
Run SQL Straight On S3 via Athena in R
[This article was first published on Dynalytics, and kindly contributed to R-bloggers]. (You can report issue about the content on this page here)
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Run SQL on S3 Data via Athena in R

Santa comes early for us data scientist in the form of a brilliant new Amazon service called Athena. Athena now allows you to use standard SQL to query directly from data that lives in Amazon’s Simple Storage Service (S3). One of the benefits of Athena is that there are no upfront infrastructure cost or time to set up or manage. And this is a pay only what you use for the queries you execute. In this post I’ll walk through the simple set-up needed to query S3 via Athena in R!
Set Up in IAM
First: Set up Athena permissions via Amazon’s Identity and Access Management (IAM) console . You will need to Attach or enable the Amazon Athena policy. This may need to be handled by your DevOps person or Amazon account admin.
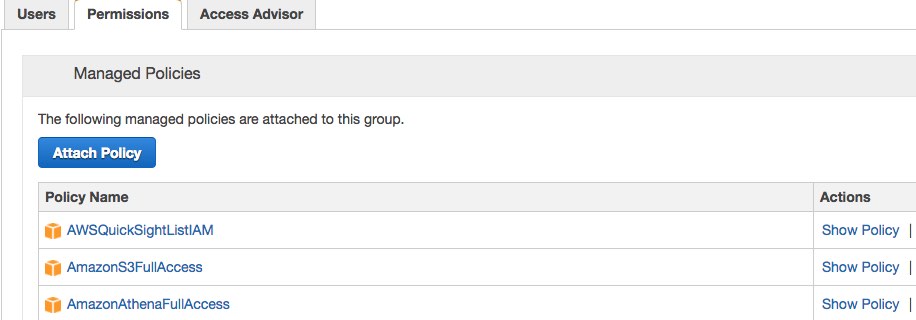
Once the Access is set up. You will get a designated area of where Athena will store its data within S3. This of this as our analytics data space that Athena will use to store and query our data. Once this is enabled you’ll see a new bucket in S3 labeled something like “aws-athena-query-results-“. Keep this information as this will be important to query against in R.
Obtaining Amazon Credentials
Credentials is what you need to get into that hot club on Friday night. In our case, instead of that club, its Amazon Services. You or your Amazon admin should have set you up with something called an AWS_ACCESS_KEY_ID and a AWS_SECRET_ACCESS_KEY. These are required to use Athena via R.
Explore Athena
Amazon has a lovely write up on getting started with Athena via their UI. I recommend browsing this just to get acclimated with the service and what you can and cannot do.
RJDBC for Great Justice
Amazon was fortunate enough to provide JDBC connectors for Athena. A thorough documentation of Athena’s JDBC driver can be found there. To keep it simple, we’ll apply the R package RJDBC
First thing is to load the RJDBC and download the Athena JDBC driver:
Then we should store our Amazon credentials in our system environment for ease of retrieval (optional) . You can put this in the JDBC request:
Lastly call the dbConnect function from the RJDBC package and pass in both the JDBC driver for Athena, the URL and your AWS credentials :
Lastly call the dbConnect function from the RJDBC package and pass in both the JDBC driver for Athena, the URL and your AWS credentials :
Now if we don’t have any data loaded in Athena, we can do some with the sample data set that Amazon provides. The below code will create the table in the sampledb database. Do note that to create tables from S3 we need to use the dbSendQuery function.
Once that completed, we can simply query the data using the dbGetQuery function:
Once that completed, we can simply query the data using the dbGetQuery function:
Conclusion
These R code snippets will now allow you to create and query tables for S3 data via Athena. Quite a holiday present from Amazon if I do say so myself. This begins to make ‘big data’ a little more accessible.via GIPHY
To leave a comment for the author, please follow the link and comment on their blog: Dynalytics.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.