
Interactive Data Science with R in Apache Zeppelin Notebook
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.

Introduction
The objective of this blog post is to help you get started with Apache Zeppelin notebook for your R data science requirements. Zeppelin is a web-based notebook that enables interactive data analytics. You can make beautiful data-driven, interactive and collaborative documents with Scala(with Apache Spark), Python(with Apache Spark), SparkSQL, Hive, Markdown, Shell and more.
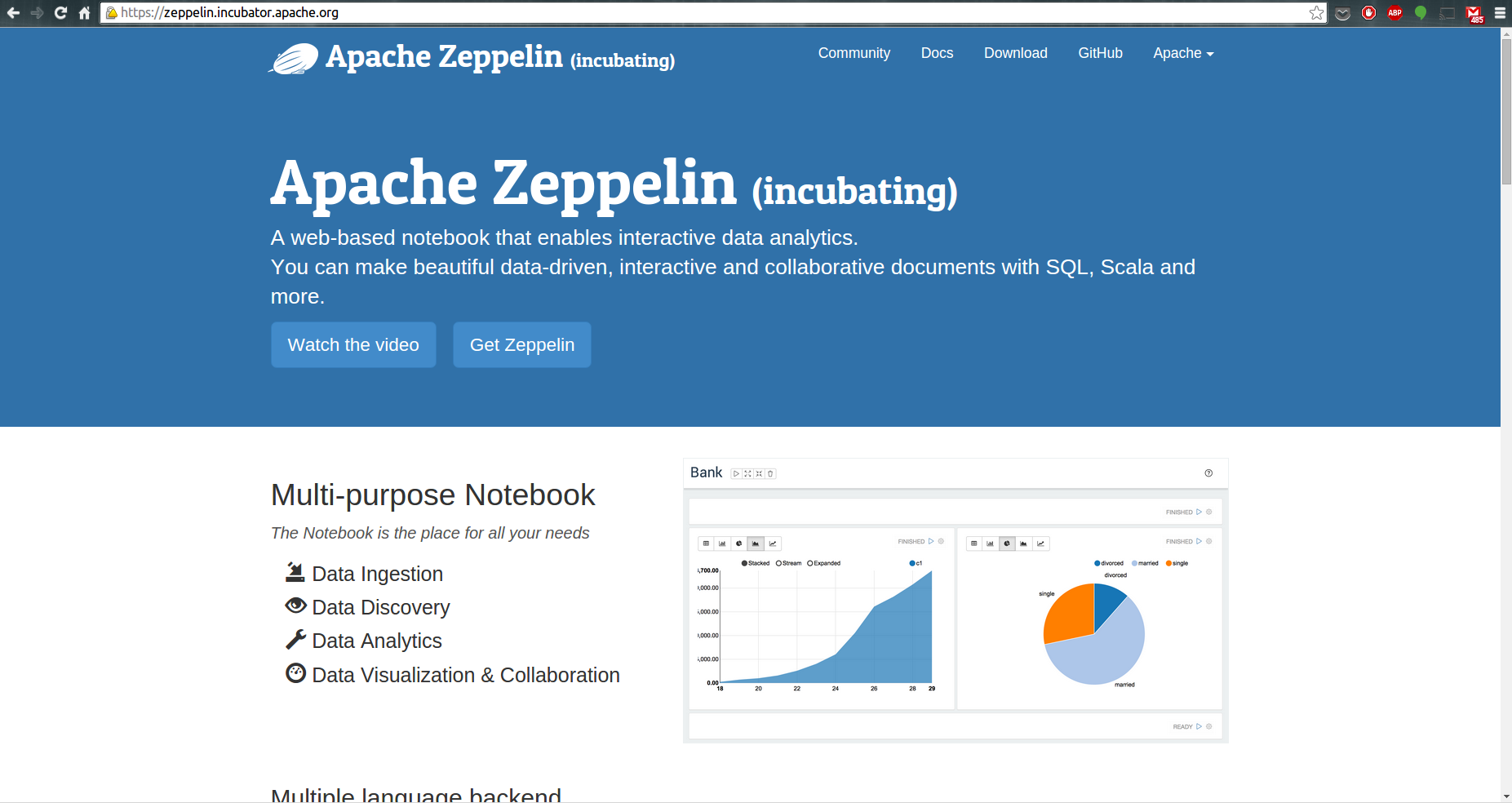
However, the latest official release, version 0.5.0, does not yet support the R programming language. Fortunately NFLabs, the company driving this open source project, pointed me this pull request that provides an R Interpreter. An Interpreter is a plug-in which enables zeppelin users to use a specific language/data-processing-backend. For example to use scala code in Zeppelin, you need a spark interpreter. So, if you are impatient like I am for R-integration into Zeppelin, this tutorial will show you how to setup Zeppelin for use with R by building from source.
Prerequisites
- We will launch Zeppelin through Bash shell on Linux. If you are using Windows OS I recommend that you install and use the Cygwin terminal (It provides functionality similar to a Linux distribution on Windows).
- Make sure Java 1.7 and Maven 3.2.x are installed on your host machine and their environment variables are set.
Build Zeppelin from Source
Step 1: Download Zeppelin Source Code
Go to this github branch and download the source code. Alternatively copy and paste this link into your web browser: https://github.com/elbamos/incubator-zeppelin/tree/rinterpreter

In my case I have downloaded and unzipped the folder onto my Desktop

Step 2: Build Zeppelin
Run the following code in your terminal to build zeppelin on your host machine in local mode. If you are installing on a cluster then add these options found in the Zeppelin documentation.
$ cd Desktop/Apache/incubator-zeppelin-rinterpreter
$ mvn clean package -DskipTests

This will take around 6 minutes to build zeppelin, Spark and all interpreters including R, Markdown, Hive, Shell, and others. (as shown in the image below).

Step 3: Start Zeppelin
Run the following command to start zeppelin.
$ ./bin/zeppelin-daemon.sh start

Go to localhost on your web browser and listen on port 8080. (i.e. http://localhost:8080). At this point you are ready to start creating interactive notebooks with code and graphs in Zeppelin.

Interactive Data Science
Step 1: Create a Notebook
Click the dropdown arrow next to the “Notebook” page and click “Create new note”.

Give your notebook a name or you can use the assigned default name. I named mine “Base R in Apache Zeppelin”.

Step 2: Start your Analysis
To use R, use the “%spark.r” or “%spark.knitr” tags as shown in the images below. First let’s use markdown to write some instruction text.

Now let’s install some packages that we may need for our analysis.

Now let’s read in our data set. We shall use the “flights” dataset which shows flights departing New York in 2013.

Now let’s do some data manipulation using dplyr (with the pipe operator)

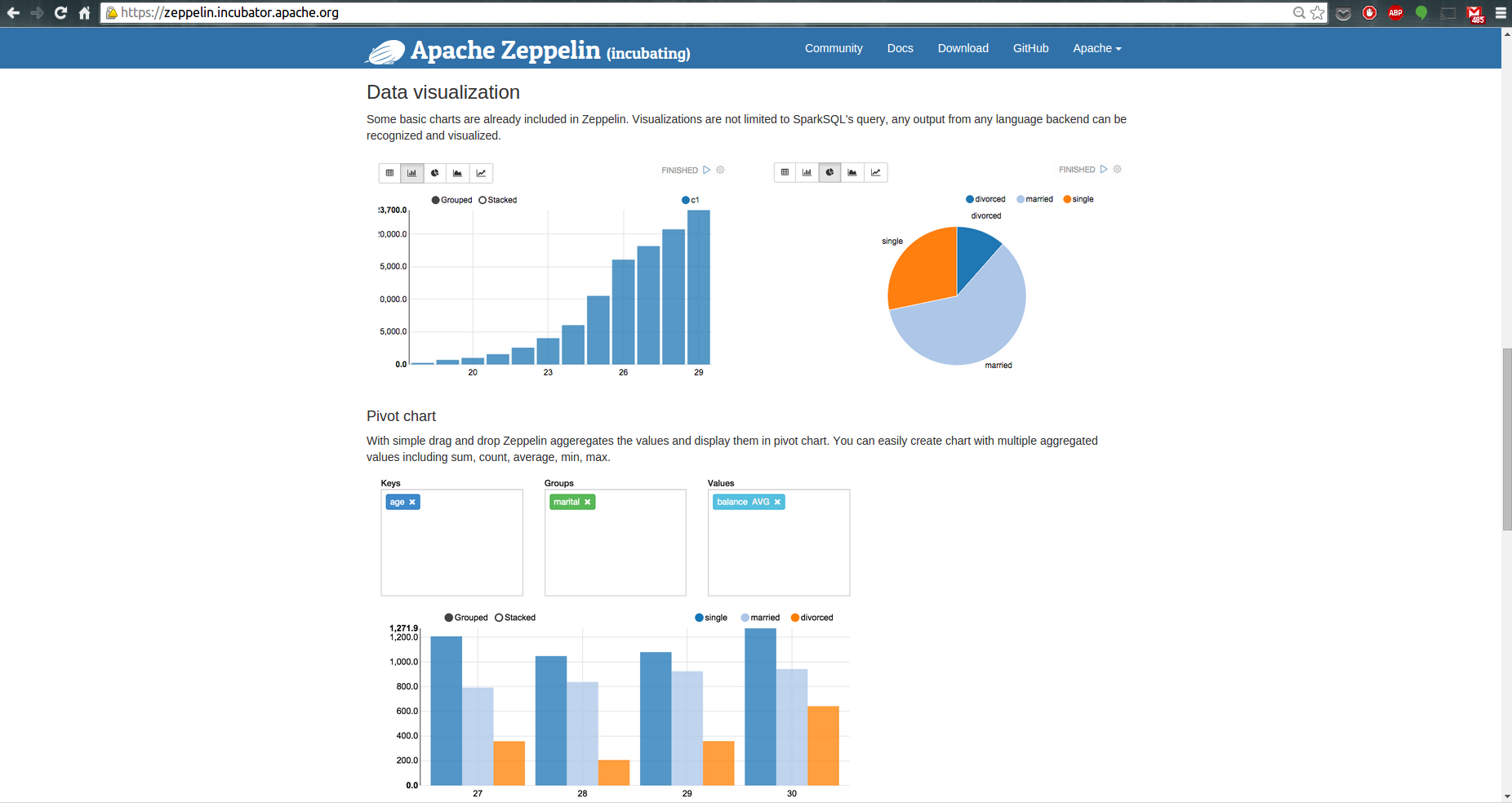
You can also use bar graphs and pie charts to visualize some descriptive statistics from your data.

Now let’s do some data exploration with ggplot2

Now let’s do some statistical machine learning using the caret package.


How about creating some maps.

Final Remarks
Zeppelin allows you to create interactive documents with beautiful graphs using multiple programming languages. The objective of this post was to help you setup Zeppelin for use with the R programming language. Hopefully the Project Management Committees (PMC) of this wonderful open source project can release the next version with an R interpreter. It will surely make it easier to launch Zeppelin faster without having to build from source.
Also it’s worth mentioning that there is another R interpreter for Zeppelin produced by the folks at Data Layer. You can find instructions on how to use it here: https://github.com/datalayer/zeppelin-R-interpreter.
Try out both interpreters and share your experiences in the comments section below.
Moving Ahead
As a follow-up to this post, We shall see how to use Apache Spark (especially SparkR) within Zeppelin in the next blog post.
Filed under: Apache Spark, Data Science, Machine Learning, R, SparkR, Zeppelin Tagged: Data Science, R, Zeppelin







R-bloggers.com offers daily e-mail updates about R news and tutorials about learning R and many other topics. Click here if you're looking to post or find an R/data-science job.
Want to share your content on R-bloggers? click here if you have a blog, or here if you don't.