
Maximum Smoothness Forward Rates by Inverse Matrix using R
[This article was first published on K & L Fintech Modeling, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
This post solves Adams and Deventer (1994) maximum smoothness forward rate curve as the matrix inversion of equality constrained quadratic programming problems. We implement R code for this model and elaborate on how to get monthly forward and spot rates from the calibrated parameters. Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Maximum Smoothness Forward Rates
Using Adams and Deventer (1994, revised 2010) approach, output of this post is the following figure describing maximum smoothness forward rate curve with spot curve.

At first, details of maximum smoothness forward rate curve and the solution by using an optimization are explained in the previous post below.
We can solve Adams and Deventer (1994) maximum smoothness forward rate curve by matrix inversion. This solution is possible due to the fact that this problem can be formulated as the equality constrained quadratic programming problem.
Quadratic Programming with Linear Equality Constraints
Equality-constrained quadratic program (QP) is a QP where only linear equality constraints are present with quadratic terms absent.
\[\begin{align} &\min_{x}& &f(x) = \frac{1}{2}x^T Q x + c^T x \\ &s.t. & & Ax = b \end{align}\]
The first-order condition (FOC) for this problem constitutes the following linear system, which is derived from setting up the Lagrangian.
\[\begin{align} \underbrace{ \left[\begin{array}{ccc} Q & -A^T \\ A & 0 \\ \end{array}\right]}_{\text{KKT matrix}} \begin{bmatrix} x^* \\ \lambda^* \end{bmatrix} &= \begin{bmatrix} -c \\ b \end{bmatrix} \end{align}\] Here, matrix in LHS is called a KKT(Karush–Kuhn–Tucker) matrix. We can solve the above linear system by using the inverse matrix of the LHS coefficient matrix. The derivation of it is as follows.
Using Lagrange multiplier (\(\lambda\)), the optimization problems can be converted to the following Lagrangian. \[\begin{align} f(x,\lambda) = \frac{1}{2}x^T Q x + c^T x + \lambda^T(Ax – b) \end{align}\]
The FOC with respect to \(x\) and \(\lambda\) is
\[\begin{align} &\frac{\partial f(x,\lambda)}{\partial x} = Qx + c + A^T\lambda = 0 \\ &\frac{\partial f(x,\lambda)}{\partial \lambda} = Ax – b = 0 \end{align}\]
This two set of equations are reduced to the above vector-matrix representation and we use the inverse matrix of \(A\) to get an vector of optimal decision variables \(x\).
\[\begin{align} X = \begin{bmatrix} x^* \\ \lambda^* \end{bmatrix} &= \left[\begin{array}{ccc} Q & -A^T \\ A & 0 \\ \end{array}\right]^{-1} \begin{bmatrix} -c \\ b \end{bmatrix} \end{align}\]
Objecive Function
As can be seen in previous blog, these quadratic terms can be summarized as the following vector-matrix notation (\(\Delta t_i^n= t_i^n – t_{i-1}^n\)).
\[\begin{align} \int_{t_{i-1}}^{t_i} [f^{”}(t)]^2 dt = x_i^T Q_i x_i \end{align}\] where \[\begin{align} x_i = \begin{bmatrix} a_i \\ b_i \\ c_i \\ d_i \\ e_i \end{bmatrix}, Q_i = \left[\begin{array}{ccc} \frac{144}{5} \Delta t_i^5 & 18 \Delta t_i^4 & 8 \Delta t_i^3 & 0 & 0 \\ 18 \Delta t_i^4 & 12 \Delta t_i^3 & 6 \Delta t_i^2 & 0 & 0 \\ 8 \Delta t_i^3 & 6 \Delta t_i^2 & 4 \Delta t_i & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ \end{array}\right] \end{align}\]
Therefore, the objective function is the sum of i-th objective functions.
\[\begin{align} x^T Q x \end{align}\] where \[\begin{align} x = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_{m-1} \\ x_m \end{bmatrix}, Q = \left[\begin{array}{ccc} Q_1 & 0 & … & 0 & 0 \\ 0 & Q_2 & … & 0 & 0 \\ \vdots & \vdots & \ddots & \vdots &\vdots \\ 0 & 0 & … & Q_{m-1} & 0 \\ 0 & 0 & … & 0 & Q_m \\ \end{array}\right] \end{align}\]
In this way, concatenation of the objective functions in each segment consist of \(Q\) matrix in the above QP.
Linear Equality Constraints
As can be seen also in previous blog, for \(\Delta k_{i+1}= k_{i+1} – k_{i}, \Delta t_i^n= t_i^n – t_{i-1}^n\), linear equality constraints are as follows.
1) continuity or smoothness at the joints (internal knots)\[\begin{align} 0 &= \Delta a_{i+1} t^4 + \Delta b_{i+1} t^3 + \Delta c_{i+1} t^2 + \Delta d_{i+1} t + \Delta e_{i+1} \\ 0 &= 4\Delta a_{i+1} t^3 + 3\Delta b_{i+1} t^2 + 2\Delta c_{i+1} t + d\Delta _{i+1} \\ 0 &= 12\Delta a_{i+1} t^2 + 6\Delta b_{i+1} t + 2\Delta c_{i+1} \\ 0 &= 24\Delta a_{i+1} t + 6\Delta b_{i+1} \end{align}\]
2) market price fitting at the observed points\[\begin{align} -log\left[ \frac{P_i}{P_{i-1}}\right] = \frac{1}{5} a_i \Delta t_i^5 + \frac{1}{4} b_i \Delta t_i^4 + \frac{1}{3} c_i \Delta t_i^3 + \frac{1}{2} d_i \Delta t_i^2 + e_i \Delta t_i \end{align}\]
2) Additional constraints for smoothness
\[\begin{align} f(0) = r(0), \quad f^{‘}(0) = 0 \\ f^{‘}(T) = 0 , \quad f^{”}(T) = 0 \end{align}\]
These linear equality constraints consist of \(A\) matrix in the above QP.
Fitting Yield Curve as a Quadratic Programming with Linear Equality Constraints
In our problem, the objective function consists of quadratic terms and the linear constraints are equality restrictions. Therefore, this can be represented as a equality-constrained QP.
\[\begin{align} \left[\begin{array}{ccc} Q & -A^T \\ A & 0 \\ \end{array}\right] \begin{bmatrix} x^* \\ \lambda^* \end{bmatrix} &= \begin{bmatrix} -c \\ b \end{bmatrix} \end{align}\] Using Adams and Deventer (2010) data, let’s construct left hand side KKT coefficient matrix and right hand side vector. The former consists of \(Q\), \(A\) and \(-A^T\) and the latter is made from \(b\) and \(-c\). Of course, the unknown \(X\) vector contains 25 coefficients of forward rate equations.
a1, b1, c1, d1, e1, a2, b2, c2, d2, e2, a3, b3, c3, d3, e3, a4, b4, c4, d4, e4, a5, b5, c5, d5, e5
Let’s construct three sub matrices : \(Q\), \(A\) and \(-A^T\).
\(Q\) matrix is of the next form. For example, entry of (1,1) is 0.028125 = (144/5)*(0.25-0)^5. Values of remaining entries are calculated by using the objective function and constraints.

\(A\) matrix is of the following form.
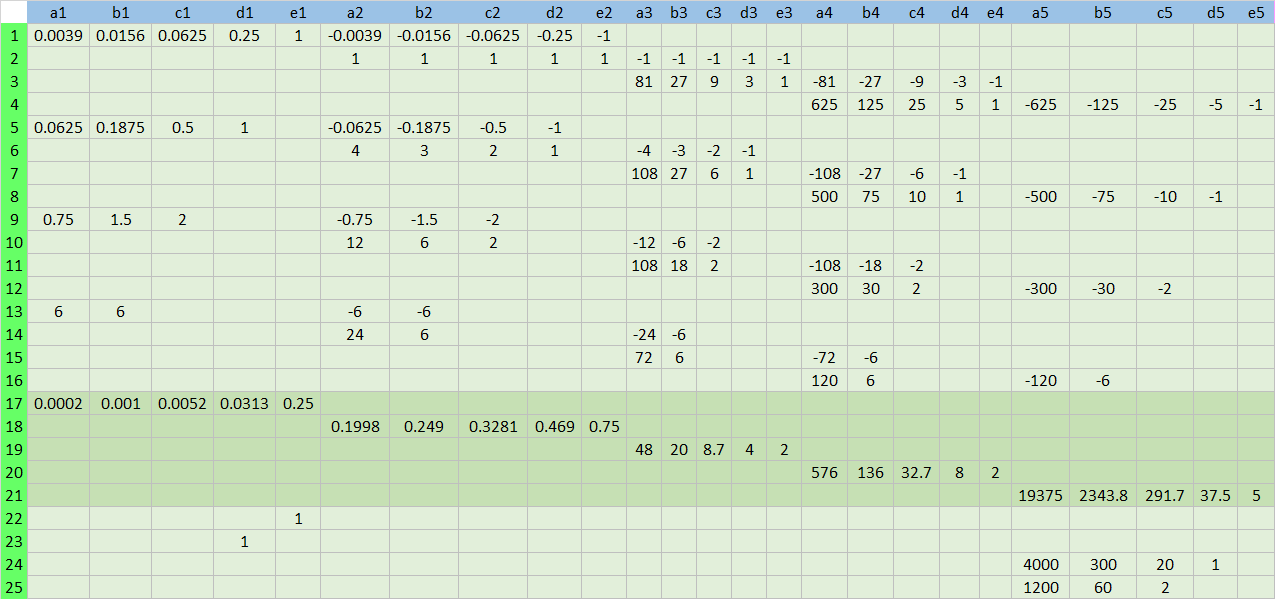
Its minus transpose, \(-A^T\) is
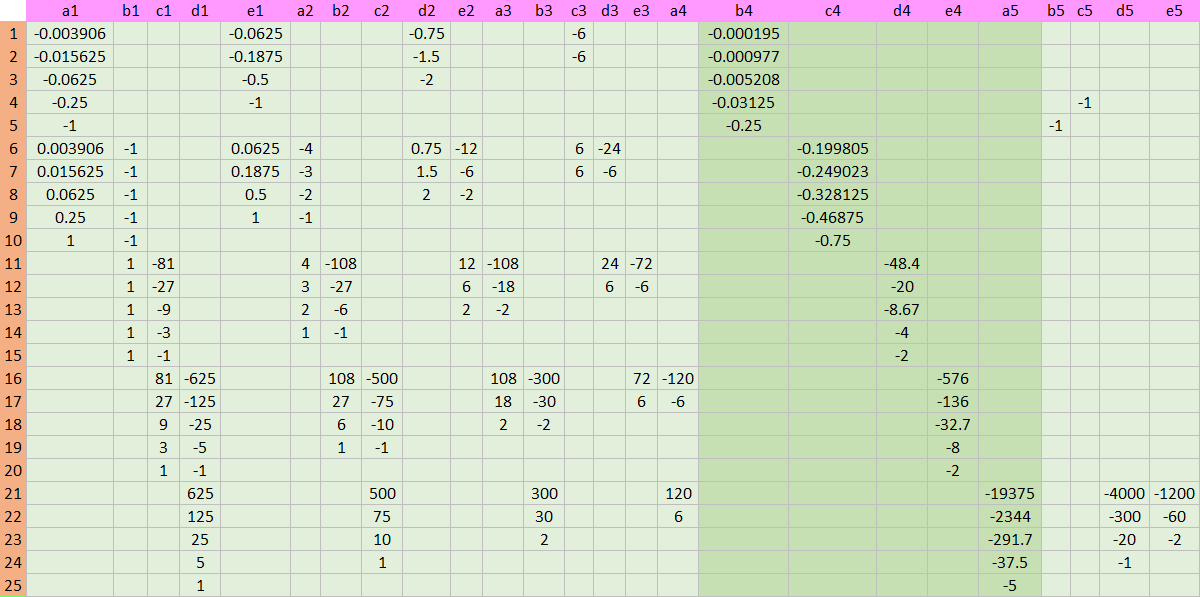
As vector \(c\) is a zero vector and vector \(b\) has some values which are derived from bond price matching conditions, the RHS vector consists of the following numbers.
0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0.012 , 0.033125 , 0.12 , 0.0975 , 0.3875 , 0.04 , 0 , 0 , 0
Finally, we can construct LHS coefficient matrix and RHS vector as follows.

As we know value of each entry, entries that have numerical value are colored black, blue and red. In LHS matrix, we display empty cells as zero values (0).
R code
The following R code implements the maximum smoothness forward curve by using an inverse matrix.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 | #========================================================# # Quantitative ALM, Financial Econometrics & Derivatives # ML/DL using R, Python, Tensorflow by Sang-Heon Lee # # https://kiandlee.blogspot.com #——————————————————–# # Adams and Deventer Maximum Smoothness Forward Curve # using the inverse matrix #========================================================# graphics.off() # clear all graphs rm(list = ls()) # remove all files from your workspace # Input : market zero rate, maturity df.mkt <– data.frame( mat = c(0.25, 1, 3, 5, 10), zrc = c(4.75, 4.5, 5.5, 5.25, 6.5)/100 ) # number of maturity n <– length(df.mkt$mat) # add 0-maturity zero rate (assumption) #df <- rbind(c(0, df.mkt$zrc[1]), df.mkt) df <– rbind(c(0, 0.04), df.mkt) # discount factor df$DF <– with(df, exp(–zrc*mat)) # -ln(P(t(i)/t(i-1))) df$mln <– c(NA,–log(df$DF[1:n+1]/df$DF[1:n])) # ti^n df$t5 <– df$mat^5 df$t4 <– df$mat^4 df$t3 <– df$mat^3 df$t2 <– df$mat^2 df$t1 <– df$mat^1 df$t0 <– 1 # dti = ti^n-(ti-1)^n df$dt5 <– c(NA,df$t5[1:n+1] – df$t5[1:n]) df$dt4 <– c(NA,df$t4[1:n+1] – df$t4[1:n]) df$dt3 <– c(NA,df$t3[1:n+1] – df$t3[1:n]) df$dt2 <– c(NA,df$t2[1:n+1] – df$t2[1:n]) df$dt1 <– c(NA,df$t1[1:n+1] – df$t1[1:n]) # construction linear system mQ <– mA <– matrix(0, nrow = n*n, ncol = n*n) vC <– vB <– rep(0,n*n) # Objective function for(r in 1:n) { mQ[((r–1)*n+1):(r*n–2),((r–1)*n+1):(r*n–2)] <– matrix(with(df[r+1,], c(144/5*dt5, 18*dt4, 8*dt3, 18*dt4, 12*dt3, 6*dt2, 8*dt3, 6*dt2, 4*dt1)),3,3) } # Smoothness Constraints : f, f’, f”, f”’ r = 1; for(t in 1:(n–1)) { mA[(r–1)*(n–1)+t,(1+(t–1)*n):(t*n–r+1)] <– with(df[t+1,], c(t4, t3, t2, t1, t0)) mA[(r–1)*(n–1)+t,(1+t*n):((t+1)*n–r+1)] <– with(df[t+1,], –c(t4, t3, t2, t1, t0)) } r = 2; for(t in 1:(n–1)) { mA[(r–1)*(n–1)+t,(1+(t–1)*n):(t*n–r+1)] <– with(df[t+1,], c(4*t3, 3*t2, 2*t1, t0)) mA[(r–1)*(n–1)+t,(1+t*n):((t+1)*n–r+1)] <– with(df[t+1,], –c(4*t3, 3*t2, 2*t1, t0)) } r = 3; for(t in 1:(n–1)) { mA[(r–1)*(n–1)+t,(1+(t–1)*n):(t*n–r+1)] <– with(df[t+1,], c(12*t2, 6*t1, 2*t0)) mA[(r–1)*(n–1)+t,(1+t*n):((t+1)*n–r+1)] <– with(df[t+1,], –c(12*t2, 6*t1, 2*t0)) } r = 4; for(t in 1:(n–1)) { mA[(r–1)*(n–1)+t,(1+(t–1)*n):(t*n–r+1)] <– with(df[t+1,], c(24*t1, 6*t0)) mA[(r–1)*(n–1)+t,(1+t*n):((t+1)*n–r+1)] <– with(df[t+1,], –c(24*t1, 6*t0)) } # bond price fitting constraints r = 5; for(t in 1:n) { mA[(r–1)*(n–1)+t,(1+(t–1)*n):(t*n)] <– with(df[t+1,],c(dt5/5,dt4/4,dt3/3,dt2/2,dt1)) } # additional four constraints r = (n–1)*4 + n+1; c = n ; mA[r,c] <– 1 r = (n–1)*4 + n+2; c = n–1; mA[r,c] <– 1 r = (n–1)*4 + n+3; c = (n*4+1):(n*4+4) mA[r,c] <– with(df[n+1,], c(4*t3, 3*t2, 2*t1, t0)) r = (n–1)*4 + n+4; c = (n*4+1):(n*4+3) mA[r,c] <– with(df[n+1,], c(12*t2, 6*t1, 2*t0)) # RHS vector vC <– rep(0,n*n) vB <– c(rep(0,(n–1)*(n–1)), df$mln[2:(n+1)], df$zrc[1],0,0,0) # concatenation of matrix and vector AA = rbind(cbind(mQ, –t(mA)), cbind(mA, matrix(0,n*n,n*n))) BB = c(–vC, vB) # solve linear system by using inverse matrix XX = solve(AA)%*%BB XX | cs |
Running the above R code, we can obtain the following results which are the same as that of the previous post.
1 2 3 4 5 6 7 8 | > df.mkt[,c(“a”,”b”,”c”,”d”,”e”)] a b c d e 1 3.7020077927 -3.343981336 0.8481712 1.235996e-15 0.04000000 2 -0.1354629834 0.493489440 -0.5908803 2.398419e-01 0.02500988 3 0.0080049888 -0.080382448 0.2699275 -3.340300e-01 0.16847785 4 -0.0024497295 0.045074170 -0.2946273 7.950796e-01 -0.67835432 5 0.0002985362 -0.009891144 0.1176126 -5.790532e-01 1.03931174 | cs |
Monthly Spot and Forward Curves
As noted in the previous post, in a piece-wise linear form, the spot and forward rate are as follows.
\[\begin{align} f(t_i) &= a_i t^4 + b_i t^3 + c_i t^2 + d_i t + e_i \\ y(t_i) &= \frac{1}{t_i}\sum_{j=1}^{i}\left( \frac{1}{5} a_j \Delta t_j^5 + \frac{1}{4} b_j \Delta t_j^4 + \frac{1}{3} c_j \Delta t_j^3 + \frac{1}{2} d_j \Delta t_j^2 + e_j \Delta t_j \right) \end{align}\]
Using these equations, monthly forward rate and zero curve can be obtained by using the following R code.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | # save calibrated parameters for(i in 1:n) { df.mkt[i,c(“a”,“b”,“c”,“d”,“e”)] <– XX[((i–1)*n+1):(i*n)] } # monthly forward rate and spot rate df.mm <– data.frame( mat = seq(0,10,1/12),y = NA, fwd = NA) # which segment df.mm$seg_no <– apply(df.mm, 1, function(x) min(which(x[1]<=df.mkt$mat)) ) # ti^n df.mm$t5 <– df.mm$mat^5 df.mm$t4 <– df.mm$mat^4 df.mm$t3 <– df.mm$mat^3 df.mm$t2 <– df.mm$mat^2 df.mm$t1 <– df.mm$mat^1 df.mm$t0 <– 1 nr <– nrow(df.mm) # number of rows # dti = ti^n-(ti-1)^n df.mm$dt5 <– c(NA,df.mm$t5[2:nr] – df.mm$t5[1:(nr–1)]) df.mm$dt4 <– c(NA,df.mm$t4[2:nr] – df.mm$t4[1:(nr–1)]) df.mm$dt3 <– c(NA,df.mm$t3[2:nr] – df.mm$t3[1:(nr–1)]) df.mm$dt2 <– c(NA,df.mm$t2[2:nr] – df.mm$t2[1:(nr–1)]) df.mm$dt1 <– c(NA,df.mm$t1[2:nr] – df.mm$t1[1:(nr–1)]) # monthly maximum smoothness forward curve df.mm$fwd[1] <– df.mkt$e[1] # time 0 forward rate df.mm$y[1] <– df.mkt$e[1] # time 0 yield temp_y_sum <– 0 for(i in 2:nr) { mat <– df.mm$mat[i] seg_no <– df.mm$seg_no[i] # which segment v_tn <– df.mm[i,c(“t4”,“t3”,“t2”,“t1”,“t0”)] v_dtn <– df.mm[i,c(“dt5”,“dt4”,“dt3”,“dt2”,“dt1”)] v_abcde <– df.mkt[seg_no, c(“a”,“b”,“c”,“d”,“e”)] # monthly maximum smoothness forward curve df.mm$fwd[i] <– sum(v_abcde*v_tn) # monthly yield curve temp_y_sum <– temp_y_sum + sum(c(1/5,1/4,1/3,1/2,1)*v_abcde*v_dtn) df.mm$y[i] <– (1/mat)*temp_y_sum } # Draw Graph x11(width=8, height = 6); plot(df.mkt$mat, df.mkt$zrc, col = “red”, cex = 1.5, ylim=c(0,0.12), xlab = “Maturity”, ylab = “Interest Rate”, lwd = 10, main = “Monthly Maximum Smoothness Forward Rates and Spot Rates”) text(df.mkt$mat, df.mkt$zrc–c(0.015,–0.01,rep(0.01,3)), labels=c(“3M”,“1Y”,“3Y”,“5Y”,“10Y”), cex= 1.5) lines(df.mm$mat, df.mm$y , col = “blue” , lwd = 5) lines(df.mm$mat, df.mm$fwd, col = “green”, lwd = 10) legend(“bottomright”,legend=c(“Spot Curve”, “Forward Curve”, “Input Spot Rates”), col=c(“blue”,“green”,“red”), pch = c(15,15,16), border=“white”, box.lty=0, cex=1.5) | cs |
Drawing spot and forward curve from the maximum smoothness principle results in the following figure. These spot curve is market consistent as it fits market spot rates exactly. The forward curve shows very smooth behavior.
Shortcut Method
In this problem, I guess that we can use \(x = A^{-1}b\) as shortcut method. It is because of the fact that as \(x\) is determined by \( Ax – b \rightarrow x = A^{-1}b \), \(\lambda\) vector is determined by some arbitrary \(Q\) matrix except for the zero or null matrix.
\[\begin{align} Qx + A^T\lambda = 0 \rightarrow \lambda = (A^T)^{-1}Qx \end{align}\]
In the above equation, if \(A\) and \(x\) are known, even though we use non-zero some arbitrary \(Q\) matrix, we can get the same \(x\) with different \(\lambda\). I think this is due to the fact that our problem is exactly identified with only linear equality constraints and there is no perturbation process. The following R code consists of the linear system solution by using inverse of sub matrix \(mA\) not \(A\).
1 2 3 4 | XX2 <– solve(mA)%*%vB cbind(XX[1:(n*n)],XX2,XX[1:(n*n)]–XX2) sum(abs(XX[1:(n*n)]–XX2)) | cs |
Lagrange multiplier is important concept as it is interpreted as shadow price or marginal utility in financial economics. But in the yield curve fitting context, it is of less significance. If there is no additional constraints and our purpose is to obtain only \(x\), I think it suffice to solve \(Ax = b\). Of course if we impose additional constraints, this shortcut will be impossible. This argument is my guess so that it is subject to correction if any inconsistency is found.
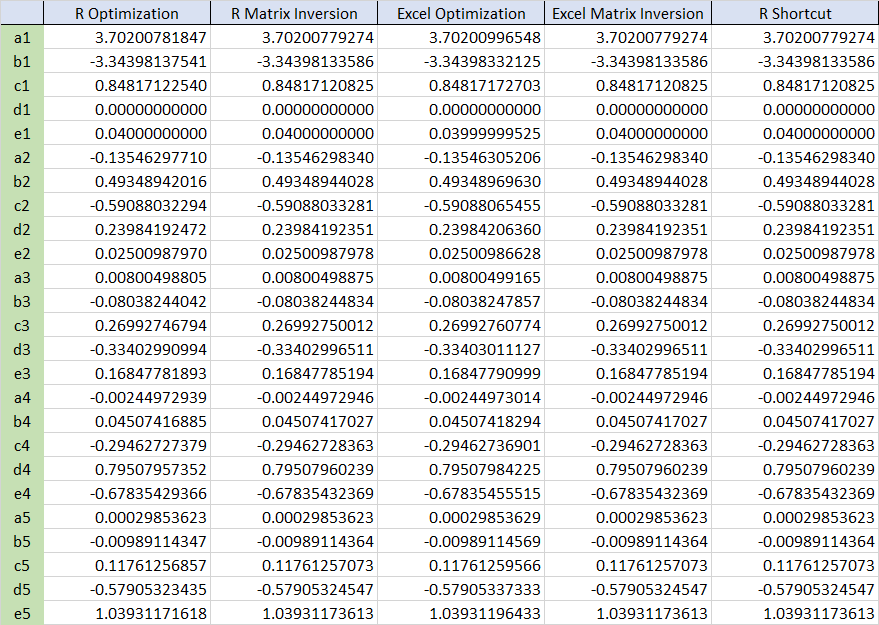
Finally, we compare forward curves from 1) R optimization, 2) Excel optimization, 3) R matrix inversion, 4) Excel matrix inversion, 5) R shortcut method. As we use Excel to illustrate the structure of sub and whole matrix or vector, coefficients can be found by using Excel solver.
The following table shows that there are negligible differences among estimated coefficients from 5 methods in the numerical perspective.
Concluding Remarks
From this post, we have implemented Adams and Deventer’s maximum smoothness forward curve. This powerful method will be used for various area, for example, interest rate trading desk since this department have a need to use exact and smooth forward curve. \(\blacksquare\)
To leave a comment for the author, please follow the link and comment on their blog: K & L Fintech Modeling.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.