

Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
It’s been some time now since I drafted most of my early unit contributions to the TM351 Data management and analysis course. Part of the point (for me) in drafting that material was to find out what sorts of thing we actually wanted to say and help identify the sorts of abstractions we wanted to then build a narrative around. Another part of this (for me) means exploring new ways of putting powerful “academic” ideas and concepts into meaningful, contexts; finding new ways to describe them; finding ways of using them in conjunction with other ideas; or finding new ways of using – or appropriating them – in general (which in turn may lead to new ways of thinking about them). These contexts are often process based, demonstrating how we can apply the ideas or put them to use (make them useful…) or use the ideas to support problem identification, problem decomposition and problem solving. At heart, I’m more of a creative technologist than a scientist or an engineer. (I aspire to being an artist…;-)
Someone who I think has a great take on conceptualising the data wrangling process – in part arising from his prolific tool building approach in the R language – is Hadley Wickham. His recent work for RStudio is built around an approach to working with data that he’s captured as follows (e.g. “dplyr” tutorial at useR 2014 , Pipelines for Data Analysis):


Following an often painful and laborious process of getting data into a state where you can actually start to work with it), you can then enter into an iterative process of transforming the data into various shapes and representations (often in the sense of re-presentations) that you can easily visualise or build models from. (In practice, you may have to keep redoing elements of the tidy step and then re-feed the increasingly cleaned data back into the sensemaking loop.)
Hadley’s take on this is that the visualisation phase can spring surprises on you but doesn’t scale very well, whilst the modeling phase scales but doesn’t surprise you.
To support the different phases of activity, Hadley has been instrumental in developing several software libraries for the R programming language that are particular suited to the different steps. (For the modeling, there are hundreds of community developed and often very specialised R libraries for doing all manner of weird and wonderful statistics…)


In many respects, I’ve generally found the way Hadley has presented his software libraries to be deeply pragmatic – the tools he’s developed are useful and in many senses naturalistic; they help you do the things you need to do in a way that makes practical sense. The steps they encourage you to take are natural ones, and useful ones. They are the sorts of tools that implement the sorts of ideas that come to mind when you’re faced with a problem and you think: this is the sort of thing I need (to be able) to do. (I can’t comment on how well implemented they are; I suspect: pretty well…)
Just as the data wrangling process diagram helps frame the sorts of things you’re likely to do into steps that make sense in a “folk computational” way (in the sense of folk computing or folk IT (also here), a computational correlate to notions of folk physics, for example), Hadley also has a handy diagram for helping us think about the process of solving problems computationally in a more general, problem solving sense:
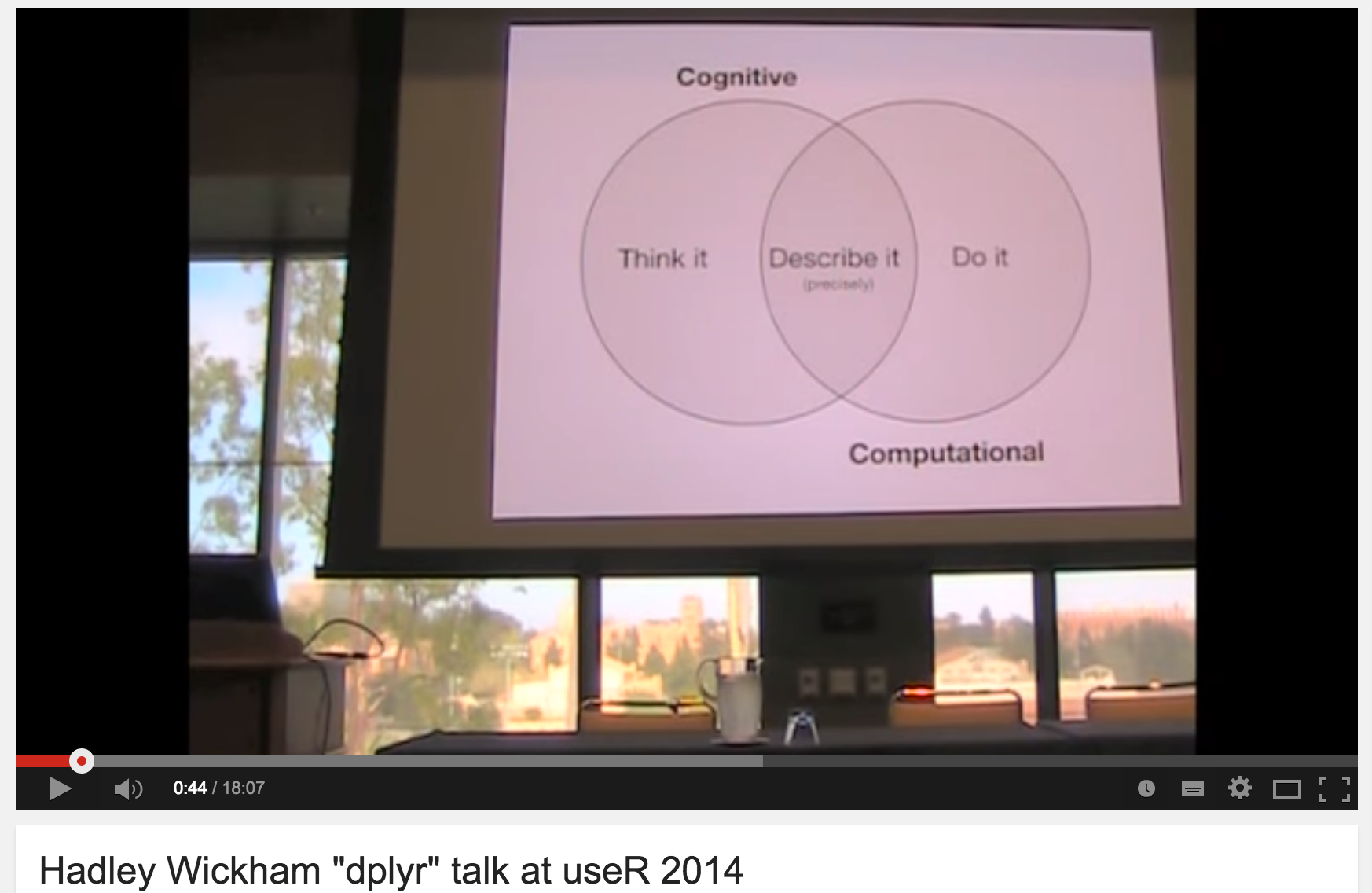
A cognitive think it step, identifying a problem, and starting to think about what sort of answer you want from it, as well as how you might start to approach it; a describe it step, where you describe precisely what it is you want to do (the sort of step where you might start scribbling pseudo-code, for example); and the computational do it step where the computational grunt work is encoded in a way that allows it to actually get done by machine.
I’ve been pondering my own stance towards computing lately, particularly from my own context of someone who sees computery stuff from a more technology, tool building and tool using context, (that is, using computery things to help you do useful stuff), rather than framing it as a purer computer science or even “trad computing” take on operationalised logic, where the practical why is often ignored.
So I think this is how I read Hadley’s diagram…

Figuring out what the hell it is you want to do (imagining, the what for a particular why), figuring out how to do it (precisely; the programming step; the how); hacking that idea into a form that lets a machine actually do it for you (the coding step; the step where you express the idea in a weird incantation where every syllable has to be the right syllable; and from which the magic happens).
One of the nice things about Hadley’s approach to supporting practical spell casting (?!) is that transformation or operational steps his libraries implement are often based around naturalistic verbs. They sort of do what they say on the tin. For example, in the dplyr toolkit, there are the following verbs:

These sort of map onto elements (often similarly named) familiar to anyone who has used SQL, but in a friendlier way. (They don’t SHOUT AT YOU for a start.) It almost feels as if they have been designed as articulations of the ideas that come to mind when you are trying to describe (precisely) what it is you actually want to do to a dataset when working on a particular problem.
In a similar way, the ggvis library (the interactive chart reinvention of Hadley’s ggplot2 library) builds on the idea of Leland Wilkinson’s “The Grammar of Graphics” and provides a way of summoning charts from data in an incremental way, as well as a functionally and grammatically coherent way. The words the libraries use encourage you to articulate the steps you think you need to take to solve a problem – and then, as if by magic, they take those steps for you.
If programming is the meditative state you need to get into to cast a computery-thing spell, and coding is the language of magic, things like dplyr help us cast spells in the vernacular.


R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.