is higher than NIR at the %5 significance level(P-Value: 0.002163 < 0.05). Nevertheless, the type 2 error rate is quite annoying (12/30).
The second tree algorithm we are going to use is decision_tree() from parsnip.
#Decision trees model
model_dt <-
decision_tree() %>%
set_mode("classification") %>%
set_engine("rpart") %>%
fit(default ~ ., data=df_train)
pred_dt <- predict(model_dt, df_test)
confusionMatrix(pred_dt$.pred_class, df_test$default)
#Confusion Matrix and Statistics
# Reference
#Prediction no yes
# no 65 17
# yes 5 13
# Accuracy : 0.78
# 95% CI : (0.6861, 0.8567)
# No Information Rate : 0.7
# P-Value [Acc > NIR] : 0.04787
It looks like the accuracy and type 2 error rate are much worse than the C5.0 function. The final algorithm is the boosted trees.
#Boosted trees model
model_bt <-
boost_tree(trees = 100) %>%
set_mode("classification") %>%
set_engine("C5.0") %>%
fit(default ~ ., data=df_train)
pred_bt <- predict(model_bt, df_test)
confusionMatrix(pred_bt$.pred_class, df_test$default)
#Confusion Matrix and Statistics
# Reference
#Prediction no yes
# no 63 14
# yes 7 16
# Accuracy : 0.79
# 95% CI : (0.6971, 0.8651)
# No Information Rate : 0.7
# P-Value [Acc > NIR] : 0.02883
It is seen a slight improvement, but not like the first one.
Finally, we will be comparing ROC curves with the help of the ggroc function from the pROC package.
#Multiple ROC curve
roc_df <- tibble(
c50=pred_c50 %>% ordered(),
dt=pred_dt$.pred_class %>% ordered(),
bt=pred_bt$.pred_class %>% ordered(),
response=df_test$default
)
roc.list <- roc(response ~ dt + bt + c50, data = roc_df)
roc_values <-
lapply(roc.list,"[[","auc") %>%
as.numeric() %>%
round(2)
ggroc(roc.list) +
geom_line(size=2)+
geom_abline(slope=1,
intercept = 1,
linetype = "dashed",
alpha=0.5,
size=2,
color = "grey") +
scale_color_brewer(palette = "Set2",
labels=c(
paste0("DT: ", roc_values[1]),
paste0("BT: ", roc_values[2]),
paste0("C50: ",roc_values[3]))) +
guides(color= guide_legend(title = "Models AUC Scores")) +
theme_minimal() +
coord_equal()


The above ROC curves plot and the AUC results confirm the accuracy results we found earlier. It is understood, except for the C50 model, the other two models seem to be inefficient.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.