

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
I came across this post written by a James Cheshire that introduces people to the topic of spatial data using R. I don’t know a single thing of using spatial information so i thought i should give it a shot.
I kept looking for local Malaysian sites that show user posts of any kind that might include coordinates so that i might start plotting the information. Couldn’t find anything, so a random site as a sample. I couldn’t just plot data from every city in the US so i settled for New York – Manhattan to be specific.
As always, inspected the HTML code on the website and it was kind of nice to see that the code was a whole lot more structured than i had thought it would be. The information that is put up with each post is much more comprehensive than what you will normally see in Malaysian websites. For instance, the post details out whether the tenant is allowed to have pets, or small pets, or cats only; and if the laundry is “in-unit” or in a laundry room; whether there is a doorman and if there is some outdoor space; etc. The photos posted are also very clear and thorough, and more importantly…there is a map showing where the unit is located. The map is dynamic and interactive, i.e. it switches the location automatically according to which post you mouse over.
After finding out how to get the coordinate data from the posts, i came up with the code below that would scrape through select information from each post:
library(dplyr)
library(rvest)
library(stringr)
link = #"sample website URL here"
pg = 1
link = paste(link, as.character(pg), sep = "")
htLink = html(link)
#Last page on search results
htLink %>% html_nodes("#paginationBottom") %>% html_text() -> x
str_replace_all(x, "\n", "") -> x
str_replace_all(x, " ", "") -> x
str_locate_all(pattern = "...", x[1]) -> l
#***NOTE: Might not always work depending on how many search results there are***
l[[1]][3,1] %>% as.integer() -> m
l[[1]][3,2] %>% as.integer() -> n
substr(x, m+1,nchar(x)-1) %>% as.integer() -> limit
#***__________________________________________________________________________***
df = data.frame()
#Link to post
htLink %>% html_nodes(".listing-results") %>%
html_nodes(".listing-title") %>% html_attr("href") -> a
y <- seq(1,length(a), by=2)
a[y] -> a
df[1:length(a),1] = a
#Rental rate
htLink %>% html_nodes(".listing-results") %>%
html_nodes(".listing-title") %>% html_text() -> b
y <- seq(1,length(b), by=2)
b[y] -> b
df[1:length(b),2] = b
#Location
htLink %>% html_nodes(".listing-results") %>%
html_nodes(".listing-address") %>% html_text() -> c
y <- seq(1,length(c), by=2)
c[y] -> c
df[1:length(c),3] = c
#Layout
htLink %>% html_nodes(".listing-results") %>%
html_nodes(".listing-size") %>% html_text() -> d
y <- seq(1,length(d), by=2)
d[y] -> d
df[1:length(d),4] = d
#Amenities
htLink %>% html_nodes(".listing-results") %>%
html_nodes(".amenities") %>% html_text() -> e
str_replace_all(e, "\n", "") -> e
str_replace_all(e, " ", "") -> e
df[1:length(e),5] = e
#COORDINATES
#Latitude
htLink %>% html_nodes("div") %>% html_attr("data-latitude") -> f
f[!is.na(f)] -> f
df[1:length(f),6] = f
#Longitude
htLink %>% html_nodes("div") %>% html_attr("data-longitude") -> g
g[!is.na(g)] -> g
df[1:length(g),7] = g
#________LOOP STARTS HERE____________________________________________
df2 = data.frame()
for(i in 2:limit){
link = #"sample website URL link here"
pg = i
link = paste(link, as.character(pg), sep = "")
htLink = html(link)
#Link to post
htLink %>% html_nodes(".listing-results") %>%
html_nodes(".listing-title") %>% html_attr("href") -> a
y <- seq(1,length(a), by=2)
a[y] -> a
df2[1:length(a),1] = a
#Rental rate
htLink %>% html_nodes(".listing-results") %>%
html_nodes(".listing-title") %>% html_text() -> b
y <- seq(1,length(b), by=2)
b[y] -> b
df2[1:length(b),2] = b
#Location
htLink %>% html_nodes(".listing-results") %>%
html_nodes(".listing-address") %>% html_text() -> c
y <- seq(1,length(c), by=2)
c[y] -> c
df2[1:length(c),3] = c
#Layout
htLink %>% html_nodes(".listing-results") %>%
html_nodes(".listing-size") %>% html_text() -> d
y <- seq(1,length(d), by=2)
d[y] -> d
df2[1:length(d),4] = d
#Amenities
htLink %>% html_nodes(".listing-results") %>%
html_nodes(".amenities") %>% html_text() -> e
str_replace_all(e, "\n", "") -> e
str_replace_all(e, " ", "") -> e
df2[1:length(e),5] = e
#COORDINATES
#Latitude
htLink %>% html_nodes("div") %>% html_attr("data-latitude") -> f
f[!is.na(f)] -> f
df2[1:length(f),6] = f
#Longitude
htLink %>% html_nodes("div") %>% html_attr("data-longitude") -> g
g[!is.na(g)] -> g
df2[1:length(g),7] = g
rbind(df, df2) -> df
df2 = data.frame()
}
headers = c("Links", "Rental", "Location", "Layout", "Amenities", "Latitude", "Longitude")
names(df) = headers
write.csv(df, "Compiled_Ext.csv", row.names = FALSE)
The code didn’t really take that long to scrape the information. The dimensions of the dataframe that the code spits out is 39,223 rows by 7 columns. The 7 columns are:
1. The link to the post (Link)
2. The rental, as displayed in the website (Rental)
3. The address (Location)
4. The layout of the house, i.e. number of rooms and bathrooms (Layout)
5. List of amenities (Amenities)
6. Latitude (Latitude)
7. Longitude (Longitude)
Obviously the raw data would need to be cleaned a little bit further, however i was sort of fixated on the Amenities column; mainly because it appears that this columns can be broken down to several other columns depending on whether a particular amenity was available or not.
That said, i made the following changed to the original extraction:
1. Changed the Rental column to class numeric by removing the comma and dollar sign and subsequently coercing all the figured to numeric. The new column is called Rental.Num.
2. The Layout column was then mutated into two separate columns: Bed and Bath. The value in each row of these new columns was coerced to class integer.
3. After looking at it a little more closely, it would appear that the Amenities column can be mutated into 13 new columns:
Pets: The type of pets that are allowed. The values are All, Cats, Approval, or Small Pets
Elevator: If there is an elevator in the building.
Gym: The availability of a gym in the building.
Fireplace: If the apartment comes with a fireplace.
Laundry: The availability of any laundry facilities. The values are either “LRoom”, which stands for laundry room; or “In-Unit”, which means the laundry room is inside the apartment.
Pre.Post.War: If the apartment was built pre or post WW-II. The values are either “Pre” or “Post”.
Doorman: If there is a doorman in the building.
Square.Feet: This a measure of the size of the apartment, measured in square feet. A lot of the people who posted on the website did not state flat out the size of the apartment. The values were extracted from the Amenities columns and then coerced into class numeric.
Parking: I’m not entirely certain if this means that each the apartment comes with a parking lot, or if there are parking lots that are available outside the building. The default values are the same.
Furnished: If the apartment is furnished or not.
Outdoor.Space: I did not understand the significance of this amenity too. It also has the same default values.
The code used to do this is below:
library(stringr)
library(dplyr)
df -> df2
nHeaders = c("Bed", "Bath", "Pets", "Elevator", "Gym", "Dishwasher",
"Fireplace", "Laundry", "Pre.Post.War", "Doorman",
"Square.Feet", "Parking", "Furnished", "Outdoor.Space")
for(i in 1:length(nHeaders)){
df2[,ncol(df2)+1] = NA
}
names(df) -> oHeaders
Headers = c(oHeaders, nHeaders)
names(df2) = Headers
#Layout: Bed always comes before bath
bedBath <- df2[, "Layout"]
for(i in 1:length(bedBath)){
gregexpr(",", bedBath[i])[[1]] -> loc
bedBath[i] <- substr(bedBath[i], 0, loc-1)
}
str_replace_all(bedBath, "BR", "") -> bedBath
bedBath <- as.numeric(bedBath)
df2[,"Bed"] <- bedBath
bedBath <- df2[, "Layout"]
#Exact same code above, but for bath
for(i in 1:length(bedBath)){
gregexpr(",", bedBath[i])[[1]] -> loc
bedBath[i] <- substr(bedBath[i], loc+1, nchar(bedBath[i]))
}
str_replace_all(bedBath, "BA", "") -> bedBath
bedBath <- as.numeric(bedBath)
df2[,"Bath"] <- bedBath
#______
#Elevator, Gym, Dishwasher, Fireplace, Doorman, Parking, Furnished, OutdoorSpace
for(i in 1:nrow(df2)){
if(grepl("elevator", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Elevator"] <- "Y"}else{df2[i,"Elevator"] <- "N"}
if(grepl("gym", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Gym"] <- "Y"}else{df2[i,"Gym"] <- "N"}
if(grepl("fireplace", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Fireplace"] <- "Y"}else{df2[i,"Fireplace"] <- "N"}
if(grepl("doorman", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Doorman"] <- "Y"}else{df2[i,"Doorman"] <- "N"}
if(grepl("parking", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Parking"] <- "Y"}else{df2[i,"Parking"] <- "N"}
if(grepl("furnished", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Furnished"] <- "Y"}else{df2[i,"Furnished"] <- "N"}
if(grepl("outdoor space", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Outdoor.Space"] <- "Y"}else{df2[i,"Outdoor.Space"] <- "N"}
}
#________
#Laundry, Post-Pre War, Pets
for(i in 1:nrow(df2)){
if(grepl("laundry room", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Laundry"] <- "LRoom"}else{
if(grepl("in-unit laundry", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Laundry"] <- "In-Unit"}else{
if(grepl("laundry", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Laundry"] <- "Y"}
}
}
if(grepl("post war", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Pre.Post.War"] <- "Post"}else{
if(grepl("pre war", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Pre.Post.War"] <- "Pre"}
}
if(grepl("pets allowed", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Pets"] <- "All"}else{
if(grepl("cats only", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Pets"] <- "Cats"}else{
if(grepl("small dogs", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Pets"] <- "Small"}else
if(grepl("approved pets", df2[i,"Amenities"], ignore.case = TRUE)){df2[i,"Pets"] <- "Approval"}
}
}
#SquareFeet
if(grepl("sq. ft.", df2[i,"Amenities"], ignore.case = TRUE)){
gregexpr("Sq. Ft.", df2[i,"Amenities"], ignore.case = FALSE)[[1]][1] - 2 -> loc
substr(df2[i,"Amenities"], 0, loc) %>%
as.numeric() -> df2[i, "Square.Feet"]
}
}
#Add new variable for rentals
rentals <- df2[,"Rental"]
str_replace_all(rentals, "\\$", "") %>%
str_replace_all(pattern = ",", replacement = "") %>%
as.numeric() -> rentals
df2[,"Rental.Num"] <- rentals
#Backup file
write.csv(df2, "Compiled_N_Variables.csv", row.names = FALSE)
Final_df <- select(df2, Location, 6:22)
So the final compiled dataframe has 39223 rows and 22 variables. Since i won’t be using quite a few of these columns, i took a subset of 18 variables from the compiled dataframe. Since the main reason why i needed coordinate information is to try out plotting data from shapefiles, i’ll only be plotting just a couple of graphs that depict the number of posts per layout.
Final_df2 <- Final_df
Final_df2 <- filter(Final_df2, Bed != "NA")
Final_df2$Bed <- as.factor(Final_df2$Bed)
Final_df2$Bath <- as.factor(Final_df2$Bath)
Final_df2 %>% group_by(Bed, Bath) %>% summarise(Count = length(Bed)) -> Bed_t
x = seq(0, 20000, by = 1000)
ggplot(Bed_t, aes(x = reorder(Bed, -Count), y = Count, fill = Bath)) +
geom_bar(stat = "identity") + scale_y_continuous(breaks = x) +
ggtitle("Number of posts by Bed and Bath") + xlab("Bed") + ylab("Number of posts") +
theme(axis.text.y=element_text(face="bold", size=13, color="black"),
axis.text.x=element_text(face="bold", size=13, color="black"),
plot.title=element_text(face="bold", size=16, color="black"))
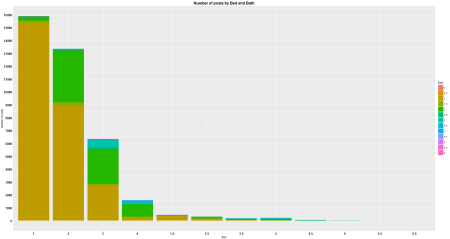

Final_df2 <- Final_df
summary(select(Final_df2, Bed, Bath, Rental.Num))
Final_df2 = filter(Final_df2, Bed != "NA", Rental.Num <= 30000)
x = seq(0, 32000, by = 2000)
ggplot(Final_df2, aes(x = as.factor(Bed), y = Rental.Num)) +
geom_boxplot(color = "navy", outlier.colour = NA) + scale_y_continuous(breaks = x) +
theme(axis.text.y=element_text(face = "bold", color = "black", size = 13),
axis.text.x=element_text(face = "bold", color = "black", size = 13),
plot.title=element_text(size=16, face = "bold", color = "Black")) +
xlab("Bedrooms") + ylab("Rental") + ggtitle("Boxplot: Rental VS No. of Bedrooms") +
stat_summary(fun.y = "mean", geom="point", shape = 22, size = 2, fill = "red")
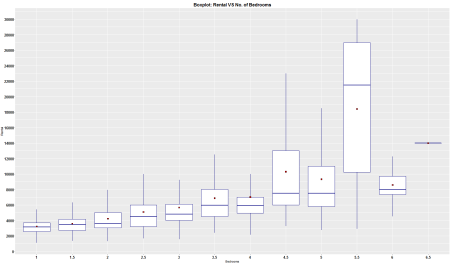

It appears that there are plenty of apartments out there for people looking for a 1 bedroom and a 2 bedroom layout. Since these are apartments in Manhattan, i have no idea what neighborhoods are considered fancy or what rental rate is considered excessive. So i can’t really give much insight on the second graph. As a sidenote, i turned off the outlier dots in the boxplot. In order to show the outliers, the part that says outlier.color = NA would need to be removed.
Moving on to plotting the coordinates. I initially thought that using the OpenStreetMap package would be helpful in this case, however i just didn’t know how to change the coordinates on the map to Lat/Lon. Much to my ignorance, it would appear that there are quite a number of different coordinate methods out there.
I finally settled with just using a shapefile that was available for download on the NYC Planning website. Using ggplot2’s fortify() function, the shapefile can be converted into a dataframe that can then be understood by ggplot2.
Started out with just plotting the data from the shapefile, and what i got was this:
Final_df2 <- Final_df Final_df2 <- filter(Final_df2, Bed != "NA") Final_df2 <- filter(Final_df2, Latitude != 0) ggplot(data = Final_df2, aes(x = Longitude, y = Latitude)) + geom_polygon(data = map, aes(x = long, y = lat, group = group))
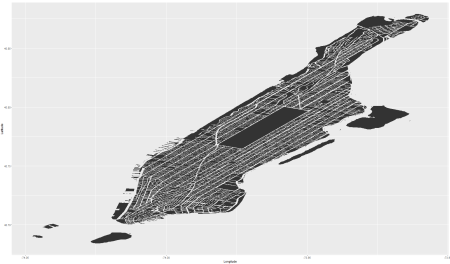
Needless to say, not exactly the most aesthetically pleasing plot i’ve done. Before i fix the distortion in the map, i need to figure out how to plot contours in ggplot2. Nothing a little googling can’t fix. This is the code that i used:
Final_df2 <- Final_df Final_df2 <- filter(Final_df2, Bed != "NA") Final_df2 <- filter(Final_df2, Latitude != 0) ggplot(data = Final_df2, aes(x = Longitude, y = Latitude)) + stat_density2d()
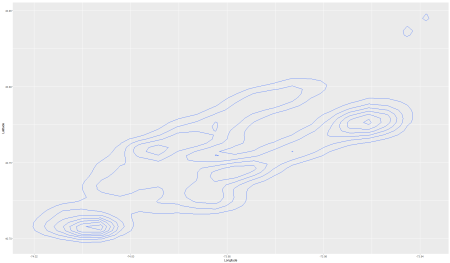

If you’re thinking what i’m thinking, you’ll notice that the contour plot has a shape that a little similar to the Manhattan plot i plotted earlier. The goal is to figure how to put both plots on the same graph, and then adjust for any colors and distortions.
ggplot(data = Final_df2, aes(x = Longitude, y = Latitude)) + geom_polygon(data = map, aes(x = long, y = lat, group = group)) + stat_density2d()

So far so good. Now i’m going to remove the grid background, the axes ticks and labels:
ggplot(data = Final_df2, aes(x = Longitude, y = Latitude)) +
geom_polygon(data = map, aes(x = long, y = lat, group = group)) + stat_density2d() +
theme(axis.text=element_blank(), panel.grid=element_blank(), axis.title=element_blank(),
axis.ticks.x=element_blank(), axis.ticks.y=element_blank(), legend.position="none",
panel.background=element_blank())

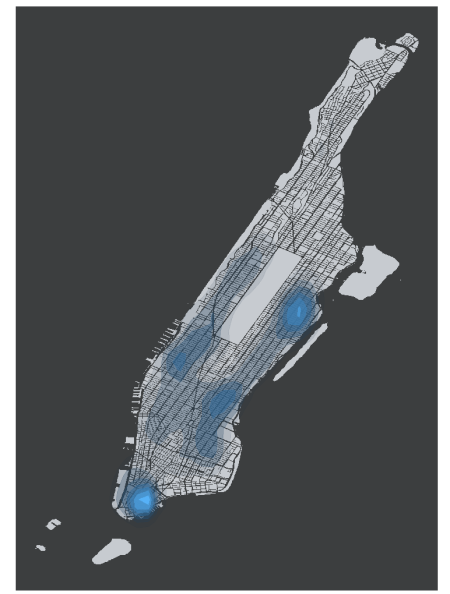
Mapping the alpha, fill, and color of the contours; and also the fill color of the map and background; and adding the coord_equal() function:
Final_df2 <- Final_df
Final_df2 <- filter(Final_df2, Latitude > 0)
Final_df2 <- filter(Final_df2, Bed != "NA")
ggplot(data = Final_df2, aes(x = Longitude, y = Latitude)) +
geom_polygon(data = map, aes(x = long, y = lat, group = group), , fill="#C7CBD0") +
stat_density2d(aes(alpha=..level.., fill=..level.., color=..level..), geom="polygon") +
theme(axis.text=element_blank(), panel.background=element_rect(fill = "#3C3E3F"),
panel.grid=element_blank(), axis.title=element_blank(),
axis.ticks.x=element_blank(), axis.ticks.y=element_blank(),
legend.position="none") + coord_equal()

And finally, just changing the the colors of the contours to the traditional green-amber-red heat map:
Final_df2 <- Final_df
Final_df2 <- filter(Final_df2, Latitude > 0)
Final_df2 <- filter(Final_df2, Bed != "NA")
ggplot(data = Final_df2, aes(x = Longitude, y = Latitude)) +
geom_polygon(data = map, aes(x = long, y = lat, group = group), , fill="#C7CBD0") +
stat_density2d(aes(alpha=..level.., fill=..level.., color=..level..), geom="polygon") +
theme(axis.text=element_blank(), panel.background=element_rect(fill = "#3C3E3F"),
panel.grid=element_blank(), axis.title=element_blank(),
axis.ticks.x=element_blank(), axis.ticks.y=element_blank(),
legend.position="none") + coord_equal() +
scale_fill_gradient(low = "#3BE819", high = "#B5170B") +
scale_color_gradient(low = "#3BE819", high = "#B5170B")
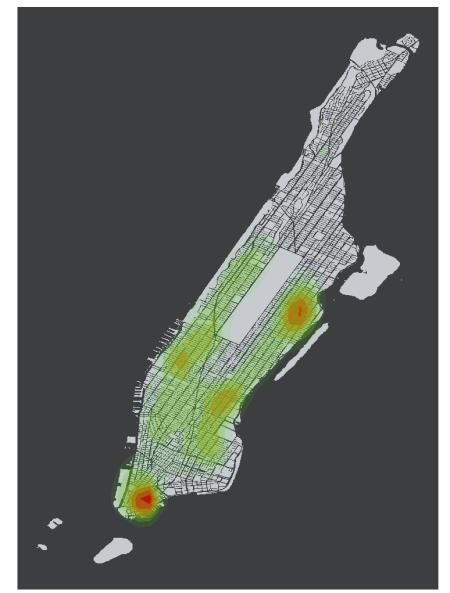

Again, i wouldn’t know much about neighborhoods in NYC, but judging from a quick check in Google Maps…the locations with the most posts are in Murray Hill and/or Midtown East, and the Upper West Side. I’m kind of interested to see how the result would be if i added a facet_wrap() to the code:
Final_df2 <- Final_df
Final_df2 <- filter(Final_df2, Latitude > 0)
Final_df2 <- filter(Final_df2, Bed != "NA")
ggplot(data = Final_df2, aes(x = Longitude, y = Latitude)) +
geom_polygon(data = map, aes(x = long, y = lat, group = group), , fill="#C7CBD0") +
stat_density2d(aes(alpha=..level.., fill=..level.., color=..level..), geom="polygon") +
theme(axis.text=element_blank(), panel.background=element_rect(fill = "#3C3E3F"),
panel.grid=element_blank(), axis.title=element_blank(),
axis.ticks.x=element_blank(), axis.ticks.y=element_blank(),
legend.position="none") + coord_equal() +
scale_fill_gradient(low = "#3BE819", high = "#B5170B") +
scale_color_gradient(low = "#3BE819", high = "#B5170B") + facet_wrap(~Bed)
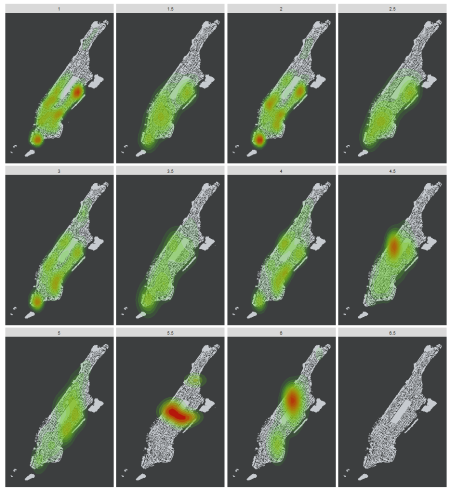

Not as appealing as i thought it would be. Perhaps if i combine the 2.5 bedroom category into the 3 bedroom, and the 3.5 to the 4 bedroom; it would perhaps look a little better. It would’ve also been better if i could plot the same map but having the colors mapped to the rental rate. That would enable me to filter a particular apartment layout, e.g. 1 Bed 1 Bath, and see which neighborhoods have the highest rental rates. But i ran into some trouble on plotting that function. For now, this’ll have to do.
If you’re interested to see how the layout of the output actually looks, let me know and i can help out.
Tagged: data, programming, r, rstats, scraping, tidy data


R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.