

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
by Joseph Rickert
I found my way into data science and machine learning relatively late in my career. When I began reading papers on supervised learning I was delighted to find that good old logistic regression was considered a “go to” classifier. This was like learning that an old friend was admired for an achievement I didn’t know anything about. After a couple of comfortable experiences like this, I thought I would fit in quite nicely with this new (to me) tribe of data analysts studying pattern recognition and natural language processing. It took some time however, before I realized that they were working with a conceptual framework that was a little different from my statistics worldview. You might say it’s all probabilistic and statistical reasoning, but different problems and different tools lead to mindsets that shape and bias a person’s thinking.
For example, consider the following list of classifiers: Decision Trees, Generalized Boosted Models, Logistic Regression, Naive Bayes, Neural Networks, Random Forests and Support Vector Machine.
Some of these are base classifiers, and others are ensemble models, but one of them is conceptually different from the others. The odd duck here Naive Bayes. It’s the only generative model in the list. The others are examples of discriminative models. This is not a distinction that is easy to stumble across in the statistics literature, but it is fundamental to the machine-learning mindset, and a helpful modeling idea.
The basic conceptual difference between generative and discriminative models hinges on the underlying probability inference structure. Discriminative models learn P(Y | X), the conditional relationship between the target variable, Y, and the features, X, directly from the data. This is exactly the way ordinary least squares regression works, and it is the kind of inference pattern that gets fixed in the mind of statistics students very early on in their training. It is a direct approach to sorting out the relationship among variables. Some (usually one) variables are the dependent variables, or target variables, and other variables are the independent variables, or features. These latter variables are given or fixed, at least for the purposes of the analysis.
Generative models, on the other hand, aim for a complete probabilistic description of the data. With these models, the goal is to construct the joint probability distribution P(X, Y) – either directly or by first computing P(X | Y) and P(Y) – and then inferring the conditional probabilities required to classify new data. This approach generally requires more sophisticated probabilistic thinking than a regression mentality demands, but it provides a complete model of the probabilistic structure of the data. Knowing the joint distribution enables you to generate the data; hence, Naive Bayes is a generative model.
Once you know what you are looking for, it is not difficult to find excellent online tutorials demonstrating the differences between generative and discriminative models. For example, Stanford professors Christopher Manning and Andrew Ng have both produced short videos that nicely characterize these models. And for a simple explanation of the Naive Bayes algorithm and how it unfolds as a generative model, I very much enjoyed mathematicalmonk’s colored marker video.
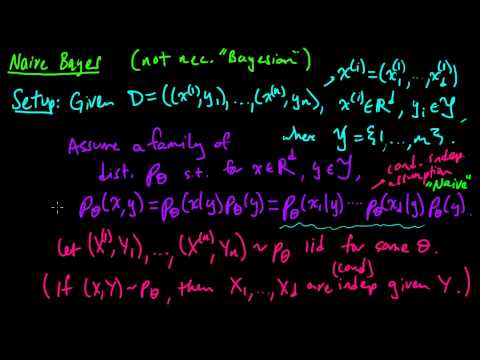
In his Eight to Late blog, Kalish Awati thoroughly develops a classification example using Naive Bayes that is worth a look not only because of the details on data preparation and model building he provides, but also because of the care he takes to explain the underlying theory. Kalish uses the Naive Bayes classifier in the mysteriously named e1071 package and the HouseVotes data set from the mlbench package. (The klar package from the University of Dortmund also provides a Naive Bayes classifier.) I won’t reproduce Kalish’s example here, but I will use his imputation function later in this post.
First however, let’s follow up on the idea of using a Naive Bayes model to produce synthetic data.
library(mlbench)
library(e1071)
data("HouseVotes84")
model <- naiveBayes(Class ~ ., data = HouseVotes84)
print(model)
The model object produced by the naiveBayes() function includes a contingency table for each vote, which is displayed by the print statement above. Here is an example of just one of the tables displayed by the print statement:
model$tables$V2 # V2 # Y n y # democrat 0.4979079 0.5020921 # republican 0.4932432 0.5067568
Creating new, synthetic data is just a matter of using this table to drive a simulation. Suppose that we wanted to simulate data for 25 new Democratic members of the House of Representatives. This is particularly easy for our example, because we are dealing with categorical data.
# Use the model object to create a vector of probabilities for
# a No vote for each of the 16 variables
pn <- vector(mode="numeric",length=16)
for (i in 1:16) {
pn[i] <- model$tables[[i]][1,1]
}
# Create new democratic voting data
dem_data <- matrix(data = NA, nrow = 25, ncol = 17)
for( i in 1:25){
dem_data[i,] <- c("democrat",rbinom(16,1,pn))
}
# Coerce the data into a data frame
dem_data <- data.frame(dem_data)
# Set the levels to match the original data
levels(dem_data[,1]) <- c("democrat","republican")
dem_data[,1] <- factor(dem_data[,1],levels=c("democrat","republican"))
for(i in 2:17){
levels(dem_data[,i]) <- c("y","n")
}
# Set the column names to match the real data
names(dem_data) <- c("Class","V1","V2","V3","V4","V5","V6","V7","V8",
"V9","V10","V11","V12","V13","V14","V15","V16")
head(dem_data,2)
dim(dem_data)
A very nice, maybe even ironic feature of the the Naive Bayes algorithm, is that while it is extremely useful in generating synthetic data when there is not enough real data at hand, it is also of considerable importance in the world of big data and machine learning. Almost every industrial-strength big data platform, including Apache Mahout, Spark’s MLlib, SparkR package, Microsoft R Server, and H2O, has an implementation of Naive Bayes. The are several reasons for this including: (1) the empirical observation that Naive Bayes performs remarkably well, in spite of the unrealistic assumption of independent conditional probabilities (For example see Rist et al.); (2) the fact that the number of parameters required to fit a Naive Bayes model scales linearly with the number of variables, and (3) maximum likelihood training can be done via closed form expressions. So it is not necessary to grind through several iterations of a calculation waiting for the convergence.
An easy way for an R user to run a Naive Bayes model on very large data set is via the sparklyr package that connects R to Spark. The following code, which makes use of the HouseVotes84 dataframe and Kalish’s imputation function, shows how to fit a Naive Bayes model on Spark data.
The first bit of code loads the data into my local R session and imputes the missing values.
library(mlbench)
library(e1071)
#load HouseVotes84 dataset
data("HouseVotes84")
head(HouseVotes84,2)
#---------------------------------------
# This function is taken from Kalish Awati's
# post on Naive Bayes
# It imputes missing values for the
# HouseVotes84 data set
# function to return number of NAs by vote and class
# (democrat or republican)
na_by_col_class <-
function (col,cls){return(sum(is.na(HouseVotes84[,col] &
HouseVotes84$Class==cls))}
# function to compute the conditional probability
# that a member of a party will cast
# a 'yes' vote for a particular issue.
# The probability is based on all members of the
# party who actually cast a vote on the issue (ignores NAs).
p_y_col_class <- function(col,cls){
sum_y<-sum(HouseVotes84[,col]=='y' &
HouseVotes84$Class==cls,na.rm = TRUE)
sum_n<-sum(HouseVotes84[,col]=='n' &
HouseVotes84$Class==cls,na.rm = TRUE)
return(sum_y/(sum_y+sum_n))}
#impute missing values.
for (i in 2:ncol(HouseVotes84)) {
if(sum(is.na(HouseVotes84[,i])>0)) {
c1 <- which(is.na(HouseVotes84[,i])& HouseVotes84$Class=='democrat',arr.ind = TRUE)
c2 <- which(is.na(HouseVotes84[,i])& HouseVotes84$Class=='republican',arr.ind = TRUE)
HouseVotes84[c1,i] <-
ifelse(runif(na_by_col_class(i,'democrat'))<
p_y_col_class(i,'democrat'),'y','n')
HouseVotes84[c2,i] <-
ifelse(runif(na_by_col_class(i,'republican'))<
p_y_col_class(i,'republican'),'y','n')}
}
Next, since Spark and the MLlib functions do not have any notion of R’s factor type, I replace the factor variables with 0 /1 indicators.
# Get rid of factors
votes <- HouseVotes84
votes$Class <- ifelse(votes$Class == "democrat", 0, 1)
votes[,2:17] <- sapply(votes[,2:17],
function(x){ifelse(x == "n", 1, 0)})
The sparlyr and dplyr packages are loaded and Spark is installed on the local computer. Next, the spark_connect() function establishes the Spark compute context. (Connecting to a remote cluster is a bit more involved, but the connection is established through the same mechanism.)
library(sparklyr) library(dplyr) spark_install() sc <- spark_connect(master = "local") votes_tbl <- copy_to(sc, votes,overwrite=TRUE) head(votes_tbl)
Finally, we partition the data into training and test data sets and use the MLlib implementation of Naive Bayes to fit the model in Spark.
#Partition into 'training', 'test'
partitions < - votes_tbl %>%
sdf_partition(training = 0.5,
test = 0.5, seed = 1099)
head(partitions$training)
# pick out the feature variables.
X_names <- names(votes[,2:17])
# Fit model
nb_spark_model <- ml_naive_bayes(partitions$training,
response= "Class",
features = X_names)
nb_spark_model
From here, it would not take much more work to complete the rest of Kalish’s example in Spark.
In the machine learning world, Naive Bayes may be an even more popular “go to” classifier than logistic regression. It often provides predictive results that are good enough to set the bar as a baseline model. it is interesting as a simple example of a generative model, and with the help of the sparklyr package, it is easy for R users to deploy in Spark’s big data environment.
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.