
Keeping Track of an Evolving “Top N” Cutoff Threshold Value
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
In a previous post (Charts are for Reading), I noted how it was difficult to keep track of which times in an F1 qualifying session had made the cutoff time as a qualifying session evolved. The problem can be stated as follows: in the first session, with 20 drivers competing, the 15 drivers with the best ranked laptime will make it into the next session. Each driver can complete zero or more timed laps, with drivers completing laps in any order.
Finding the 15 drivers who will make the cutoff is therefore not simply a matter of ranking the best 15 laptimes at any point, because the same 5 drivers, say, may each record 3 fast laptimes, thus taking up the 15 slots that record the 15 fastest laptimes.
If we define a discrete time series with steps corresponding to each recorded laptime (from any driver), then at each time step we can find the best 15 drivers by finding each driver’s best laptime to date and ranking by those times. Conceptually, we need something like a lap chart which uses a ‘timed lap count’ rather than race lap index to keep track of the top 15 cars at any point.

At each index step, we can then find the laptime of the 15th ranked car to find the current session laptime.
In a dataframe that records laptimes in a session by driver code for each driver, along with a column that contains the current purple laptime, we can arrange the laptimes by cumulative session laptime (so the order of rows follows the order in which laptimes are recorded) and then iterate through those rows one at a time. At each step, we can summarise the best laptime recorded so far in the session for each driver.
df=arrange(df,cuml)
dfc=data.frame()
for (r in 1:nrow(df)) {
#summarise best laptime recorded so far in the session for each driver
dfcc=ddply(df[1:r,],.(qsession,code),summarise,dbest=min(stime))
#Keep track of which session we are in
session=df[r,]$qsession
#Rank the best laptimes for each driver to date in the current session
#(Really should filter by session at the start of this loop?)
dfcc=arrange(dfcc[dfcc['qsession']==session,],dbest)
#The different sessions have different cutoffs: Q1, top 15; Q2, top 10
n=cutoffvals[df[r,]$qsession]
#if we have at least as many driver best times recorded as the cutoff number
if (nrow(dfcc) >=n){
#Grab a record of the current cut-off time
#along with info about each recorded laptime
dfc=rbind(dfc,data.frame(df[r,]['qsession'],df[r,]['code'],df[r,]['cuml'],dfcc[n,]['dbest']) )
}
}
We can then plot the evolution of the cut-off time as the sessions proceed. The chart in it’s current form is still a bit hard to parse, but it’s a start…
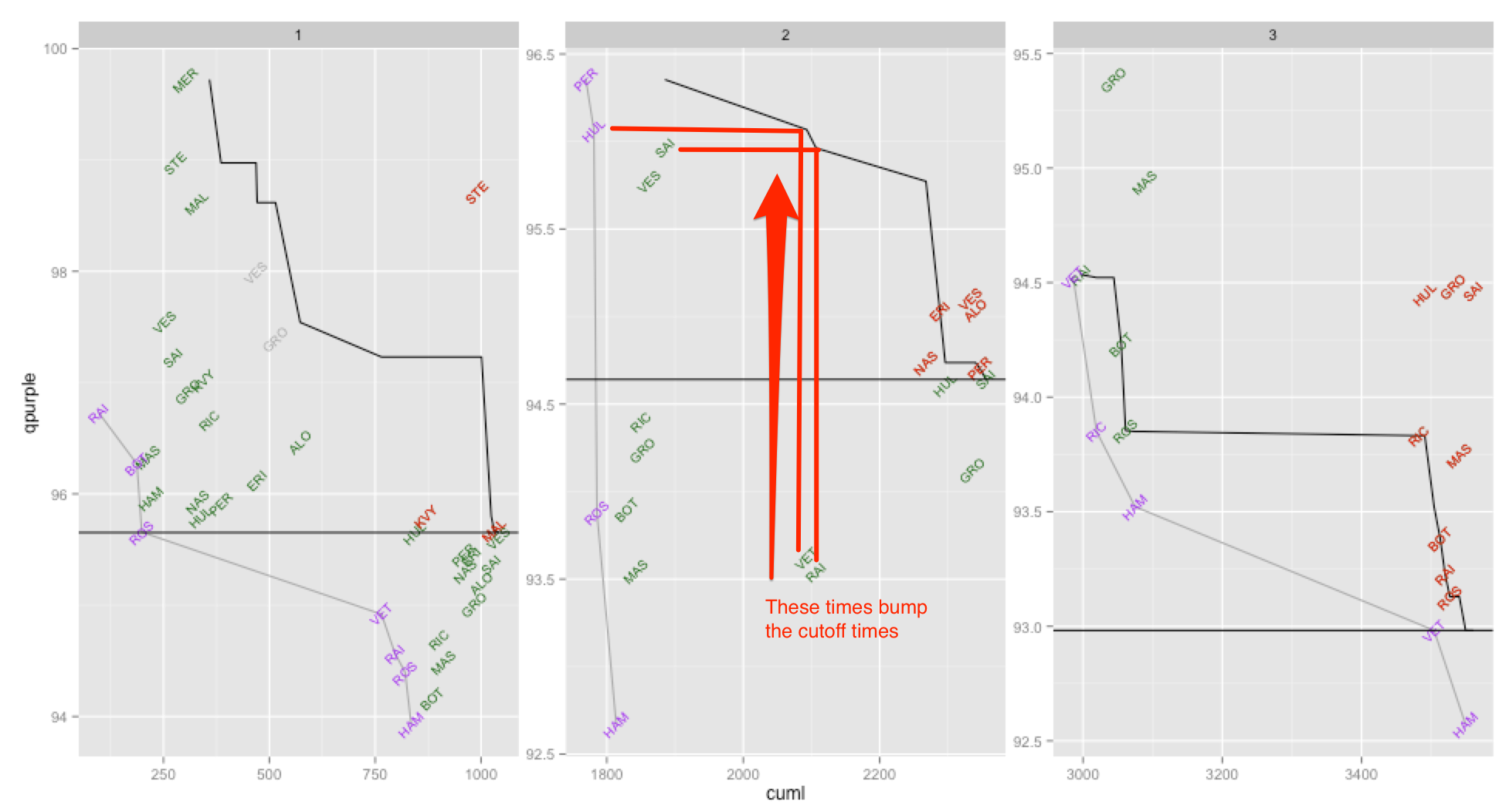
In the above sketch, the lines connect the current purple time and the current cut-off time in each session (aside from the horizontal line which represents the cut-off time at the end of the session). This gives a false impression of the evolution of the cutoff time – really, the line should be a stepped line that traces the current cut-off time horizontally until it is improved, at which point it should step vertically down. (In actual fact, the line does track horizontally as laptimes are recorded that do not change the cuttoff time, as indicated by the horizontal tracks in the Q1 panel as the grey times (laptime slower than driver’s best time in session so far) are completed.
The driver labels are coloured according to: purple – current best in session time; green – driver best in session time to date (that wasn’t also purple); red – driver’s best time in session that was outside the final cut-off time. This colouring conflates two approaches to representing information – the purple/green colours represent online algorithmic processing (if we constructed the chart in real time from laptime data as laps we completed, that’s how we’d colour the points), whereas the red colouring represents the results of offline algorithmic processing (the colour can only be calculated at the end of the session when we know the final session cutoff time). I think these mixed semantics contribute to making the chart difficult to read…
In terms of what sort of stories we might be able to pull from the chart, we see that in Q2, Hulkenberg and Sainz were only fractions of a second apart, and Perez looked like he had squeezed in to the final top 10 slot until Sainz pushed him out. To make it easier to see which times contribute to the top 10 times, we could use font weight (eg bold font) to highlight each drivers session best laptimes.
To make the chart easier to read, I think each time improvement to the cutoff time should be represented by a faint horizontal line, with a slightly darker line tracing the evolution of the cutoff time as a stepped line. This would all us to see which times were within the cutoff time at any point.
I also wonder whether it might be interesting to generate a table a bit like the race lap chart, using session timed lap count rather than race lap count, perhaps with additional colour fields to show which car recorded the time that increased the lap count index, and perhaps also where in the order that time fell if it didn’t change the order in the session so far. We could also generate online and offline differences between each laptime in the session and the current cutoff time (online algorithm) as well as the final overall session cutoff time (offline algorithm).
[As and when I get this chart sorted, it will appear in an update to the Wrangling F1 Data With R lean book.]

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.