
Introducing xda: R package for exploratory data analysis
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
This R package contains several tools to perform initial exploratory analysis on any input dataset. It includes custom functions for plotting the data as well as performing different kinds of analyses such as univariate, bivariate and multivariate investigation which is the first step of any predictive modeling pipeline. This package can be used to get a good sense of any dataset before jumping on to building predictive models. You can install the package from GitHub.
The functions currently included in the package are mentioned below:
- numSummary(mydata) function automatically detects all numeric columns in the dataframe mydata and provides their summary statistics
- charSummary(mydata) function automatically detects all character columns in the dataframe mydata and provides their summary statistics
- Plot(mydata, dep.var) plots all independent variables in the dataframe mydata against the dependant variable specified by the dep.var parameter
- removeSpecial(mydata, vec) replaces all special characters (specified by vector vec) in the dataframe mydata with NA
- bivariate(mydata, dep.var, indep.var) performs bivariate analysis between dependent variable dep.var and independent variable indep.var in the dataframe mydata
Installation
To install the xda package, devtools package needs to be installed first. To install devtools, please follow instructions here.
Then, use the following commands to install xda:
library(devtools)
install_github("ujjwalkarn/xda")
Usage
For all examples below, the popular iris dataset has been used. The data set consists of 50 samples from each of three species of Iris (Iris setosa, Iris virginica and Iris versicolor).
library(xda) ## to view a comprehensive summary for all numeric columns in the iris dataset numSummary(iris) ## n = total number of rows for that variable ## miss = number of rows with missing value ## miss% = percentage of total rows with missing values ((miss/n)*100) ## 5% = 5th percentile value of that variable (value below which 5 percent of the observations may be found) ## the percentile values are helpful in detecting outliers

## to view a comprehensive summary for all character columns in the iris dataset charSummary(iris) ## n = total number of rows for that variable ## miss = number of rows with missing value ## miss% = percentage of total rows with missing values ((n/miss)*100) ## unique = number of unique levels of that variable ## note that there is only one character column (Species) in the iris dataset

## to perform bivariate analysis between 'Species' and 'Sepal.Length' in the iris dataset bivariate(iris,'Species','Sepal.Length') ## bin_Sepal.Length = 'Sepal.Length' variable has been binned into 4 equal intervals (original range is [4.3,7.9]) ## for each interval of 'Sepal.Length', the number of samples from each category of 'Species' is shown ## i.e. 39 of the 50 samples of Setosa have Sepal.Length is in the range (4.3,5.2], and so on. ## the number of intervals (4 in this case) can be customized (see documentation)

## to plot all other variables against the 'Petal.Length' variable in the iris dataset Plot(iris,'Petal.Length')

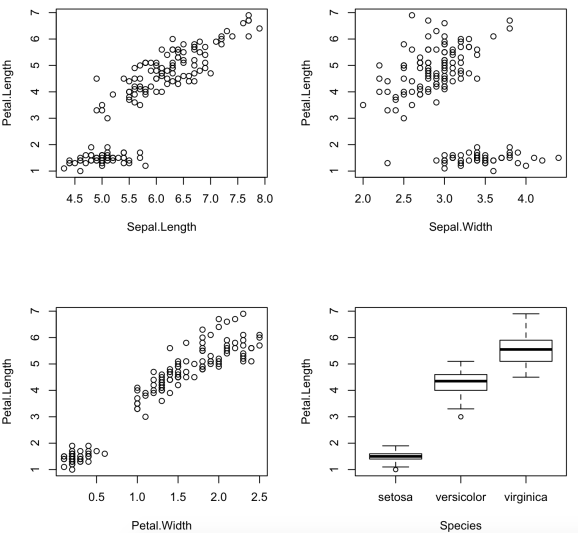
The package is constantly under development and more functionalities will be added soon. Will also add this to CRAN in the coming days. Pull requests to add more functions are welcome!

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.