
Introducing Distributed Data-structures in R
[social4i size=”large” align=”float-right”]
 Due to R’s popularity as a data mining tool, many Big Data systems expose an R based interface to users. However, these interfaces are custom, non-standard, and difficult to learn.
Earlier in the year, we hosted a workshop on distributed computing in R. You can read about the event here. A brief summary of the workshop is: well-known R contributors from industry, academia, and R-core members discussed whether we can standardize the interface for distributed computing. It should encourage people to write portable distributed applications in R.
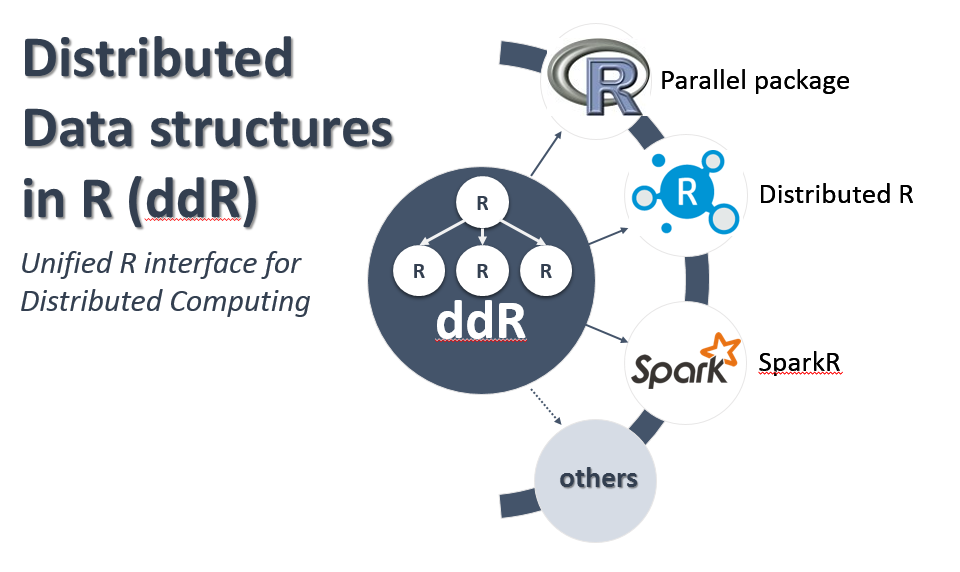
For the past few months, Edward Ma (HP), Michael Lawrence (R-core, Genentech), and I have used the feedback from the workshop to create such an interface called ddR – Distributed Data-structures in R. The main goal of the “ddR” package is to provide a simple, generic data-structures, and functions that works across different backends such as R’s “parallel” package, Spark, HP Distributed R, and others (Fig. 1). For example, you should be able to prototype your application, on your laptop, using “ddR” and R’s parallel package, and then deploy the same application on your production environment running Spark, Distributed R, or something else.
Due to R’s popularity as a data mining tool, many Big Data systems expose an R based interface to users. However, these interfaces are custom, non-standard, and difficult to learn.
Earlier in the year, we hosted a workshop on distributed computing in R. You can read about the event here. A brief summary of the workshop is: well-known R contributors from industry, academia, and R-core members discussed whether we can standardize the interface for distributed computing. It should encourage people to write portable distributed applications in R.
For the past few months, Edward Ma (HP), Michael Lawrence (R-core, Genentech), and I have used the feedback from the workshop to create such an interface called ddR – Distributed Data-structures in R. The main goal of the “ddR” package is to provide a simple, generic data-structures, and functions that works across different backends such as R’s “parallel” package, Spark, HP Distributed R, and others (Fig. 1). For example, you should be able to prototype your application, on your laptop, using “ddR” and R’s parallel package, and then deploy the same application on your production environment running Spark, Distributed R, or something else.
 The first release of the “ddR” package is now available on CRAN! You can install it using install.packages(“ddR”) or download the code from the GitHub repo: https://github.com/vertica/ddR. Currently, it supports the “parallel” package in R and HP Distributed R as backends, and we are working towards incorporating Spark. In addition, we have released two parallel algorithmskmeans.ddR and randomforest.ddR on CRAN which use the ddR API to express the parallel and distributed versions of these algorithms.
Here is a code excerpt that shows that you can run the same ddR based K-means algorithm both on R with the ‘parallel’ package, to benefit from multiple cores on a single server, and with HP Distributed R, for cluster computing. As your data becomes larger, you should see sufficient speedups over the single threaded version of the algorithm. For the full code look at the README on “ddR” GitHub page here:We will elaborate on the API and example programs in subsequent posts. The main constructs are distributed objects such as darray, dframe, dlist, and an operator, dmapply, which is really the distributed version of R’s mapply function. Since our goal was to keep the interface simple, the API intentionally mirrors R’s existing programming constructs.
library(ddR)
library(kmeans.ddR)
nInst = 2 # Change level of parallelism
useBackend(parallel,executors = nInst)
training_time <- system.time({model <- dkmeans(feature,K)})[3]
cat(“training dkmeans model on distributed data: “, training_time,”\n”)
The “useBackend” function in the fourth line of the code snippet allows the user to easily select a different backend. For example, to use the same K-means algorithm but with HP Distributed R, you just need to install distributedR and distributedR.ddr from GitHub, and then call useBackend(distributedR).
The “ddR” project is very much a work-in-progress. But you can help us in this effort:
The first release of the “ddR” package is now available on CRAN! You can install it using install.packages(“ddR”) or download the code from the GitHub repo: https://github.com/vertica/ddR. Currently, it supports the “parallel” package in R and HP Distributed R as backends, and we are working towards incorporating Spark. In addition, we have released two parallel algorithmskmeans.ddR and randomforest.ddR on CRAN which use the ddR API to express the parallel and distributed versions of these algorithms.
Here is a code excerpt that shows that you can run the same ddR based K-means algorithm both on R with the ‘parallel’ package, to benefit from multiple cores on a single server, and with HP Distributed R, for cluster computing. As your data becomes larger, you should see sufficient speedups over the single threaded version of the algorithm. For the full code look at the README on “ddR” GitHub page here:We will elaborate on the API and example programs in subsequent posts. The main constructs are distributed objects such as darray, dframe, dlist, and an operator, dmapply, which is really the distributed version of R’s mapply function. Since our goal was to keep the interface simple, the API intentionally mirrors R’s existing programming constructs.
library(ddR)
library(kmeans.ddR)
nInst = 2 # Change level of parallelism
useBackend(parallel,executors = nInst)
training_time <- system.time({model <- dkmeans(feature,K)})[3]
cat(“training dkmeans model on distributed data: “, training_time,”\n”)
The “useBackend” function in the fourth line of the code snippet allows the user to easily select a different backend. For example, to use the same K-means algorithm but with HP Distributed R, you just need to install distributedR and distributedR.ddr from GitHub, and then call useBackend(distributedR).
The “ddR” project is very much a work-in-progress. But you can help us in this effort:
Indrajit Roy, Principal Researcher, Hewlett Packard Labs
The first release of the “ddR” package is now available on CRAN! You can install it using install.packages(“ddR”) or download the code from the GitHub repo: https://github.com/vertica/ddR. Currently, it supports the “parallel” package in R and HP Distributed R as backends, and we are working towards incorporating Spark. In addition, we have released two parallel algorithmskmeans.ddR and randomforest.ddR on CRAN which use the ddR API to express the parallel and distributed versions of these algorithms.
Here is a code excerpt that shows that you can run the same ddR based K-means algorithm both on R with the ‘parallel’ package, to benefit from multiple cores on a single server, and with HP Distributed R, for cluster computing. As your data becomes larger, you should see sufficient speedups over the single threaded version of the algorithm. For the full code look at the README on “ddR” GitHub page here:We will elaborate on the API and example programs in subsequent posts. The main constructs are distributed objects such as darray, dframe, dlist, and an operator, dmapply, which is really the distributed version of R’s mapply function. Since our goal was to keep the interface simple, the API intentionally mirrors R’s existing programming constructs.
library(ddR)
library(kmeans.ddR)
nInst = 2 # Change level of parallelism
useBackend(parallel,executors = nInst)
training_time <- system.time({model <- dkmeans(feature,K)})[3]
cat(“training dkmeans model on distributed data: “, training_time,”\n”)
The “useBackend” function in the fourth line of the code snippet allows the user to easily select a different backend. For example, to use the same K-means algorithm but with HP Distributed R, you just need to install distributedR and distributedR.ddr from GitHub, and then call useBackend(distributedR).
The “ddR” project is very much a work-in-progress. But you can help us in this effort:
- Try out the “ddR” package and its related algorithms, and give us your feedback on GitHub (feel free to watch or star the project on GitHub)
- Are you a Spark enthusiast or algorithms expert? You can help us integrate ddR with Spark or contribute parallel versions of existing algorithms. Eventually it is going to benefit everyone if there are more parallel algorithms on CRAN.