
Sentiment Analysis in Power BI with Microsoft Cognitive Services
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Today, we’re going to combine 2 powerful Microsoft tools into one analysis: Cognitive Services, and Power BI.
If you’re like me, you’re already doing your data analysis in Power BI. Similarly, you’re using Cognitive Services as your artificial intelligence multi-tool. But somehow, there isn’t a button in Power BI to “retrieve sentiment” for text, to “detect objects in image,” or to “extract key phrases” from a sentence. That’s alright. We’ll do the first one ourselves.
We’re going to kick this off assuming you already have Text Analytics endpoint and API Key. You’ll need the region from your endpoint, and the hexadecimal string that is the API key.
I’ve previously written and annotated code that allows any R programmer to use the Key Phrase and the Sentiment endpoint of the Text Analytics API. They full code is available in my GitHub repo, and will comprise most of the magic taking place.
You’ll need an interesting article to analyze. This works best for large text datasets from your customers, to help you build understanding of their underlying emotions without requiring you to read each one independently and understand the text. However, in this example, I’m parsing an opinion article from the Detroit Free Press about the Freedom of Information Act. It won’t make a difference; the steps are identical no matter your source.
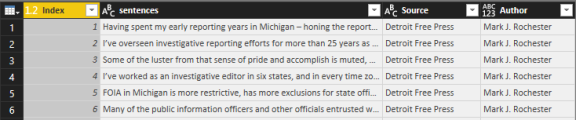
First, load your dataset in. It should have 1 sentence per line from the article. If managing multiple data source, you may want to add extra metadata to identify different customers, different articles or sources, and other key information relevant to understanding the text.
Once this is in, edit your query by choosing to add an R script
We’ll start by entering the full set of R scripts into the box. It loads our libraries (httr and rjson) and creates our functions.
# Extract key phrases uses Microsoft Cognitive Services API for Key Phrase
library(httr)
library(rjson)
cogAuth <- function(key) {
# Access key assignment for use in REST calls
assign("keyCogServices", key, envir = envCogServices)
}
# Create the empty environment to store the key
envCogServices <- new.env(parent = emptyenv())
# Function for using Cognitive Services API
# Note: Can ONLY be used with keyPhrases OR sentiment
fnCogServicesBatch <- function(text.inputs, phrase.language = "en", endpoint = "keyPhrases", region = "eastus") {
# Coerce to character
text.inputs <- as.character(text.inputs)
# The URL for Key Phrases cognitive service
url.cog.service <- paste("https://", region, ".api.cognitive.microsoft.com/text/analytics/v2.0/", endpoint, sep = "")
# Create empty list in proper structure for request
list.docs <- list(documents = list(list()))
num.max <- length(text.inputs)
# For loop (unfortunately);
for (i in 1:num.max) {
list.docs$documents[[i]] <- list(language = phrase.language, id = i, text = text.inputs[i])
}
# Convert the list to JSON for posting
json.body <- toJSON(list.docs)
# Post the call to the REST API
raw.response <- POST(url.cog.service, add_headers(.headers = c("Ocp-Apim-Subscription-Key" = envCogServices$keyCogServices, "Content-Type" = "application/json")), body = json.body)
# Read in the response as character
json.response <- readBin(raw.response$content, "character")
# Convert the character, now JSON, response back to a list
list.response <- fromJSON(json.response)
# Extract the first element of each of these
list.phrases <- lapply(list.response$documents, "[[", 1)
# Unlist to flatten all topics (does this break with score?)
vec.words <- unlist(list.phrases)
# Important!
tolower(vec.words)
}
For the calls to work, we have to do two things: Store our API key, and set the right configurations for region, language, and endpoint. My work is in the English language, the East US 2 region, and the Sentiment endpoint.
Set your API key by using the helper function cogAuth:
cogAuth("Your API key here!")
Then, after identifying which column has your records, coerce to a Character type. In my experience, this reduces the chances of odd behavior.
dataset$sentences <- as.character(dataset$sentences)
The nice part of my function is that it happily manages batch inputs. We’ll take advantage of that ability by throwing the entire column at the API, and assigning the return scores to a new column called ‘sentiment.’ This is also where we set the region, language, and endpoint!
dataset$sentiment <- fnCogServicesBatch(dataset$sentences, phrase.language = "en", endpoint = "sentiment", region = "eastus2")
As with any R scripts, we’ll change the dataset to ‘output’ so Power BI identifies the resulting data we want to keep.
output <- dataset
Warning! You may run into an error like the one below for privacy levels. If so, please reference the official Microsoft documentation.

The output may generate as a table, as well. This is okay! Expand the column and bring all values with it.

Finally, we see our sentiment in one place.
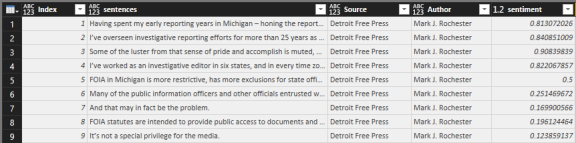
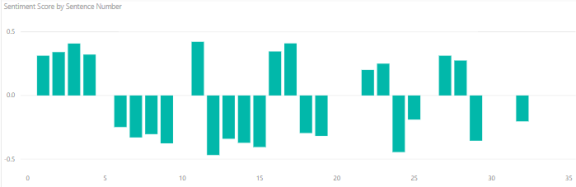
Remember that the way sentiment is delivered, a 0 is “Extremely negative,” while a 0.5 is “Neutral” and 1.0 is “Extremely positive.” You may want to create a calculated column that subtracts 0.5 from all scores to give yourself a positive/negative view.

Congratulations! You’ve put two of Microsoft’s most powerful tools together to further your analysis. From here, your real work begins.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.