

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
The Tukey loss function
The Tukey loss function, also known as Tukey’s biweight function, is a loss function that is used in robust statistics. Tukey’s loss is similar to Huber loss in that it demonstrates quadratic behavior near the origin. However, it is even more insensitive to outliers because the loss incurred by large residuals is constant, rather than scaling linearly as it would for the Huber loss.
The loss function is defined by the formula

![\begin{aligned} \ell (r) = \begin{cases} \frac{c^2}{6} \left(1 - \left[ 1 - \left( \frac{r}{c}\right)^2 \right]^3 \right) &\text{if } |r| \leq c, \\ \frac{c^2}{6} &\text{otherwise}. \end{cases} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cell+%28r%29+%3D+%5Cbegin%7Bcases%7D+%5Cfrac%7Bc%5E2%7D%7B6%7D+%5Cleft%281+-+%5Cleft%5B+1+-+%5Cleft%28+%5Cfrac%7Br%7D%7Bc%7D%5Cright%29%5E2+%5Cright%5D%5E3+%5Cright%29+%26%5Ctext%7Bif+%7D+%7Cr%7C+%5Cleq+c%2C+%5C%5C+%5Cfrac%7Bc%5E2%7D%7B6%7D+%26%5Ctext%7Botherwise%7D.+%5Cend%7Bcases%7D+%5Cend%7Baligned%7D&bg=ffffff&%23038;fg=333333&%23038;s=0&%23038;c=20201002)
In the above, I use





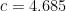
You may be wondering why the loss function has a somewhat unusual constant of

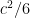

![\begin{aligned} \ell' (r) = \begin{cases} r \left[ 1 - \left( \frac{r}{c}\right)^2 \right]^2 &\text{if } |r| \leq c, \\ 0 &\text{otherwise}. \end{cases} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cell%27+%28r%29+%3D+%5Cbegin%7Bcases%7D+r+%5Cleft%5B+1+-+%5Cleft%28+%5Cfrac%7Br%7D%7Bc%7D%5Cright%29%5E2+%5Cright%5D%5E2+%26%5Ctext%7Bif+%7D+%7Cr%7C+%5Cleq+c%2C+%5C%5C+0+%26%5Ctext%7Botherwise%7D.+%5Cend%7Bcases%7D+%5Cend%7Baligned%7D&bg=ffffff&%23038;fg=333333&%23038;s=0&%23038;c=20201002)
In the field of robust statistics, the derivative of the loss function is often of more interest than the loss function itself. In this field, it is common to denote the loss function and its derivative by the symbols

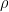


Plots of the Tukey loss function
Here is R code that computes the Tukey loss and its derivative:
tukey_loss <- function(r, c) {
ifelse(abs(r) <= c,
c^2 / 6 * (1 - (1 - (r / c)^2)^3),
c^2 / 6)
}
tukey_loss_derivative <- function(r, c) {
ifelse(abs(r) <= c,
r * (1 - (r / c)^2)^2,
0)
}
Here are plots of the loss function and its derivative for a few values of the
r <- seq(-6, 6, length.out = 301)
c <- 1:3
# plot of tukey loss
library(ggplot2)
theme_set(theme_bw())
loss_df <- data.frame(
r = rep(r, times = length(c)),
loss = unlist(lapply(c, function(x) tukey_loss(r, x))),
c = rep(c, each = length(r))
)
ggplot(loss_df, aes(x = r, y = loss, col = factor(c))) +
geom_line() +
labs(title = "Plot of Tukey loss", y = "Tukey loss",
col = "c") +
theme(legend.position = "bottom")


# plot of tukey loss derivative
loss_deriv_df <- data.frame(
r = rep(r, times = length(c)),
loss_deriv = unlist(lapply(c, function(x) tukey_loss_derivative(r, x))),
c = rep(c, each = length(r))
)
ggplot(loss_deriv_df, aes(x = r, y = loss_deriv, col = factor(c))) +
geom_line() +
labs(title = "Plot of derivative of Tukey loss", y = "Derivative of Tukey loss",
col = "c") +
theme(legend.position = "bottom")

Some history
According to what I could find, Tukey’s loss was proposed by Beaton & Tukey (1974) (Reference 2), but not in the form I presented above. Rather, they proposed weights to be used in an iterative reweighted least squares (IRLS) procedure.
References:
- Belagiannis, V., et al. (2015). Robust Optimization for Deep Regression.
- Beaton, A. E., and Tukey, J. W. (1974). The Fitting of Power Series, Meaning Polynomials, Illustrated on Band-Spectroscopic Data.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.