
coauthorship and citation networks
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
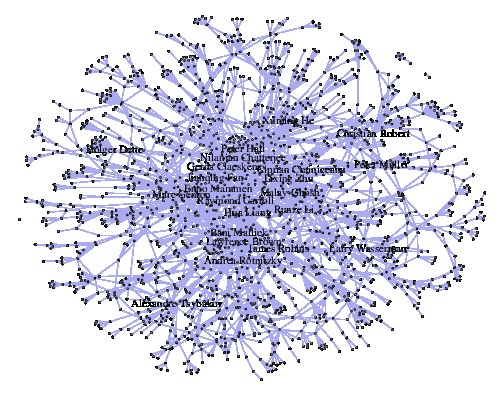 As I discovered (!) the Annals of Applied Statistics in my mailbox just prior to taking the local train to Dauphine for the first time in 2017 (!), I started reading it on the way, but did not get any further than the first discussion paper by Pengsheng Ji and Jiashun Jin on coauthorship and citation networks for statisticians. I found the whole exercise intriguing, I must confess, with little to support a whole discussion on the topic. I may have read the paper too superficially as a métro pastime, but to me it sounded more like a post-hoc analysis than a statistical exercise, something like looking at the network or rather at the output of a software representing networks and making sense of clumps and sub-networks a posteriori. (In a way this reminded of my first SAS project at school, on the patterns of vacations in France. It was in 1983 on pinched cards. And we spent a while cutting & pasting in a literal sense the 80 column graphs produced by SAS on endless listings.)
As I discovered (!) the Annals of Applied Statistics in my mailbox just prior to taking the local train to Dauphine for the first time in 2017 (!), I started reading it on the way, but did not get any further than the first discussion paper by Pengsheng Ji and Jiashun Jin on coauthorship and citation networks for statisticians. I found the whole exercise intriguing, I must confess, with little to support a whole discussion on the topic. I may have read the paper too superficially as a métro pastime, but to me it sounded more like a post-hoc analysis than a statistical exercise, something like looking at the network or rather at the output of a software representing networks and making sense of clumps and sub-networks a posteriori. (In a way this reminded of my first SAS project at school, on the patterns of vacations in France. It was in 1983 on pinched cards. And we spent a while cutting & pasting in a literal sense the 80 column graphs produced by SAS on endless listings.)
It may be that part of the interest in the paper is self-centred. I do not think analysing a similar dataset in another field like deconstructionist philosophy or Korean raku would have attracted the same attention. Looking at the clusters and the names on the pictures is obviously making sense, if more at a curiosity than a scientific level, as I do not think this brings much in terms of ranking and evaluating research (despite what Bernard Silverman suggests in his preface) or understanding collaborations (beyond the fact that people in the same subfield or same active place like Duke tend to collaborate). Speaking of curiosity, I was quite surprised to spot my name in one network and even more to see that I was part of the “High-Dimensional Data Analysis” cluster, rather than of the “Bayes” cluster. I cannot fathom how I ended up in that theme, as I cannot think of a single paper of mines pertaining to either high dimensions or data analysis [to force the trait just a wee bit!]. Maybe thanks to my joint paper with Peter Mueller. (I tried to check the data itself but cannot trace my own papers in the raw datafiles.)
I also wonder what is the point of looking at solely four major journals in the field, missing for instance most of computational statistics and biostatistics, not to mention machine learning or econometrics. This results in a somewhat narrow niche, if obviously recovering the main authors in the [corresponding] field. Some major players in computational stats still make it to the lists, like Gareth Roberts or Håvard Rue, but under the wrong categorisation of spatial statistics.
Filed under: Books, pictures, R, Statistics, University life Tagged: Annals of Applied Statistics, Annals of Statistics, Biometrika, citation map, coauthors, JASA, Journal of the Royal Statistical Society, JRSSB, network, Series B

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.