
Deck on an Authorial Analysis of the Prime Minister’s Speeches
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I recently attempted a Stylistic Analysis of the Pakistani Prime Minister’s speeches, in order to identify if his speeches exhibit different Stylistic patterns. Large differences would indicate possibilities of different writers.
Background to this task: Some significant events in Pakistan had prompted the Prime Minister to address the nation. The speech was later leaked on Social Media, and supposedly presented the Prime Minister as discussing diction for his speech with his special aides.
This was met with criticism by some Paksitani News Channels, which felt that at a time when the government is embroiled in corruption and mismanagement, the attitude depicted in the leaked clip is irresponsible.
The deck linked to, summarises this task I took upon myself.
The original post can be accessed from here.
The code that goes into this deck is presented below.
---
---
title : How Many Writers does the Prime Minister have for his Speeches?
subtitle : An Authorial Analysis
author : Ali Arsalan Kazmi
job :
framework : io2012 # {io2012, html5slides, shower, dzslides, ...}
highlighter : highlight.js # {highlight.js, prettify, highlight}
hitheme : tomorrow #
widgets : [] # {mathjax, quiz, bootstrap}
mode : selfcontained # {standalone, draft}
knit : slidify::knit2slides
--- .break
## Background
--- &vcenter
A series of events in Pakistan prompted the Prime Minister to address the nation...
--- bg:url(http://blogs.reuters.com/great-debate/files/2013/10/pm-sharif.jpg);background-size:cover
After the speech, however, an Audio clip was leaked, allegedly of the PM taking advice on diction from his aides
---
## Surprise & Criticism

--- &vcenter
This was followed by another major event...
--- bg:url(https://cdn1.tnwcdn.com/wp-content/blogs.dir/1/files/2016/04/mossackfonseca-1100x735.jpg);background-size:cover
--- &vcenter
Another speech was delivered...
--- &vcenter
And an Audio clip supposedly for this speech was also leaked...
---
## Questions asked in News Channels & Social Media
>- Does the Prime Minister consult his advisors on diction for every speech or for ones delivered during extraordinary circumstances only?
>- From his advisors, does the PM rely more on his family members?
>- Has the PM's reliance on certain family members and aides increased only recently, as his government has come under increasing fire for involvement in large scale corruption?
>- Is it possible to obtain information of such collaborations for other speeches of the PM?
--- .break
## Motivation
--- bg:url(https://thedailychapter.files.wordpress.com/2012/01/hand-writing-quill-pen.jpg);background-size:cover
---
Using Traditional Journalism to identify if different authors are involved in the PM's speeches is likely to be:
>- perilous
>- time-consuming
Data Journalism, on the other hand, can attempt to answer this question relatively comfortably with:
>- Stylistic Analysis/Stylometry
--- .break
## Procedure
---
>- Scrap Speech Data from the PM Office's website
- English Speeches
- Around 60 in total
>- Clean Data
- Semi-automatic
>- Apply Stylometric Techniques
- Various
- Boostrap Consensus Network (due to Professor Eder)
- Visualise
>- Details included here
--- .break
## Datasets
---
## Datasets
Different datasets genereted using:
>- Parts of Speech (POS) Tagging
>- Word Bigrams
>- Character 4-grams
--- .break
### Bootstrap Consensus Network using POS Bigrams
---

--- .break
### Heatmap using Most Frequent Word Bigrams
---
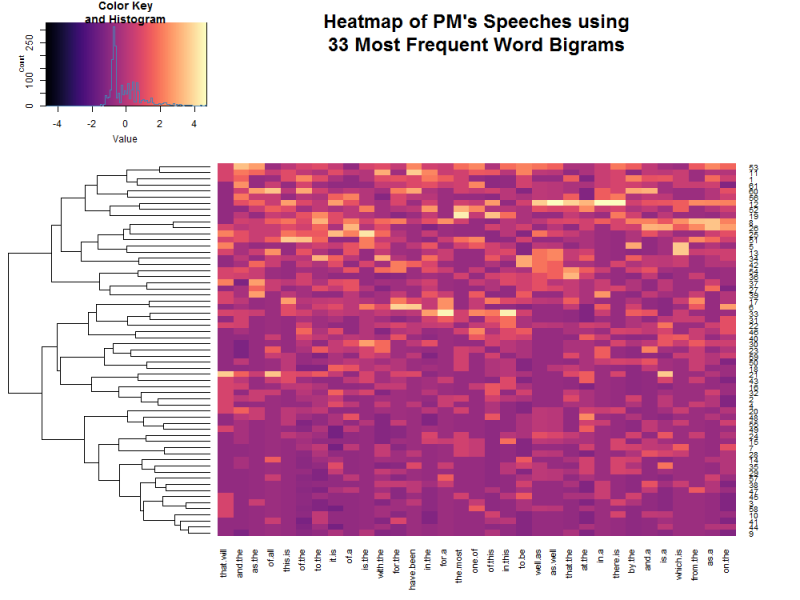
--- .break
### Bootstrap Consensus Network using Most Frequent Character 4-grams
---

---
## Two Authors?
>- Almost all analyses point to two separated clusters of speeches
>- Does depend significantly on amount of data
>- Indicates there may be two (or more) authors
>- Blog post can be accessed here
---
R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.