

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
Naturally, both Hillary Clinton and Donald Trump have been accused of lying; if I had told you in 2012 that both candidates from both political parties were being accused of lies, you would likely have given me a blank, disinterested stare; this alone is not shocking. What is shocking, though, is the level of deceit and how central a theme it was to this campaign season.
Some accuse the other side of being the liars, the other side counters with a similar accusation, and those not committed to a side like to lazily declare both sides to be equally guilty of lying. It does not take much thought, though, to realize there is no reason why both sides should be equally guilty of lying, and that is especially true for this election.
Donald Trump takes lying to a new level, living in his own invented reality and inviting the rest of America to participate in his nightmarish hallucination that only he can save us from. The media has struggled to handle this. They worry about appearing unfairly biased, and in the past, perhaps behaving as if both sides were equally guilty of lying seemed a good enough proxy to reality to avoid coming across as biased. But Donald Trump lies so much it’s thrown them off their toes (if you don’t believe me, read on; I have evidence later), and his candidacy has sparked a conversation in the media world about how to handle a candidate so casually dishonest he himself may not know what is true and what is not.
Here, I’m going to use R to dig deeper into the question about how honest are our politicians, and whether one party lies more than another. All of my data was scraped from PolitiFact’s website, a popular and well-known fact checker with an excellent categorization system that makes analyzing their data easier. I present various graphics and tables showing who lies more, and what they lie about.
Data Extraction and Analysis
Before scraping, I use MySQL to create a database that will hold the data I scrape from PolitiFact. The SQL statements that define the tables in the database politifactscraper are shown below.
/* PolitiFactScraper_define.sql
*
* Defines tables used to hold information for my PolitiFact web scraper.
*/
/* Rating: contains rating schema
aid: The rating id
label: The name of the rating
*/
create table Rating (
aid int auto_increment primary key,
label char(15)
) auto_increment = 0;
/* Party: contains (political) party schema
rid: The id of the party
name: Contains the name of the party
*/
create table Party (
rid int auto_increment primary key,
name char(50)
) auto_increment = 0;
/* Speaker: Contains details about speakers for which statements exist
pid: The id of the speaker
name: The name of the speaker
rid: The id of the party with whom the speaker is affiliated
*/
create table Speaker (
pid int auto_increment primary key,
name varchar(140) not null,
rid int,
foreign key (rid) references Party (rid) on update cascade on delete set null
) auto_increment = 1;
/* Stmnt: Contains statements made
sid: The id of the statement
aid: The id of the rating given to the statement
text: The statement's text
s_date: The date on which the statement was made
*/
create table Stmnt (
sid int auto_increment primary key,
aid int,
text varchar(2000) not null,
s_date date,
pid int not null,
foreign key (pid) references Speaker (pid) on update cascade on delete cascade,
foreign key (aid) references Rating (aid) on update cascade on delete set null
) auto_increment = 1;
/* About: Contains relations identifying an individual about whom the statement was made
sid: The id of the statement
pid: The id of the person about whom the statement was made
NOTE: This table is not used currently
*/
create table About (
sid int not null,
pid int not null,
primary key (sid, pid),
foreign key (sid) references Stmnt (sid) on update cascade on delete cascade,
foreign key (pid) references Speaker (pid) on update cascade on delete cascade
);
I wrote a Python program to scrape the data from PolitiFact and save the data in the database politifactscraper. The code for the program is listed below:
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.error import *
from datetime import datetime
import time
import html
import dateparser
import requests
import string
import pymysql as sql
def get_statements(people_dict):
"""
:param people_dict: dict; A dictionary object with names for indices and a string of the form "/personalities/im-a-person/" that will be appended to the end of a PolitiFact URL
:return: dict; A dict containing two entries: "Statements", with a list containing tuples of the form (name, url, page number, rating, date, text); and "Errors", a list of URLs that failed to be scraped
This function scrapes PolitiFact's website, extracting information for all persons in people_dict and returning a list with tuples with the scraped information.
"""
# Prepare session
session = requests.Session()
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36",
"Accept-Language":"en-US,en;q=0.8",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"}
waittime = 10 # Don't want to go too fast (preferred time according to site's robost.txt)
politifact_base = "http://www.politifact.com"
statements = set()
error_pages = list()
for name, link in people_dict.items():
page = 0
time.sleep(waittime + 1) # Don't go too fast
try:
# Get page and process via BeautifulSoup
src = session.get(politifact_base + link + "statements/?page=1", headers = headers)
statement_pg = BeautifulSoup(src.text, "lxml")
# Below's latter condition checks to see if there are more pages to "click"
while page == 0 or statement_pg.find("", {"title": "Next"}) != None:
page += 1 # Update page number
try:
if page > 1:
# If we're on a new page, read it
time.sleep(waittime + 1)
src = session.get(politifact_base + link + "statements/?page=" + str(page), headers = headers)
statement_pg = BeautifulSoup(src.text, "lxml")
# Begin processing statements
for s in statement_pg.findAll("", {"class": "statement"}):
if s.find("div", {"class":"statement__source"}).a.get("href") == link:
# This statement was made by the individual who's page we are on
try:
statements.add((name.replace(' ', ' '),
politifact_base + link,
page,
s.find("div", {"class":"meter"}).img.get("alt"),
dateparser.parse(s.find("span", {"class":"article__meta"}).get_text()[3:]),
s.find("p", {"class":"statement__text"}).a.get_text().strip().replace('\xa0', ' ')))
except:
# If something bad happens, add a blank entry
statements.add((name.replace(' ', ' '),
politifact_base + link,
page,
None,
None,
None))
except URLError as e:
# Print errors and add to list of error pages
print(e)
error_pages.append((name, politifact_base + link + "statements/?page=" + str(page)))
except URLError as e:
print(e)
error_pages.append((name, politifact_base + link + "statements/?page=1"))
return {"Statements": list(statements), "Errors": error_pages}
def speakers_to_db(people_dict, party, cur):
"""
:param people_dict: dict; A dictionary object with names for indices and a string of the form "/personalities/im-a-person/" that will be appended to the end of a PolitiFact URL
:param party: string; An identifier for the political party associated with the individuals in people_dict
:param cur: cursor; A pymysql cursor object
This function enters the people in people_dict into the speaker table in the MySQL data base connected to by cur. Note that party must be an existing entry in the party table in the data base.
"""
# Get party rid identifier
res = cur.execute("select rid from party where name=\"" + party + "\";")
if res == 1:
rid = cur.fetchone()[0]
else:
raise RuntimeError("When I looked up party " + party + " in database I did not get exactly one result!")
# Populate database
for name in people_dict.keys():
res = cur.execute("select name, rid from speaker where name='" + name.replace("'", "''") + "' and rid=" + str(rid) + ";")
if res == 0:
cur.execute("insert into speaker (name, rid) values ('" + name.replace("'", "''") +"'," + str(rid) + ");")
cur.connection.commit()
def statements_to_db(stmnt_list, party, cur):
"""
:param stmnt_list: list; A list containing statements to be entered into the data base connected to by cur
:param party: string; A string identifying the party associated with the statements
:param cur: cursor; A pymysql cursor object
This function enters the statements in stmnt_list into the smnt table in the data base connected to by cur. Be sure that all speakers in the list are already included in the speaker table in the data base.
"""
# Create table of statement rating aid values
res = cur.execute("select * from rating;")
# There should be nine rating values
if res == 9:
# Table is a reverse crosswalk; given name of rating, it gives the aid value
aid_table = dict()
for _ in range(res):
row = cur.fetchone()
aid_table[row[1]] = row[0]
else:
raise RuntimeError("Something is wrong with the rating table in database; does not have appropriate number of entries!")
# Create table for speakers, giving their pid numbers, all from selected party
res = cur.execute("select pid, name from speaker where rid = (select rid from party where name = \"" + party + "\");")
# The table should have at least one person in it
if res > 0:
# Table is a reverse crosswalk; given name of speaker, it gives the pid value
pid_table = dict()
for _ in range(res):
row = cur.fetchone()
pid_table[row[1].replace(" ", " ")] = row[0]
else:
raise RuntimeError("You should populate the table of speakers before trying to add statements to database!")
# We can now finally start adding statements to the table
for name, _, __, rating, date, text in stmnt_list["Statements"]:
cur.execute("insert into stmnt (pid, aid, s_date, text) values (" + str(pid_table[name.replace(" ", " ")]) + ", " + str(aid_table[rating]) + ", \'" + date.strftime('%Y%m%d') + "\', \'" + text.replace("'", "''") + "\');")
cur.connection.commit()
def main():
conn = sql.connect(host='localhost', user = "root", passwd=my_pass, db="mysql", charset = "utf8")
cur = conn.cursor()
cur.execute("use politifactscraper;")
politifact_base = "http://www.politifact.com"
html = urlopen(politifact_base + "/personalities/")
bsObj = BeautifulSoup(html.read(), "lxml")
people = bsObj.findAll("li", {"class": "az-list__item"})
people_affil = [p for p in people if (p.find("span", {"class":"people-party"}) != None)]
republicans = [p for p in people_affil if (p.find("span", {"class":"people-party"}).get_text() == "Republican")]
democrats = [p for p in people_affil if (p.find("span", {"class":"people-party"}).get_text() == "Democrat")]
independents = [p for p in people_affil if (p.find("span", {"class":"people-party"}).get_text() == "Independent")]
libertarians = [p for p in people_affil if (p.find("span", {"class":"people-party"}).get_text() == "Libertarian")]
r_links = dict([(p.a.get_text(), p.a.get("href")) for p in republicans])
d_links = dict([(p.a.get_text(), p.a.get("href")) for p in democrats])
i_links = dict([(p.a.get_text(), p.a.get("href")) for p in independents])
l_links = dict([(p.a.get_text(), p.a.get("href")) for p in libertarians])
# Manually add notorious individuals
r_links.update({
"Mitch McConnel": "/personalities/mitch-mcconnell/",
"Paul Ryan": "/personalities/paul-ryan/"
})
d_links.update({
"Barack Obama": "/personalities/barack-obama/",
"Joe Biden": "/personalities/joe-biden/",
"Nancy Pelosi": "/personalities/nancy-pelosi/",
"Harry Reid": "/personalities/harry-reid/"
})
# Links for select individuals
u_links = {
"Bloggers": "/personalities/blog-posting/",
"Facebook posts": "/personalities/facebook-posts/",
"Chain email": "/personalities/chain-email/"
}
speakers_to_db(l_links,"Libertarian",cur)
speakers_to_db(r_links,"Republican",cur)
speakers_to_db(d_links,"Democrat",cur)
speakers_to_db(i_links,"Independent",cur)
speakers_to_db(u_links,"Unaffiliated",cur)
l_statements = get_statements(l_links)
d_statements = get_statements(d_links)
r_statements = get_statements(r_links)
i_statements = get_statements(i_links)
u_statements = get_statements(u_links)
statements_to_db(l_statements, "Libertarian", cur)
statements_to_db(d_statements, "Democrat", cur)
statements_to_db(r_statements, "Republican", cur)
statements_to_db(i_statements, "Independent", cur)
statements_to_db(u_statements, "Unaffiliated", cur)
cur.close()
conn.close()
if __name__ == '__main__':
main()
Now that the data is in a database, it’s easy to access and process it using either R or Python. I will be using both languages for analyzing this data.
In R, I first assess how honest individuals who associate with a party are (I also include the “Unaffiliated” group, which does not include politicians but the unending stream of bloggers and Facebook/e-mail spam that we see on a daily basis). PolitiFact ratings can be seen as ordinal data, which means that metrics based on order, such as the median are well-defined. I base judgement of honesty on the median first, then break ties using the mean (which is not well-defined for this data). In the data base, I conveniently assigned the values in the aid column of the rating table so that it reflects the order of “honesty” for each possible rating, with 0 for “Pants on Fire!” and 5 for “True” (the flip-flopping scores have values 6 for “Full Flop” to 8 for “No Flip”, but are excluded in further analysis). The result is shown below:
library(dplyr)
library(magrittr)
library(htmlTable)
library(reshape2)
library(vcd)
# Get access to data base
db <- src_mysql("politifactscraper", password = my_pswd)
# Begin working with data base with dplyr
db %>%
# Get stmnt table
tbl("stmnt") %>%
# Need to join with speaker table to get party id
left_join(tbl(db, "speaker"), by = "pid") %>%
as.data.frame %>%
# Exclude flops
filter(aid <= 5) %>%
group_by(rid) %>%
# Compute desired metrics per party
summarize(med = median(aid), avg = mean(aid), num = length(aid)) %>%
# Get party names
left_join(tbl(db, "party") %>% as.data.frame, by = "rid") %>%
arrange(desc(med), desc(avg)) %>%
select(name, med, avg, num) %>%
# Get rating names
left_join(tbl(db, "rating") %>% as.data.frame, by = c("med" = "aid")) %>%
mutate(avg = round(avg, digits = 2)) %$%
# Finally put in a pretty HTML table for display in markdown
htmlTable(select(., "Median Honesty" = label, "Average Honesty Score" = avg, "Rated Statements" = num), rnames = name, caption = "Party Honesty", tfoot = "Data source: PolitiFact")
| Party Honesty | |||
| Median Honesty | Average Honesty Score | Rated Statements | |
|---|---|---|---|
| Independent | Mostly True | 3.25 | 181 |
| Democrat | Half-True | 3.07 | 4026 |
| Libertarian | Half-True | 2.92 | 147 |
| Republican | Half-True | 2.57 | 5480 |
| Unaffiliated | Pants on Fire! | 1.06 | 350 |
| Data source: PolitiFact |
It seems that Independents, in the aggregate, tell the truth the most, and Republicans the least. While Democrats, Libertarians, and Republicans all have median honesty scores of “Half-True”, the tie-breaker suggests Democrats are the most honest, Republicans the least. Interestingly, PolitiFact rates Republicans more often than Democrats.
As for the Unaffiliated group, take anything you see on Facebook, on some random dude’s blog, or in a chain e-mail with a grain of salt; their median honesty is “Pants on Fire!”
Okay, so that’s the parties. What about individuals? I repeat the above pipeline to see the the top 20 most honest individuals on PolitiFact. Because some people have only a couple ratings in file, I require that PolitiFact have rated at least 15 statements made by the individual to be included in the following lists.
db %>%
# Get stmnt table
tbl("stmnt") %>%
as.data.frame %>%
# Exclude flops
filter(aid <= 5) %>%
group_by(pid) %>%
# Compute desired metrics per person (round ratings up, if needed)
summarize(med = ceiling(median(aid)), avg = mean(aid), num = length(aid)) %>%
filter(num > 15) %>%
arrange(desc(med), desc(avg)) %>%
slice(1:20) %>%
# Need to join with speaker table to get speaker information
left_join(tbl(db, "speaker") %>% as.data.frame, by = "pid") %>%
# Get party names
left_join(tbl(db, "party") %>% rename("p_name" = name) %>% as.data.frame, by = "rid") %>%
select(name, p_name, med, avg, num) %>%
# # Get rating names
left_join(tbl(db, "rating") %>% as.data.frame, by = c("med" = "aid")) %>%
mutate(avg = round(avg, digits = 2)) %$%
# # Finally put in a pretty HTML table for display in markdown
htmlTable(select(., "Party" = p_name, "Median Honesty" = label, "Average Honesty Score" = avg, "Rated Statements" = num), rnames = name, caption = "Tope 20 Honest Entites", tfoot = "Data source: PolitiFact")
| Tope 20 Honest Entites | ||||
| Party | Median Honesty | Average Honesty Score | Rated Statements | |
|---|---|---|---|---|
| Alex Sink | Democrat | True | 4 | 19 |
| Dennis Kucinich | Democrat | Mostly True | 3.84 | 25 |
| Sheldon Whitehouse | Democrat | Mostly True | 3.79 | 24 |
| Cory Booker | Democrat | Mostly True | 3.6 | 20 |
| Mark Warner | Democrat | Mostly True | 3.6 | 20 |
| Gina Raimondo | Democrat | Mostly True | 3.59 | 17 |
| Sherrod Brown | Democrat | Mostly True | 3.59 | 34 |
| Rob Portman | Republican | Mostly True | 3.57 | 47 |
| Bill Nelson | Democrat | Mostly True | 3.48 | 25 |
| David Axelrod | Democrat | Mostly True | 3.39 | 18 |
| Hillary Clinton | Democrat | Mostly True | 3.34 | 292 |
| Bernie Sanders | Independent | Mostly True | 3.25 | 107 |
| John Kasich | Republican | Mostly True | 3.25 | 64 |
| Fred Thompson | Republican | Mostly True | 3.25 | 16 |
| Bill Richardson | Democrat | Mostly True | 3.24 | 17 |
| Alan Grayson | Democrat | Mostly True | 3.18 | 34 |
| Bill White | Democrat | Mostly True | 3.08 | 26 |
| Tim Kaine | Democrat | Half-True | 3.38 | 50 |
| Nathan Deal | Republican | Half-True | 3.37 | 49 |
| Bill Clinton | Democrat | Half-True | 3.29 | 41 |
| Data source: PolitiFact |
Alex Sink, a Florida Democrat who ran for governor and the House of Representatives (and lost both races) has the highest rating. Rob Portman, the junior Senator from Ohio, is the most honest Republican, and Bernie Sanders the most honest Independent. Of those who ran for President in the 2016 election, Hillary Clinton, according to PolitiFact’s ratings, was the most honest candidate (Bernie Sanders was a close second), and John Kasich was the most honest Republican (in fact, tied with Bernie Sanders). Barack Obama, interestingly, does not appear on this list.
And now the list of shame: The most dishonest individuals.
db %>%
# Get stmnt table
tbl("stmnt") %>%
as.data.frame %>%
# Exclude flops
filter(aid <= 5) %>%
group_by(pid) %>%
# Compute desired metrics per person (round ratings up, if needed)
summarize(med = ceiling(median(aid)), avg = mean(aid), num = length(aid)) %>%
filter(num > 15) %>%
arrange(med, avg) %>%
slice(1:20) %>%
# Need to join with speaker table to get speaker information
left_join(tbl(db, "speaker") %>% as.data.frame, by = "pid") %>%
# Get party names
left_join(tbl(db, "party") %>% rename("p_name" = name) %>% as.data.frame, by = "rid") %>%
select(name, p_name, med, avg, num) %>%
# # Get rating names
left_join(tbl(db, "rating") %>% as.data.frame, by = c("med" = "aid")) %>%
mutate(avg = round(avg, digits = 2)) %$%
# # Finally put in a pretty HTML table for display in markdown
htmlTable(select(., "Party" = p_name, "Median Honesty" = label, "Average Honesty Score" = avg, "Rated Statements" = num), rnames = name, caption = "Tope 20 Dishonest Entities", tfoot = "Data source: PolitiFact")
| Tope 20 Dishonest Entities | ||||
| Party | Median Honesty | Average Honesty Score | Rated Statements | |
|---|---|---|---|---|
| Chain email | Unaffiliated | Pants on Fire! | 0.78 | 178 |
| Bloggers | Unaffiliated | Pants on Fire! | 0.92 | 72 |
| Democratic Party of Wisconsin | Democrat | False | 1.5 | 24 |
| Ben Carson | Republican | False | 1.54 | 28 |
| Michele Bachmann | Republican | False | 1.59 | 61 |
| Facebook posts | Unaffiliated | False | 1.65 | 100 |
| Herman Cain | Republican | False | 1.77 | 26 |
| Donald Trump | Republican | False | 1.82 | 327 |
| Ken Cuccinelli | Republican | False | 2.2 | 20 |
| Democratic Congressional Campaign Committee | Democrat | Mostly False | 1.44 | 34 |
| National Republican Senatorial Committee | Republican | Mostly False | 1.87 | 30 |
| Allen West | Republican | Mostly False | 1.88 | 26 |
| Paul Broun | Republican | Mostly False | 2 | 19 |
| National Republican Congressional Committee | Republican | Mostly False | 2.08 | 53 |
| Reince Priebus | Republican | Mostly False | 2.12 | 24 |
| Ted Cruz | Republican | Mostly False | 2.2 | 116 |
| Tommy Thompson | Republican | Mostly False | 2.26 | 27 |
| Newt Gingrich | Republican | Mostly False | 2.27 | 77 |
| Republican Party of Florida | Republican | Mostly False | 2.29 | 34 |
| Rick Santorum | Republican | Mostly False | 2.32 | 59 |
| Data source: PolitiFact |
I allowed chain e-mails, bloggers, and Facebook posts to appear in this list just to make the following point: they’re full of shit. Go to legitimate news sources to get your information. (In my defense as a blogger, I try to be pretty transparent; judge my honesty as you will.) The two “Democrats” that appear on this list are organizations, the Democratic Party of Wisconsin (is this why Scott Walker is a thing?) and the DCCC. Ben Carson is the most dishonest individual on this list and thus the most dishonest person who ran for President in the 2016 election season, according to PolitiFact. (In Dr. Carson’s defense, though, I don’t know if it’s “dishonesty” per se or just ignorance/stupidity.) Donald Trump, according to PolitiFact, is extremely dishonest, yet somehow Hillary is the corrupt liar.
98 people in PolitiFact’s data had at least 15 ratings, so here is the full list, with rankings provided:
db %>%
# Get stmnt table
tbl("stmnt") %>%
as.data.frame %>%
# Exclude flops
filter(aid <= 5) %>%
group_by(pid) %>%
# Compute desired metrics per person (round ratings up, if needed)
summarize(med = ceiling(median(aid)), avg = mean(aid), num = length(aid)) %>%
filter(num > 15) %>%
arrange(desc(med), desc(avg)) %>%
# Need to join with speaker table to get speaker information
left_join(tbl(db, "speaker") %>% as.data.frame, by = "pid") %>%
# Get party names
left_join(tbl(db, "party") %>% rename("p_name" = name) %>% as.data.frame, by = "rid") %>%
select(name, p_name, med, avg, num) %>%
# # Get rating names
left_join(tbl(db, "rating") %>% as.data.frame, by = c("med" = "aid")) %>%
mutate(avg = round(avg, digits = 2), rank = row_number()) %$%
# # Finally put in a pretty HTML table for display in markdown
htmlTable(select(., "Party" = p_name, "Rank" = rank, "Median Honesty" = label, "Average Honesty Score" = avg, "Rated Statements" = num), rnames = name, caption = "Honesty of Politically Active Entities", tfoot = "Data source: PolitiFact")
| Honesty of Politically Active Entities | |||||
| Party | Rank | Median Honesty | Average Honesty Score | Rated Statements | |
|---|---|---|---|---|---|
| Alex Sink | Democrat | 1 | True | 4 | 19 |
| Dennis Kucinich | Democrat | 2 | Mostly True | 3.84 | 25 |
| Sheldon Whitehouse | Democrat | 3 | Mostly True | 3.79 | 24 |
| Cory Booker | Democrat | 4 | Mostly True | 3.6 | 20 |
| Mark Warner | Democrat | 5 | Mostly True | 3.6 | 20 |
| Gina Raimondo | Democrat | 6 | Mostly True | 3.59 | 17 |
| Sherrod Brown | Democrat | 7 | Mostly True | 3.59 | 34 |
| Rob Portman | Republican | 8 | Mostly True | 3.57 | 47 |
| Bill Nelson | Democrat | 9 | Mostly True | 3.48 | 25 |
| David Axelrod | Democrat | 10 | Mostly True | 3.39 | 18 |
| Hillary Clinton | Democrat | 11 | Mostly True | 3.34 | 292 |
| Bernie Sanders | Independent | 12 | Mostly True | 3.25 | 107 |
| John Kasich | Republican | 13 | Mostly True | 3.25 | 64 |
| Fred Thompson | Republican | 14 | Mostly True | 3.25 | 16 |
| Bill Richardson | Democrat | 15 | Mostly True | 3.24 | 17 |
| Alan Grayson | Democrat | 16 | Mostly True | 3.18 | 34 |
| Bill White | Democrat | 17 | Mostly True | 3.08 | 26 |
| Tim Kaine | Democrat | 18 | Half-True | 3.38 | 50 |
| Nathan Deal | Republican | 19 | Half-True | 3.37 | 49 |
| Bill Clinton | Democrat | 20 | Half-True | 3.29 | 41 |
| Barack Obama | Democrat | 21 | Half-True | 3.28 | 596 |
| Jeb Bush | Republican | 22 | Half-True | 3.24 | 79 |
| John Cornyn | Republican | 23 | Half-True | 3.23 | 26 |
| Barbara Buono | Democrat | 24 | Half-True | 3.12 | 16 |
| Charlie Crist | Democrat | 25 | Half-True | 3.12 | 80 |
| George LeMieux | Republican | 26 | Half-True | 3.12 | 17 |
| Wendy Davis | Democrat | 27 | Half-True | 3.07 | 27 |
| David Cicilline | Democrat | 28 | Half-True | 3.07 | 29 |
| Gary Johnson | Libertarian | 29 | Half-True | 3.06 | 51 |
| Kay Bailey Hutchison | Republican | 30 | Half-True | 3.06 | 17 |
| Rand Paul | Republican | 31 | Half-True | 3.04 | 51 |
| Joe Biden | Democrat | 32 | Half-True | 2.99 | 75 |
| George Allen | Republican | 33 | Half-True | 2.96 | 26 |
| Paul Ryan | Republican | 34 | Half-True | 2.95 | 65 |
| Martin O’Malley | Democrat | 35 | Half-True | 2.94 | 18 |
| Tim Pawlenty | Republican | 36 | Half-True | 2.94 | 17 |
| Chris Christie | Republican | 37 | Half-True | 2.93 | 102 |
| Bob McDonnell | Republican | 38 | Half-True | 2.91 | 35 |
| Jon Huntsman | Republican | 39 | Half-True | 2.89 | 18 |
| Tammy Baldwin | Democrat | 40 | Half-True | 2.88 | 25 |
| John McCain | Republican | 41 | Half-True | 2.88 | 183 |
| Greg Abbott | Republican | 42 | Half-True | 2.86 | 43 |
| Ron Paul | Republican | 43 | Half-True | 2.85 | 40 |
| Marco Rubio | Republican | 44 | Half-True | 2.84 | 148 |
| Gwen Moore | Democrat | 45 | Half-True | 2.84 | 19 |
| Kendrick Meek | Democrat | 46 | Half-True | 2.84 | 19 |
| Lincoln Chafee | Democrat | 47 | Half-True | 2.83 | 18 |
| Russ Feingold | Democrat | 48 | Half-True | 2.81 | 21 |
| Debbie Wasserman Schultz | Democrat | 49 | Half-True | 2.81 | 47 |
| Mitch McConnel | Republican | 50 | Half-True | 2.79 | 28 |
| Rick Scott | Republican | 51 | Half-True | 2.77 | 142 |
| Karl Rove | Republican | 52 | Half-True | 2.76 | 17 |
| Ron Johnson | Republican | 53 | Half-True | 2.73 | 44 |
| Mitt Romney | Republican | 54 | Half-True | 2.7 | 206 |
| David Perdue | Republican | 55 | Half-True | 2.69 | 16 |
| Republican National Committee | Republican | 56 | Half-True | 2.68 | 34 |
| Scott Walker | Republican | 57 | Half-True | 2.67 | 172 |
| Mary Burke | Democrat | 58 | Half-True | 2.65 | 34 |
| Florida Democratic Party | Democrat | 59 | Half-True | 2.64 | 25 |
| Rudy Giuliani | Republican | 60 | Half-True | 2.6 | 47 |
| Rick Perry | Republican | 61 | Half-True | 2.59 | 169 |
| Mike Pence | Republican | 62 | Half-True | 2.58 | 38 |
| Tom Barrett | Democrat | 63 | Half-True | 2.52 | 25 |
| Republican Governors Association | Republican | 64 | Half-True | 2.5 | 18 |
| Harry Reid | Democrat | 65 | Half-True | 2.5 | 24 |
| Ted Strickland | Democrat | 66 | Half-True | 2.48 | 21 |
| Nancy Pelosi | Democrat | 67 | Half-True | 2.38 | 29 |
| John Boehner | Republican | 68 | Mostly False | 2.64 | 69 |
| Mike Huckabee | Republican | 69 | Mostly False | 2.63 | 41 |
| Eric Cantor | Republican | 70 | Mostly False | 2.56 | 34 |
| Dick Cheney | Republican | 71 | Mostly False | 2.53 | 17 |
| Carly Fiorina | Republican | 72 | Mostly False | 2.45 | 22 |
| Dan Patrick | Republican | 73 | Mostly False | 2.41 | 22 |
| Terry McAuliffe | Democrat | 74 | Mostly False | 2.4 | 30 |
| Josh Mandel | Republican | 75 | Mostly False | 2.39 | 28 |
| Crossroads GPS | Republican | 76 | Mostly False | 2.37 | 19 |
| David Dewhurst | Republican | 77 | Mostly False | 2.35 | 40 |
| Sarah Palin | Republican | 78 | Mostly False | 2.33 | 39 |
| Rick Santorum | Republican | 79 | Mostly False | 2.32 | 59 |
| Republican Party of Florida | Republican | 80 | Mostly False | 2.29 | 34 |
| Newt Gingrich | Republican | 81 | Mostly False | 2.27 | 77 |
| Tommy Thompson | Republican | 82 | Mostly False | 2.26 | 27 |
| Ted Cruz | Republican | 83 | Mostly False | 2.2 | 116 |
| Reince Priebus | Republican | 84 | Mostly False | 2.12 | 24 |
| National Republican Congressional Committee | Republican | 85 | Mostly False | 2.08 | 53 |
| Paul Broun | Republican | 86 | Mostly False | 2 | 19 |
| Allen West | Republican | 87 | Mostly False | 1.88 | 26 |
| National Republican Senatorial Committee | Republican | 88 | Mostly False | 1.87 | 30 |
| Democratic Congressional Campaign Committee | Democrat | 89 | Mostly False | 1.44 | 34 |
| Ken Cuccinelli | Republican | 90 | False | 2.2 | 20 |
| Donald Trump | Republican | 91 | False | 1.82 | 327 |
| Herman Cain | Republican | 92 | False | 1.77 | 26 |
| Facebook posts | Unaffiliated | 93 | False | 1.65 | 100 |
| Michele Bachmann | Republican | 94 | False | 1.59 | 61 |
| Ben Carson | Republican | 95 | False | 1.54 | 28 |
| Democratic Party of Wisconsin | Democrat | 96 | False | 1.5 | 24 |
| Bloggers | Unaffiliated | 97 | Pants on Fire! | 0.92 | 72 |
| Chain email | Unaffiliated | 98 | Pants on Fire! | 0.78 | 178 |
| Data source: PolitiFact |
Barack Obama appears 21st on this list followed by Vice President Joe Biden (32), Speaker of the House Paul Ryan (34), Senate Majority Leader Mitch McConnel (50), Senate Minority Leader Harry Reid (65), and House Minority Leader Nancy Pelosi (67). Finally, it seems the most dishonest Democratic individual is Terry McAuliffe, the Governor of Virginia.
We can also see what parties account for more honesty/deceit. Below I create a table with the proportion of each rating given each party is responsible for.
# A base data frame used throughout
base_df = db %>%
# Get stmnt table
tbl("stmnt") %>%
# Need to join with speaker table to get party id
left_join(tbl(db, "speaker"), by = "pid") %>%
as.data.frame %>%
# Exclude flops
filter(aid %
group_by(aid, rid) %>%
summarize(value = n()) %>%
left_join(tbl(db, "party") %>% as.data.frame, by = "rid") %>%
left_join(tbl(db, "rating") %>% as.data.frame, by = "aid") %>%
select(name, label, value) %>%
dcast(label ~ name)
## Adding missing grouping variables: `aid`
# Convert to matrix, and get proportions
r_mat = matrix(r_count[,-1] %>% as.matrix, nrow = 6, dimnames = list(r_count$label, names(r_count)[-1]))
# Order rows correctly
r_mat = r_mat[c("Pants on Fire!", "False", "Mostly False", "Half-True", "Mostly True", "True"),]
(r_mat / rowSums(r_mat)) %>%
round(digits = 2) %>%
`*`(100) %>%
htmlTable(caption = "Proportion of Statements of Certain Truthfulness Made by Members of Parties", tfoot = "Data source: PolitiFact")
## Democrat Independent Libertarian Republican Unaffiliated
## Pants on Fire! 22 0 1 54 22
## False 30 1 1 63 4
## Mostly False 34 2 1 61 2
## Half-True 43 1 2 52 1
## Mostly True 49 3 2 45 1
## True 48 2 2 48 1
Republicans account for a large share of false statements, much more than Democrats. In fact, a chi-square tests rejects the null hypothesis that statement rating and political party are independent.
# Chi-Square Test for Independence
chisq.test(r_mat)
##
## Pearson's Chi-squared test
##
## data: r_mat
## X-squared = 1260.8, df = 20, p-value % as.data.frame, by = "rid") %>%
left_join(tbl(db, "rating") %>% as.data.frame, by = "aid") %>%
select(Rating = label, Party = name.y)
mos_df$Rating %% factor(levels = c("Pants on Fire!", "Mostly False", "False", "Half-True", "Mostly True", "True"))d
mosaic(~ Party + Rating, data = mos_df, shade = TRUE, gp = shading_hsv, labeling_args = list(abbreviate_labs = c(Rating = TRUE, Party = TRUE)))
I would also like to see what people are lying about (as opposed to how much they lie). For this, I'm simply going to make a word cloud, using the Python package wordcloud (read more about it here). The code for creating the word clouds is listed below:
from os import path
from scipy.misc import imread
import matplotlib.pyplot as plt
from pylab import rcParams
import pymysql as sql
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# This line is necessary for the plot to appear in a Jupyter notebook
get_ipython().magic('matplotlib inline')
# Control the default size of figures in this Jupyter notebook
rcParams['figure.figsize'] = 30, 18
d = path.dirname(my_pics)
def get_party_statements(name, cur):
"""
:param name: string; The name of the party for which to look up data
:param cur: cursor; A pymysql cursor object
:return: dict; Contains strings with two parameters, "truth" and "lie", that consists of concatenated statements of all members in the political party identified by name
This object extracts from a database (connected to via cur) statements made by members of a party identified by name. True statements are those with at least a rating of "half-true"; all else are treated as false.
"""
party_true = ""
party_lie = ""
# Get all true statements by party
nstate = cur.execute("select text from stmnt where aid >= 3 and aid = 0 and aid = 3 and aid = 0 and aid <= 2 and pid = (select pid from speaker where name = \"" + name + "\")")
for i in range(nstate):
person_lie += " " + cur.fetchone()[0]
return {"truth": person_true, "lie": person_lie}
def generate_wordcloud(text, logo, ):
"""
:param text: string; A text string that will be turned into a word cloud
:param logo: array; An object representing the image used for masking (implicitly created by imread in scipy)
:param : string; An identifier for the to be used when creating the word cloud
Creates a word cloud from text using the specified by parameter and the mask specified by logo.
"""
wc = WordCloud(_path = , background_color="white", max_words=200, mask=logo,
stopwords=STOPWORDS.update(["said", "say", "says"]))
# generate word cloud
wc.generate(text)
# create coloring from image
image_colors = ImageColorGenerator(logo)
# show
# recolor wordcloud and show
# we could also give color_func=image_colors directly in the constructor
plt.imshow(wc.recolor(color_func=image_colors))
plt.axis("off")
plt.show()
def main():
hillary_logo = imread(path.join(d, "Hillary_for_America_2016_logo.png"))
democrat_logo = imread(path.join(d, "Democratslogo.png"))
republican_logo = imread(path.join(d, "Republicanlogo.png"))
trump_face = imread(path.join(d, "DonaldTrump_bp.png"))
conn = sql.connect(host='localhost', user = "root", passwd=my_pass, db="mysql", charset = "utf8")
cur = conn.cursor()
cur.execute("use politifactscraper;")
r_statements = get_party_statements("Republican", cur)
d_statements = get_party_statements("Democrat", cur)
u_statements = get_party_statements("Unaffiliated", cur)
hillary_statements = get_people_statements("Hillary Clinton", cur)
trump_statements = get_people_statements("Donald Trump", cur)
neutral_ = "OldNewspaperTypes"
true_ = "BodoniXT"
lie_ = "DK Coal Brush"
# Pictures!
generate_wordcloud(d_statements["truth"] + " " + d_statements["lie"], democrat_logo, neutral_)
generate_wordcloud(d_statements["truth"], democrat_logo, true_)
generate_wordcloud(d_statements["lie"], democrat_logo, lie_)
generate_wordcloud(r_statements["truth"] + " " + r_statements["lie"], republican_logo, neutral_)
generate_wordcloud(r_statements["truth"], republican_logo, true_)
generate_wordcloud(r_statements["lie"], republican_logo, lie_)
generate_wordcloud(hillary_statements["truth"] + " " + hillary_statements["lie"], hillary_logo, neutral_)
generate_wordcloud(hillary_statements["truth"], hillary_logo, true_)
generate_wordcloud(hillary_statements["lie"], hillary_logo, lie_)
generate_wordcloud(trump_statements["truth"] + " " + trump_statements["lie"], trump_face, neutral_)
generate_wordcloud(trump_statements["truth"], trump_face, true_)
generate_wordcloud(trump_statements["lie"], trump_face, lie_)
generate_wordcloud(u_statements["truth"] + " " + u_statements["lie"], internet_logo, neutral_)
generate_wordcloud(u_statements["truth"] , internet_logo, true_)
generate_wordcloud(u_statements["lie"], internet_logo, lie_)
cur.close()
conn.close()
if __name__ == '__main__':
main()
In the process of making these word clouds, I used the s Old Newspaper Types, Bodoni XT, and DK Coal Brush. The source for the Donald Trump mask is here (after some editing), the WordPress, GMail, and Facebook logos were found via Google search, and the rest are from WikiMedia.
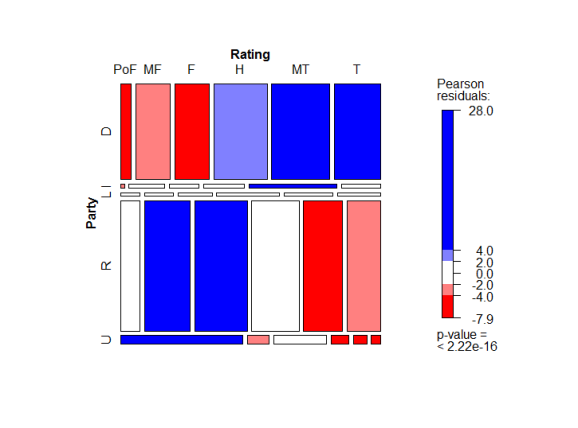
Mosaic Plot
I first show the mosaic plot I created earlier. As you can see, Republicans account for more falsehood than Democrats, more than if you had expected there to be no relationship between political party and truthfulness. (Blue indicates more than expected, red less than expected.)

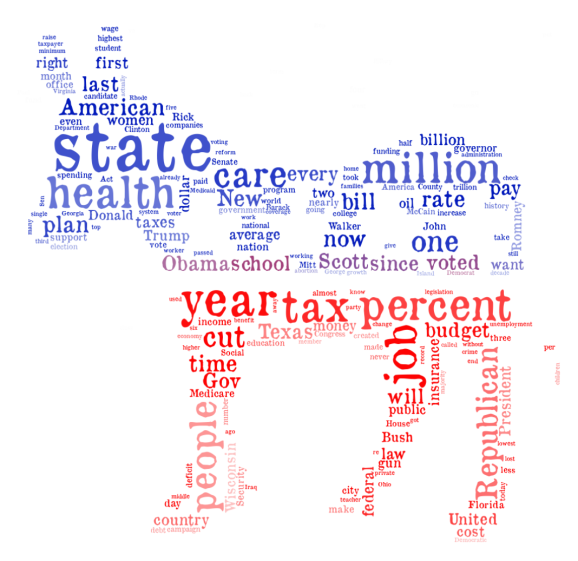
All Statements Word Clouds
First, I show a word cloud for all statements made by the entities considered that were rated by PolitiFact, true or not.
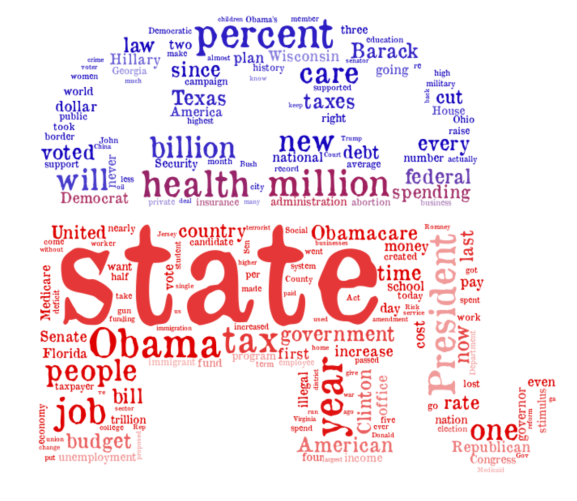






True Statements Word Clouds
Next I show the word clouds formed by the statements made by the entities considered that PolitiFact has rated as being at least “half-true”.



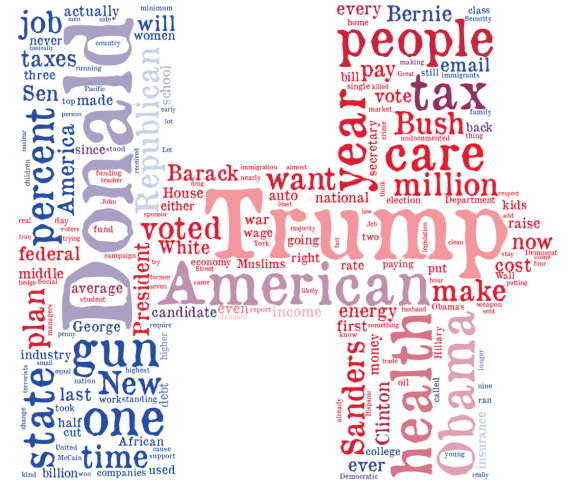
False Statements Word Clouds
Finally, I show the word clouds formed by the statements made by the entities considered that PolitiFact has rated as being at least as dishonest as “mostly false”.





What do we see? Naturally, all of this is in the eye of the beholder (word clouds are not “scientific”), but I noticed some patterns. Naturally, the presidential candidates mention their opponents frequently, and they both say many things true or false that involve their opponents. Meanwhile, the political party word clouds are more focused on policy. The words “Scott”, “Walker”, and “Wisconson” appear a lot in the Democrats’ “lie” cloud (perhaps thanks to the Wisconsin Democratic Party, the most dishonest entity in my earlier lists), and Republicans lie a lot about one person: Obama. As for Facebook posts, chain e-mails, and bloggers, they like to talk about Obama, and my guess is that lies propagated through these channels generally suggest something new will be done by Obama this year that will hurt people.
Thoughts on PolitiFact
All of the data used in this source comes from one source: PolitiFact. There are those who believe that this makes these results questionable. I would not be a good statistician if I did not disclose potential problems, so here I discuss potential problems my analysis faces.
Political Bias
Upon seeing a result saying that PolitiFact rates Republicans as more dishonest than Democrats, conservatives may immediately reach for the “biased” argument, that the people responsible for maintaining PolitiFact (the Tampa Bay Times) have a political agenda that reflects in their scores, and thuse we should not trust their data.
Sure, “bias” (in this typical sense of the word) is a possibility. I will acknowledge the possibility. Unfortunately, though, many have taken to accusing supposedly authoritative sources of being “biased” whenever those sources contradict their existing beliefs. Trump, and especially Trump supporters, have turned this into an art, but Fox News has been laying the foundation for this line of attack for decades and many on the left now resort to it as well (I felt the need to have this discussion after a Bernie Sanders supporter, in a Facebook argument, accused PolitiFact of being biased against Bernie Sanders in favor of Hillary Clinton). It’s a wonderful line of attack, because there’s usually no way for the victim to prove she is not “biased”, or the accuser cares little for whatever proof she finds.
Accusing PolitiFact of being “biased” (along with many other traditional, well-reputed media outlets) quickly angers me. It fuels tribalism by eroding our “common ground” information sources that we accept as reporting an objective, baseline “truth” from which we can then debate the approach to take to society’s problems. Continuing along this path allows one to eventually paint reality as he hallucinates it to be, and anyone who disagrees with that vision with an argument as simple as “that’s not true” is “biased”. If we continue to refuse to accept opposing views because the source is “biased”, we will no longer have a functioning democracy; minds will never change, we will become locked into our tribes of yes-men with common broken-clock media, and voting will simply become a battle of wills between two equally mad fictions.
So if you’re going to criticize these results because PolitiFact is “biased”, you’re further hurtling us to post-truth politics. I will resist this dangerous trend.
Curation Bias
While I will simply refuse to entertain the possibility of political bias, there are other ways this data could become “biased” that have little to do with any political beliefs by the individuals at PolitiFact. Fact checking is not a science, and other sources of bias could be introduced.
When I mention “curation bias”, I reference the fact that fact-checkers must decide what to fact-check. They may be drawn to fact-check statements that:
- Are hot button issues (as a former intern in a lobbying firm, I can promise you that a lot more goes on in Washington than just the headline makers, much of which is important but not nearly as exciting or “sexy” to discuss)
- Are made by prominent individuals (Barack Obama has a lot of his statements rated, unlike Rep. Rob Bishop, who’s been in Congress for fourteen years and has not a single statement on record; I was also sad to see Jill Stein did not have a file)
- Sound like they may be false (so there is a propensity to show a statement is false than show a statement is true; additionally, the writer may have some initial idea about the truth in the statement, so if a statement with many technical details about an esoteric topic is made, the fact-checker may not consider it)
These are more serious threats to the quality of this analysis, ones for which there is no fix and for which the effect is unclear. I won’t dare to claim that my analysis is immune to them and can’t be tainted by bias. Nevertheless, I believe that if we want an idea of honesty in politics, we can’t do much better than use this data.
Conclusion
On Tuesday, this nightmare of an election will be over. Americans will cast their votes, and hopefully they make the right decision. I will not lie: I am very nervous about this election. As of this writing, FiveThirtyEight is showing a close election. I hope that this analysis will highlight the source of dishonesty in this election, and people will not judge both sides as equally bad or equally guilty. That is simply not the state of reality, and if we are going to move past the problems we have seen in our democracy, we will need to come to terms with reality.


R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.