


Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
First of all, we need to explain a few things in more detail.
(Re)Introduction
pxWorks is an open source programming platform that enables the following, among other things:
- Implement data-mining programming logic in a clear fashion by modelling code around the flow of data.
- Use a mixture of any scripting languages in the same project seamlessly without introducing any intermediary code or any extra packages. (Our examples will be mostly written in R.)
- Delegate code writing with an assurance that the written code will be transparent and easy to follow and to debug.
- Create prototypes quickly and easily.
Programming Logic (Control Flow) in pxWorks
Any computer program can be represented by a graph. In pxWorks, graph nodes represent operations and graph edges represent the direction of control flow.
To enable programming loops without making logic complicated, the platform uses just two types of connections: unconditional and conditional.
The simplest program is the one that uses unconditional connections. Such connections are represented on the canvas by grey lines. The graph with only unconditional connections represents a simple program in which each node that has inputs waits until all the code blocks associated with connected inputs have been processed.
Nodes that have conditional inputs allow to introduce loops into control flow. Conditional connections are represented by magenta lines. Nodes that have both unconditional and conditional input connections wait for their turn to execute the code based on the following rule: either all the unconditionally connected nodes have been (re)calculated or at least one conditional node has been (re)calculated and generated an input file.
So in the first case, with unconditional links, the triggering of the code takes place regardless of whether an input file is generated for the dependent block (hence the execution is unconditional).
In the second case, with conditional links, the triggering of the code takes place only on condition that an input file has been generated after running the earlier block.
Even more details on this subject can be found here.
The First Design Pattern: Heartbeat

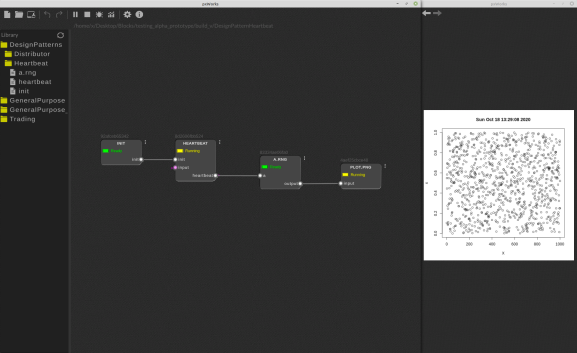
Before proceeding any further, you might want to get the example file here. (To run the example, you will need to unzip it and open in pxWorks.)
The first and simplest use case might be periodic retrieval (and processing) of some data using an R/Python/Julia/etc. or any mixture of these. We will use R.
To implement this design pattern we need a block that will initiate the control flow, let’s call it ‘init,’ and a heartbeat block, which is simply a script that generates an output file and passes the control flow back to its own input socket. There is no need to generate the file every time, but for simplicity, we will keep regenerating it every time the script is run.
The heartbeat output can be linked to any number of blocks that need to be run after the heartbeat block. Without complicating the program with actual data retrieval and processing, for demonstration purposes, we will simply generate random numbers and plot them. When you run the script, to see the plot, simply click on the “graph” icon in the main menu. pxWorks should open a new window which will display the latest generated plot.
So the heartbeat block will keep running perpetually and will trigger scripts in dependent blocks.
To stop the heartbeat block, the generated file must be deleted and the script must stop generating the file.
In further posts, we will demonstrate other design patterns we use in our data analysis workflow. This first example already shows how simple it is to introduce programming logic using just two types of connections to model the control flow rather than multiple types of blocks as done in some other platforms.
Things become so much simpler. Instead of thinking about programming architecture, one becomes free to think about the data as programming complexity vanishes.
###
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.