
Importance sampling schemes for evidence approximation in mixture models
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.
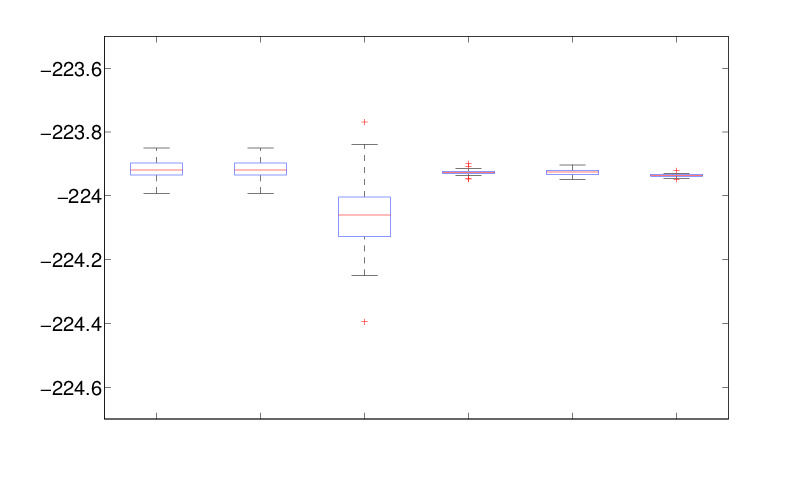 Jeong Eun (Kate) Lee and I completed this paper, “Importance sampling schemes for evidence approximation in mixture models“, now posted on arXiv. (With the customary one-day lag for posting, making me bemoan the days of yore when arXiv would give a definitive arXiv number at the time of submission.) Kate came twice to Paris in the past years to work with me on this evaluation of Chib’s original marginal likelihood estimate (also called the candidate formula by Julian Besag). And on the improvement proposed by Berkhof, van Mechelen, and Gelman (2003), based on averaging over all permutations, idea that we rediscovered in an earlier paper with Jean-Michel Marin. (And that Andrew seemed to have completely forgotten. Despite being the very first one to publish [in English] a paper on a Gibbs sampler for mixtures.) Given that this averaging can get quite costly, we propose a preliminary step to reduce the number of relevant permutations to be considered in the averaging, removing far-away modes that do not contribute to the Rao-Blackwell estimate and called dual importance sampling. We also considered modelling the posterior as a product of k-component mixtures on the components, following a vague idea I had in the back of my mind for many years, but it did not help. In the above boxplot comparison of estimators, the marginal likelihood estimators are
Jeong Eun (Kate) Lee and I completed this paper, “Importance sampling schemes for evidence approximation in mixture models“, now posted on arXiv. (With the customary one-day lag for posting, making me bemoan the days of yore when arXiv would give a definitive arXiv number at the time of submission.) Kate came twice to Paris in the past years to work with me on this evaluation of Chib’s original marginal likelihood estimate (also called the candidate formula by Julian Besag). And on the improvement proposed by Berkhof, van Mechelen, and Gelman (2003), based on averaging over all permutations, idea that we rediscovered in an earlier paper with Jean-Michel Marin. (And that Andrew seemed to have completely forgotten. Despite being the very first one to publish [in English] a paper on a Gibbs sampler for mixtures.) Given that this averaging can get quite costly, we propose a preliminary step to reduce the number of relevant permutations to be considered in the averaging, removing far-away modes that do not contribute to the Rao-Blackwell estimate and called dual importance sampling. We also considered modelling the posterior as a product of k-component mixtures on the components, following a vague idea I had in the back of my mind for many years, but it did not help. In the above boxplot comparison of estimators, the marginal likelihood estimators are
- Chib’s method using T = 5000 samples with a permutation correction by multiplying by k!.
- Chib’s method (1), using T = 5000 samples which are randomly permuted.
- Importance sampling estimate (7), using the maximum likelihood estimate (MLE) of the latents as centre.
- Dual importance sampling using q in (8).
- Dual importance sampling using an approximate in (14).
- Bridge sampling (3). Here, label switching is imposed in hyperparameters.
Filed under: R, Statistics, University life Tagged: arXiv, Chib’s approximation, evidence, label switching, marginal likelihood, mixture estimation, Monte Carlo Statistical Methods, path sampling, permutations, subsampling

R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.