
The Rise of Transparent Data Journalism – The BuzzFeed Tennis Match Fixing Data Analysis Notebook
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
The news today was lead in part by a story broken by the BBC and BuzzFeed News – The Tennis Racket – about match fixing in Grand Slam tennis tournaments. (The BBC contribution seems to have been done under the ever listenable File on Four: Tennis: Game, Set and Fix?)
One interesting feature of this story was that “BuzzFeed News began its investigation after devising an algorithm to analyse gambling on professional tennis matches over the past seven years”, backing up evidence from leaked documents with “an original analysis of the betting activity on 26,000 matches”. Feature detecting algorithms such as this (where the feature is an unusual betting pattern) are likely to play an increasing role in the discovery of stories from data, step 2 in the model described in this recent Tow Center for Digital Journalism Guide to Automated Journalism:]
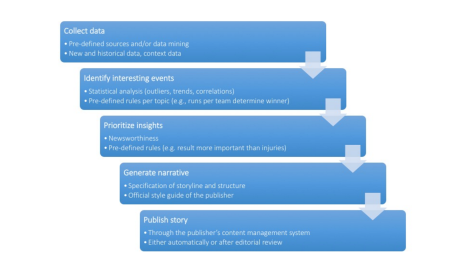
See also: OUseful.info: Notes on Robot Churnalism, Part I – Robot Writers
Another interesting aspect of the story behind the story was the way in which BuzzFeed News opened up the analysis they had applied to the data. You can find it described on Github – Methodology and Code: Detecting Match-Fixing Patterns In Tennis – along with the data and a Jupyter notebook that includes the code used to perform the analysis: Data and Analysis: Detecting Match-Fixing Patterns In Tennis.

You can even run the notebook to replicate the analysis yourself, either by downloading it and running it using your own Jupyter notebook server, or by using the online mybinder service: run the tennis analysis yourself on mybinder.org.
(I’m not sure if the BuzzFeed or BBC folk tried to do any deeper analysis, for example poking into point summary data as captured by the Tennis Match Charting Project? See also this Teniis Visuals project that makes use of the MCP data. Tennis etting data is also collected here: tennis-data.co.uk. If you’re into the idea of analysing tennis stats, this book is one way in: Analyzing Wimbledon: The Power Of Statistics.)
So what are these notebooks anyway? They’re magic, that’s what!:-)
The Jupyter project is an evolution of an earlier IPython (interactive Python) project that included a browser based notebook style interface for allowing users to write and execute code, as well as seeing the result of executing the code, a line at a time, all in the context of a “narrative” text document. The Jupyter project funding proposal describes it thus:
[T]he core problem we are trying to solve is the collaborative creation of reproducible computational narratives that can be used across a wide range of audiences and contexts.
…
[C]omputation in science is ultimately in service of a result that needs to be woven into the bigger narrative of the questions under study: that result will be part of a paper, will support or contest a theory, will advance our understanding of a domain. And those insights are communicated in papers, books and lectures: narratives of various formats.The problem the Jupyter project tackles is precisely this intersection: creating tools to support in the best possible ways the computational workflow of scientific inquiry, and providing the environment to create the proper narrative around that central act of computation. We refer to this as Literate Computing, in contrast to Knuth’s concept of Literate Programming, where the emphasis is on narrating algorithms and programs. In a Literate Computing environment, the author weaves human language with live code and the results of the code, and it is the combination of all that produces a computational narrative.
…
At the heart of the entire Jupyter architecture lies the idea of interactive computing: humans executing small pieces of code in various programming languages, and immediately seeing the results of their computation. Interactive computing is central to data science because scientific problems benefit from an exploratory process where the results of each computation inform the next step and guide the formation of insights about the problem at hand. In this Interactive Computing focus area, we will create new tools and abstractions that improve the reproducibility of interactive computations and widen their usage in different contexts and audiences.
The Jupyter notebooks include two types of interactive cell – editable text cells into which you can write simple markdown and HTML text that will be rendered as text; and code cells into which you can write executable code. Once executed, the results of that execution are displayed as cell output. Note that the output from a cell may be text, a datatable, a chart, or even an interactive map.
One of the nice things about the Jupyter notebook project is that the executable cells are connected via the Jupyter server to a programming kernel that executes the code. An increasing number of kernels are supported (e.g. for R, Javascript and Java as well as Python) so once you hook in to the Jupyter ecosystem you can use the same interface for a wide variety of computing tasks.
There are multiple ways of running Jupyter notebooks, including the mybinder approach described above, – I describe several of them in the post Seven Ways of Running IPython Notebooks.
As well as having an important role to play in reproducible data journalism and reproducible (scientific) research, notebooks are also a powerful, and expressive, medium for teaching and learning. For example, we’re just about to star using Jupyter notebooks, delivered via a virtual machine, for the new OU course Data management and analysis.
We also used them in the FutureLearn course Learn to Code for Data Analysis, showing how code could be used a line at a time to analyse a variety of opendata sets from sources such as the World Bank Indicators database and the UN Comtrade (import /export data) database.
PS for sports data fans, here’s a list of data sources I started to compile a year or so ago: Sports Data and R – Scope for a Thematic (Rather than Task) View? (Living Post).

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.